Posterior Sampling for Continuing Environments

0
🏷️
Sign in to get full access
Overview
- Presents an extension of posterior sampling for reinforcement learning (PSRL) called continuing PSRL
- Designed for a continuous agent-environment interface and scalable to complex environments
- Maintains a plausible model of the environment and follows a policy that maximizes expected discounted return in that model
- Periodically replaces the model with a sample from the posterior distribution over environments
- Establishes a bound on Bayesian regret that depends on the environment size, action space, and a parameter related to reward estimation
Plain English Explanation
Reinforcement learning is a way for agents to learn how to interact with their environment and maximize rewards over time. Posterior sampling for reinforcement learning (PSRL) is a specific approach that maintains a model of the environment and uses that to guide its decision-making.
The paper introduces an extension of PSRL called "continuing PSRL" that is better suited for ongoing, real-world interactions between an agent and its environment. Instead of periodically restarting the learning process, continuing PSRL maintains a probability distribution over possible models of the environment. At each time step, it either follows the policy that maximizes rewards in the current model, or it replaces the model with a new sample from the distribution.
This approach has several benefits. First, it can scale to more complex environments, as the agent doesn't have to restart learning from scratch. Second, the periodic model resampling allows the agent to adapt to changes in the environment over time. Finally, the authors prove that continuing PSRL has strong theoretical guarantees on the agent's performance, even compared to an optimal strategy with full knowledge of the environment.
Technical Explanation
The core idea of continuing PSRL is to maintain a posterior distribution over possible models of the environment, and at each time step, either follow the policy that maximizes expected discounted return in the current model, or replace the model with a new sample from the posterior distribution.
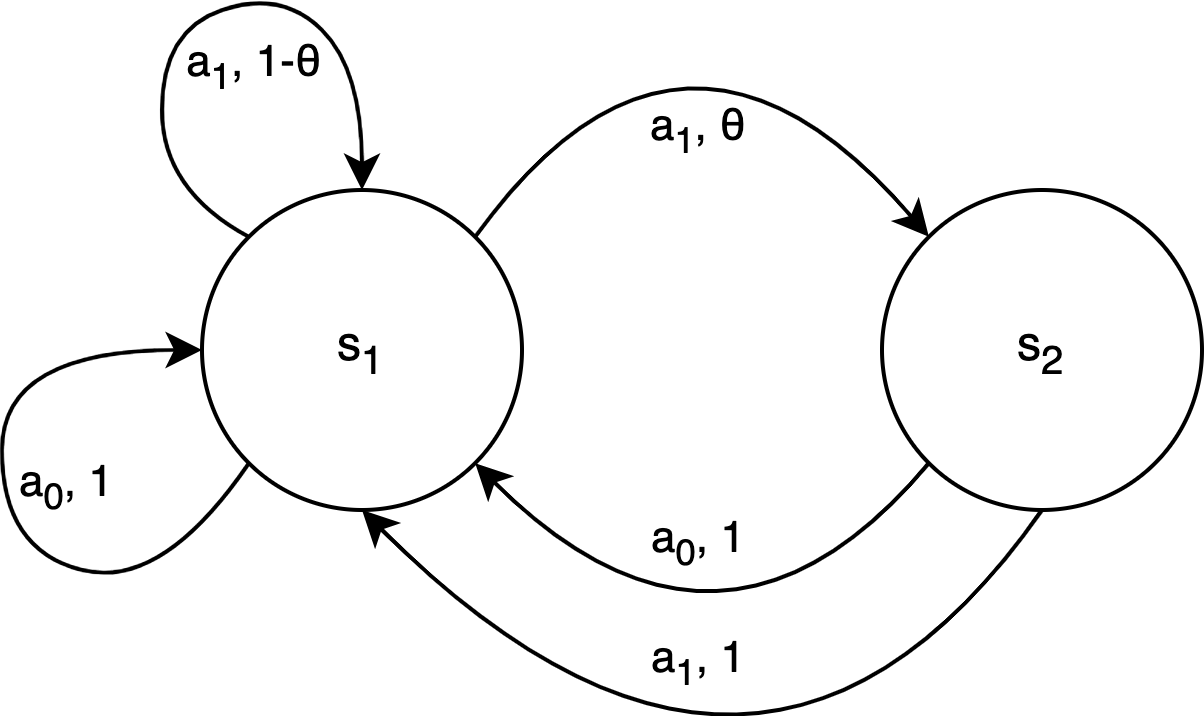
Formally, let S be the number of environment states and A be the number of actions. The agent maintains a posterior distribution over Markov decision process (MDP) models of the environment. At each time step, with probability 1-γ (where γ is the discount factor), the agent samples a new MDP model from the posterior and follows the optimal policy for that model. Otherwise, the agent follows the optimal policy for the current MDP model.
The authors show that for a suitable choice of γ that depends on the time horizon T, the Bayesian regret of continuing PSRL is bounded by Õ(τ√(SAT)), where τ is a bound on the time required to accurately estimate the average reward of any policy. This means that continuing PSRL can learn near-optimal behavior with only a small loss in performance compared to an agent with perfect knowledge of the environment.
Critical Analysis
The paper provides a strong theoretical analysis of continuing PSRL, but there are a few potential limitations and areas for further research:
-
The assumption of a known time horizon T may not hold in all real-world scenarios, where the agent may need to learn and act indefinitely. Extensions to the anytime or lifelong learning settings would be valuable.
-
The analysis assumes the agent can accurately estimate the average reward of any policy within a bounded time τ. Relaxing this assumption or providing guidance on how to estimate τ would make the approach more widely applicable.
-
The paper does not address the computational complexity of sampling from the posterior distribution or solving for the optimal policy in the current model. Efficient implementation techniques would be an important topic for future work.
-
The approach may be sensitive to the choice of prior distribution over MDPs. Further research could explore methods for adaptively updating the prior based on the agent's experience.
Despite these potential limitations, continuing PSRL represents an important step forward in developing reinforcement learning agents that can operate robustly and efficiently in complex, dynamic environments.
Conclusion
This paper introduces continuing PSRL, an extension of posterior sampling for reinforcement learning that is well-suited for continuous agent-environment interactions. By maintaining a probability distribution over possible environment models and periodically resampling the model, continuing PSRL can adapt to changes in the environment and scale to more complex settings.
The authors provide a rigorous theoretical analysis, showing that continuing PSRL can achieve near-optimal performance with only a small loss in Bayesian regret compared to an agent with perfect knowledge of the environment. This work represents an important advancement in the field of reinforcement learning, and the ideas presented could have significant implications for the development of more capable and adaptive AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Posterior Sampling for Continuing Environments
Wanqiao Xu, Shi Dong, Benjamin Van Roy
We develop an extension of posterior sampling for reinforcement learning (PSRL) that is suited for a continuing agent-environment interface and integrates naturally into agent designs that scale to complex environments. The approach, continuing PSRL, maintains a statistically plausible model of the environment and follows a policy that maximizes expected $gamma$-discounted return in that model. At each time, with probability $1-gamma$, the model is replaced by a sample from the posterior distribution over environments. For a choice of discount factor that suitably depends on the horizon $T$, we establish an $tilde{O}(tau S sqrt{A T})$ bound on the Bayesian regret, where $S$ is the number of environment states, $A$ is the number of actions, and $tau$ denotes the reward averaging time, which is a bound on the duration required to accurately estimate the average reward of any policy. Our work is the first to formalize and rigorously analyze the resampling approach with randomized exploration.
Read more8/13/2024

0
Exploiting Causal Graph Priors with Posterior Sampling for Reinforcement Learning
Mirco Mutti, Riccardo De Santi, Marcello Restelli, Alexander Marx, Giorgia Ramponi
Posterior sampling allows exploitation of prior knowledge on the environment's transition dynamics to improve the sample efficiency of reinforcement learning. The prior is typically specified as a class of parametric distributions, the design of which can be cumbersome in practice, often resulting in the choice of uninformative priors. In this work, we propose a novel posterior sampling approach in which the prior is given as a (partial) causal graph over the environment's variables. The latter is often more natural to design, such as listing known causal dependencies between biometric features in a medical treatment study. Specifically, we propose a hierarchical Bayesian procedure, called C-PSRL, simultaneously learning the full causal graph at the higher level and the parameters of the resulting factored dynamics at the lower level. We provide an analysis of the Bayesian regret of C-PSRL that explicitly connects the regret rate with the degree of prior knowledge. Our numerical evaluation conducted in illustrative domains confirms that C-PSRL strongly improves the efficiency of posterior sampling with an uninformative prior while performing close to posterior sampling with the full causal graph.
Read more4/9/2024
0
Efficient Exploration in Average-Reward Constrained Reinforcement Learning: Achieving Near-Optimal Regret With Posterior Sampling
Danil Provodin, Maurits Kaptein, Mykola Pechenizkiy
We present a new algorithm based on posterior sampling for learning in Constrained Markov Decision Processes (CMDP) in the infinite-horizon undiscounted setting. The algorithm achieves near-optimal regret bounds while being advantageous empirically compared to the existing algorithms. Our main theoretical result is a Bayesian regret bound for each cost component of $tilde{O} (DSsqrt{AT})$ for any communicating CMDP with $S$ states, $A$ actions, and diameter $D$. This regret bound matches the lower bound in order of time horizon $T$ and is the best-known regret bound for communicating CMDPs achieved by a computationally tractable algorithm. Empirical results show that our posterior sampling algorithm outperforms the existing algorithms for constrained reinforcement learning.
Read more5/30/2024
🛠️
0
Posterior Sampling-based Online Learning for Episodic POMDPs
Dengwang Tang, Dongze Ye, Rahul Jain, Ashutosh Nayyar, Pierluigi Nuzzo
Learning in POMDPs is known to be significantly harder than MDPs. In this paper, we consider the online learning problem for episodic POMDPs with unknown transition and observation models. We propose a Posterior Sampling-based reinforcement learning algorithm for POMDPs (PS4POMDPs), which is much simpler and more implementable compared to state-of-the-art optimism-based online learning algorithms for POMDPs. We show that the Bayesian regret of the proposed algorithm scales as the square root of the number of episodes, matching the lower bound, and is polynomial in the other parameters. In a general setting, its regret scales exponentially in the horizon length $H$, and we show that this is inevitable by providing a lower bound. However, when the POMDP is undercomplete and weakly revealing (a common assumption in the recent literature), we establish a polynomial Bayesian regret bound. We finally propose a posterior sampling algorithm for multi-agent POMDPs, and show it too has sublinear regret.
Read more5/27/2024