Poster: Flexible Scheduling of Network and Computing Resources for Distributed AI Tasks

0

Sign in to get full access
Overview
- This paper presents a flexible scheduling system for managing network and computing resources in distributed AI tasks.
- The system aims to optimize resource allocation and task scheduling to improve the efficiency and performance of distributed AI workloads.
- The authors describe an experimental framework for evaluating the proposed scheduling approach and present results demonstrating its effectiveness.
Plain English Explanation
In modern AI systems, tasks are often distributed across multiple computers or devices to speed up processing and handle large-scale workloads. However, efficiently managing the network and computing resources needed for these distributed AI tasks can be challenging. The paper introduces a flexible scheduling system that aims to address this problem.
The key idea is to dynamically allocate and schedule the available network and computing resources to the various AI tasks in a way that optimizes overall performance. This might involve, for example, prioritizing certain tasks, shifting resources between machines, or adjusting the network bandwidth used by different components.
The authors have designed an experimental framework to test their scheduling approach. This allows them to simulate different distributed AI workloads and evaluate how well the scheduling system can manage the available resources. The results presented in the paper suggest that the proposed scheduling system can indeed improve the efficiency and performance of distributed AI tasks compared to more static resource allocation approaches.
Technical Explanation
The paper describes a flexible scheduling system for managing network and computing resources in the context of distributed AI tasks. The key components of the system include:
-
Resource Modeling: The system maintains a detailed model of the available network and computing resources, including factors like CPU, memory, storage, and network bandwidth.
-
Task Profiling: AI tasks are profiled to understand their resource requirements, such as the amount of CPU and memory needed, as well as their communication and data transfer needs.
-
Scheduling Algorithm: Based on the resource model and task profiles, the scheduling algorithm dynamically allocates resources and schedules the execution of tasks to optimize overall performance.
The authors have developed an experimental framework to evaluate their scheduling approach. This framework allows them to simulate different distributed AI workloads and compare the performance of their scheduling system to other resource allocation strategies.
The results presented in the paper demonstrate that the proposed scheduling system can effectively manage the available resources and improve the efficiency and performance of the distributed AI tasks. This is achieved by intelligently allocating resources and scheduling tasks in a way that minimizes bottlenecks and maximizes the utilization of the available network and computing infrastructure.
Critical Analysis
The paper provides a comprehensive and well-designed solution for managing network and computing resources in the context of distributed AI tasks. The experimental framework and evaluation approach are robust, and the results presented are convincing.
However, the paper does not discuss potential limitations or areas for further research. For example, it would be interesting to understand how the scheduling system might perform under more dynamic or unpredictable conditions, such as sudden changes in resource availability or unexpected task arrivals.
Additionally, the paper could have explored the trade-offs between different optimization objectives, such as minimizing latency, maximizing throughput, or balancing resource utilization. These considerations may be important in real-world deployments, where the priorities and requirements of the AI system may vary.
Conclusion
The paper presents a flexible scheduling system for managing network and computing resources in distributed AI tasks. The proposed approach demonstrates the ability to optimize resource allocation and task scheduling, leading to improved efficiency and performance of the distributed AI workloads.
The experimental framework and evaluation results provide a solid foundation for this research, and the underlying concepts and techniques could be valuable for the broader community working on resource management and scheduling for large-scale distributed AI systems.
While the paper does not address potential limitations or areas for further research, the core ideas and the demonstrated effectiveness of the scheduling system are significant contributions to the field of distributed AI resource management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Poster: Flexible Scheduling of Network and Computing Resources for Distributed AI Tasks
Ruikun Wang, Jiawei Zhang, Qiaolun Zhang, Bojun Zhang, Zhiqun Gu, Aryanaz Attarpour, Yuefeng Ji, Massimo Tornatore
Many emerging Artificial Intelligence (AI) applications require on-demand provisioning of large-scale computing, which can only be enabled by leveraging distributed computing services interconnected through networking. To address such increasing demand for networking to serve AI tasks, we investigate new scheduling strategies to improve communication efficiency and test them on a programmable testbed. We also show relevant challenges and research directions.
Read more7/9/2024

0
Resource Allocation and Workload Scheduling for Large-Scale Distributed Deep Learning: A Survey
Feng Liang, Zhen Zhang, Haifeng Lu, Chengming Li, Victor C. M. Leung, Yanyi Guo, Xiping Hu
With rapidly increasing distributed deep learning workloads in large-scale data centers, efficient distributed deep learning framework strategies for resource allocation and workload scheduling have become the key to high-performance deep learning. The large-scale environment with large volumes of datasets, models, and computational and communication resources raises various unique challenges for resource allocation and workload scheduling in distributed deep learning, such as scheduling complexity, resource and workload heterogeneity, and fault tolerance. To uncover these challenges and corresponding solutions, this survey reviews the literature, mainly from 2019 to 2024, on efficient resource allocation and workload scheduling strategies for large-scale distributed DL. We explore these strategies by focusing on various resource types, scheduling granularity levels, and performance goals during distributed training and inference processes. We highlight critical challenges for each topic and discuss key insights of existing technologies. To illustrate practical large-scale resource allocation and workload scheduling in real distributed deep learning scenarios, we use a case study of training large language models. This survey aims to encourage computer science, artificial intelligence, and communications researchers to understand recent advances and explore future research directions for efficient framework strategies for large-scale distributed deep learning.
Read more6/13/2024
👁️
0
Scheduling of Distributed Applications on the Computing Continuum: A Survey
Narges Mehran, Dragi Kimovski, Hermann Hellwagner, Dumitru Roman, Ahmet Soylu, Radu Prodan
The demand for distributed applications has significantly increased over the past decade, with improvements in machine learning techniques fueling this growth. These applications predominantly utilize Cloud data centers for high-performance computing and Fog and Edge devices for low-latency communication for small-size machine learning model training and inference. The challenge of executing applications with different requirements on heterogeneous devices requires effective methods for solving NP-hard resource allocation and application scheduling problems. The state-of-the-art techniques primarily investigate conflicting objectives, such as the completion time, energy consumption, and economic cost of application execution on the Cloud, Fog, and Edge computing infrastructure. Therefore, in this work, we review these research works considering their objectives, methods, and evaluation tools. Based on the review, we provide a discussion on the scheduling methods in the Computing Continuum.
Read more5/2/2024
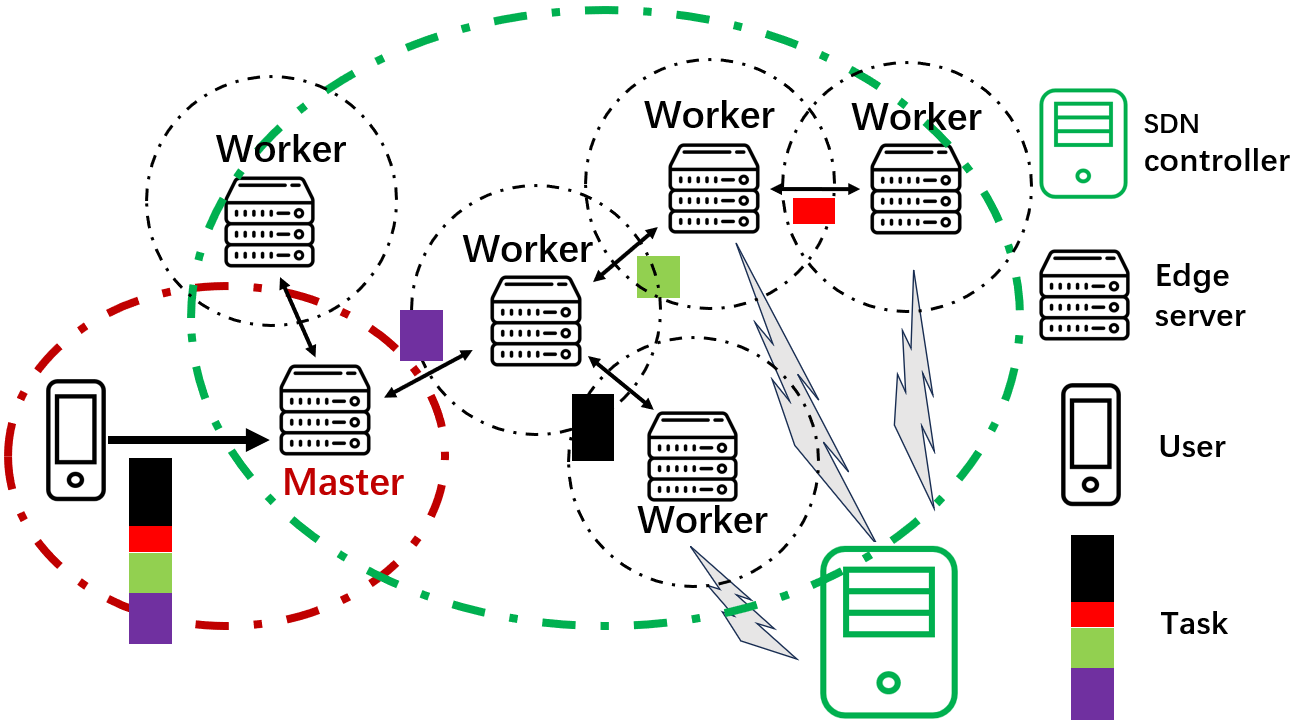
0
Joint Task Allocation and Scheduling for Multi-Hop Distributed Computing
Ke Ma, Junfei Xie
The rise of the Internet of Things and edge computing has shifted computing resources closer to end-users, benefiting numerous delay-sensitive, computation-intensive applications. To speed up computation, distributed computing is a promising technique that allows parallel execution of tasks across multiple compute nodes. However, current research predominantly revolves around the master-worker paradigm, limiting resource sharing within one-hop neighborhoods. This limitation can render distributed computing ineffective in scenarios with limited nearby resources or constrained/dynamic connectivity. In this paper, we address this limitation by introducing a new distributed computing framework that extends resource sharing beyond one-hop neighborhoods through exploring layered network structures and multi-hop routing. Our framework involves transforming the network graph into a sink tree and formulating a joint optimization problem based on the layered tree structure for task allocation and scheduling. To solve this problem, we propose two exact methods that find optimal solutions and three heuristic strategies to improve efficiency and scalability. The performances of these methods are analyzed and evaluated through theoretical analyses and comprehensive simulation studies. The results demonstrate their promising performances over the traditional distributed computing and computation offloading strategies.
Read more7/2/2024