POTLoc: Pseudo-Label Oriented Transformer for Point-Supervised Temporal Action Localization

0
🌀
Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
POTLoc: Pseudo-Label Oriented Transformer for Point-Supervised Temporal Action Localization
Elahe Vahdani, Yingli Tian
This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a Pseudo-label Oriented Transformer for weakly-supervised Action Localization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of `pseudo-labels' to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS'14 and ActivityNet-v1.2 datasets.
Read more6/7/2024

0
Towards Adaptive Pseudo-label Learning for Semi-Supervised Temporal Action Localization
Feixiang Zhou, Bryan Williams, Hossein Rahmani
Alleviating noisy pseudo labels remains a key challenge in Semi-Supervised Temporal Action Localization (SS-TAL). Existing methods often filter pseudo labels based on strict conditions, but they typically assess classification and localization quality separately, leading to suboptimal pseudo-label ranking and selection. In particular, there might be inaccurate pseudo labels within selected positives, alongside reliable counterparts erroneously assigned to negatives. To tackle these problems, we propose a novel Adaptive Pseudo-label Learning (APL) framework to facilitate better pseudo-label selection. Specifically, to improve the ranking quality, Adaptive Label Quality Assessment (ALQA) is proposed to jointly learn classification confidence and localization reliability, followed by dynamically selecting pseudo labels based on the joint score. Additionally, we propose an Instance-level Consistency Discriminator (ICD) for eliminating ambiguous positives and mining potential positives simultaneously based on inter-instance intrinsic consistency, thereby leading to a more precise selection. We further introduce a general unsupervised Action-aware Contrastive Pre-training (ACP) to enhance the discrimination both within actions and between actions and backgrounds, which benefits SS-TAL. Extensive experiments on THUMOS14 and ActivityNet v1.3 demonstrate that our method achieves state-of-the-art performance under various semi-supervised settings.
Read more7/26/2024
0
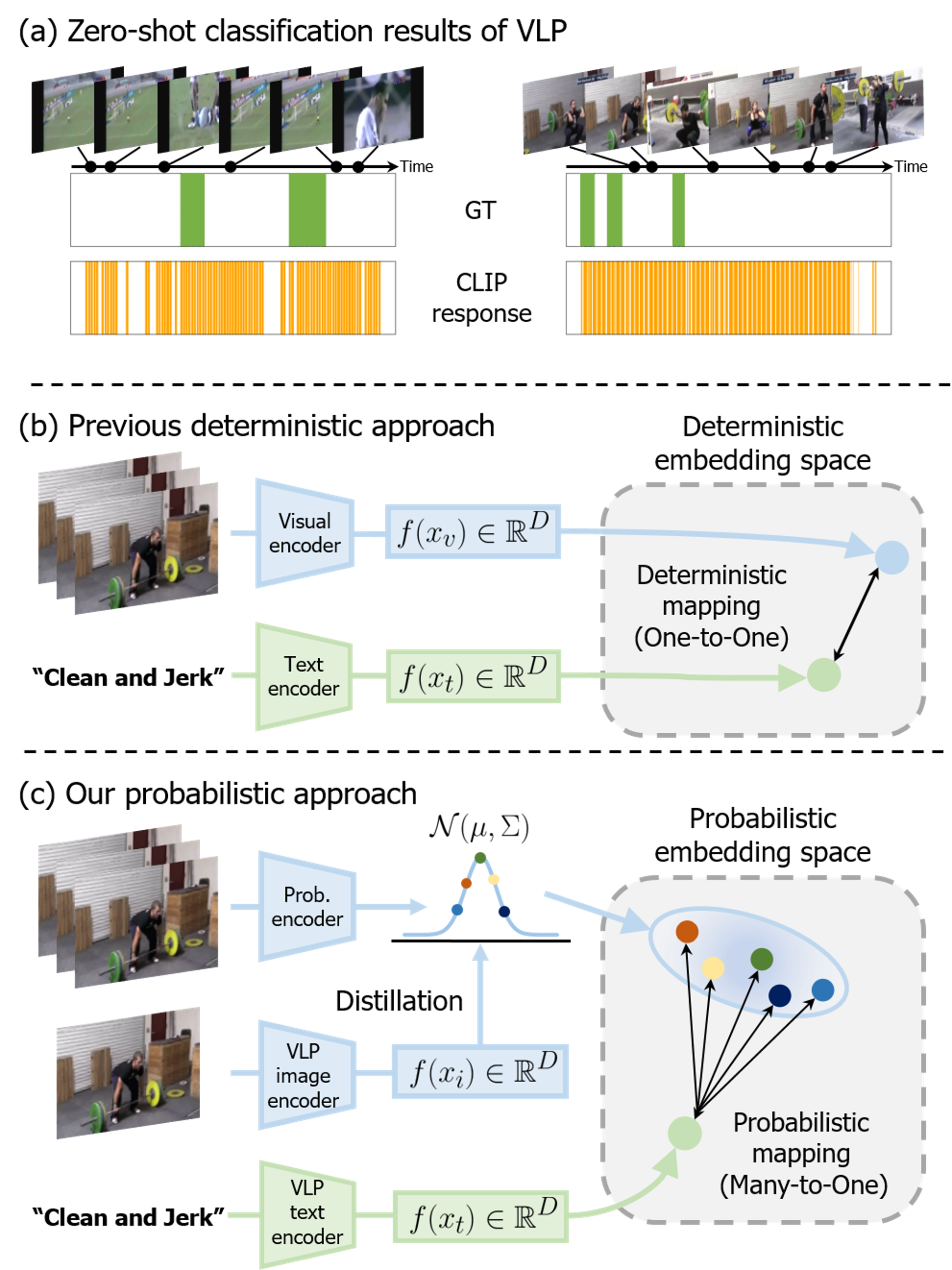
Probabilistic Vision-Language Representation for Weakly Supervised Temporal Action Localization
Geuntaek Lim, Hyunwoo Kim, Joonsoo Kim, Yukyung Choi
Weakly supervised temporal action localization (WTAL) aims to detect action instances in untrimmed videos using only video-level annotations. Since many existing works optimize WTAL models based on action classification labels, they encounter the task discrepancy problem (i.e., localization-by-classification). To tackle this issue, recent studies have attempted to utilize action category names as auxiliary semantic knowledge through vision-language pre-training (VLP). However, there are still areas where existing research falls short. Previous approaches primarily focused on leveraging textual information from language models but overlooked the alignment of dynamic human action and VLP knowledge in a joint space. Furthermore, the deterministic representation employed in previous studies struggles to capture fine-grained human motions. To address these problems, we propose a novel framework that aligns human action knowledge and VLP knowledge in a probabilistic embedding space. Moreover, we propose intra- and inter-distribution contrastive learning to enhance the probabilistic embedding space based on statistical similarities. Extensive experiments and ablation studies reveal that our method significantly outperforms all previous state-of-the-art methods. Code is available at https://github.com/sejong-rcv/PVLR.
Read more8/13/2024

0
Temporal Divide-and-Conquer Anomaly Actions Localization in Semi-Supervised Videos with Hierarchical Transformer
Nada Osman, Marwan Torki
Anomaly action detection and localization play an essential role in security and advanced surveillance systems. However, due to the tremendous amount of surveillance videos, most of the available data for the task is unlabeled or semi-labeled with the video class known, but the location of the anomaly event is unknown. In this work, we target anomaly localization in semi-supervised videos. While the mainstream direction in addressing this task is focused on segment-level multi-instance learning and the generation of pseudo labels, we aim to explore a promising yet unfulfilled direction to solve the problem by learning the temporal relations within videos in order to locate anomaly events. To this end, we propose a hierarchical transformer model designed to evaluate the significance of observed actions in anomalous videos with a divide-and-conquer strategy along the temporal axis. Our approach segments a parent video hierarchically into multiple temporal children instances and measures the influence of the children nodes in classifying the abnormality of the parent video. Evaluating our model on two well-known anomaly detection datasets, UCF-crime and ShanghaiTech, proves its ability to interpret the observed actions within videos and localize the anomalous ones. Our proposed approach outperforms previous works relying on segment-level multiple-instance learning approaches while reaching a promising performance compared to the more recent pseudo-labeling-based approaches.
Read more8/27/2024