PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation

0

Sign in to get full access
Overview
- This paper introduces PPPR (Portable Plug-in Prompt Refiner), a method for enhancing text-to-audio generation models by refining the input prompts.
- PPPR can be used as a plug-in module to improve the performance of various text-to-audio models without modifying their underlying architectures.
- The paper demonstrates PPPR's ability to outperform state-of-the-art text-to-audio models on multiple benchmarks.
Plain English Explanation
The paper presents a technique called PPPR (Portable Plug-in Prompt Refiner) that can improve the performance of text-to-audio generation models. These models are used to convert text prompts into realistic-sounding audio.
The key idea behind PPPR is that the input text prompts can be refined or improved before being fed into the text-to-audio model. This prompt refinement helps the model generate better-quality audio. Importantly, PPPR can be used as a "plug-in" module, meaning it can be easily added to existing text-to-audio models without requiring changes to their core architecture.
The paper shows that by using PPPR, the researchers were able to outperform state-of-the-art text-to-audio models on several benchmark tests. This suggests that PPPR is an effective way to enhance the capabilities of text-to-audio generation systems.
Technical Explanation
The paper proposes a prompt refinement module called PPPR (Portable Plug-in Prompt Refiner) that can be used to improve the performance of text-to-audio generation models. PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation
The key components of PPPR include:
- A prompt encoding module that converts the input text prompt into a semantic representation.
- A refinement module that analyzes the prompt representation and generates a refined version of the prompt.
- A prompt decoder that converts the refined prompt back into text format.
PPPR is designed to be a plug-in module that can be easily integrated into existing text-to-audio models without modifying their underlying architectures. This makes PPPR a portable and versatile solution for enhancing text-to-audio generation capabilities.
The paper evaluates PPPR by integrating it with several state-of-the-art text-to-audio models and testing their performance on benchmark datasets. The results show that PPPR is able to consistently improve the audio quality generated by these models, outperforming the original models on various objective and subjective metrics.
Critical Analysis
The paper presents a promising approach for improving text-to-audio generation, but there are a few potential limitations and areas for further research:
- The paper only evaluates PPPR on a limited set of text-to-audio models and datasets. It would be valuable to test PPPR's generalization to a wider range of models and tasks, including multilingual or specialized applications.
- The paper does not provide detailed analysis on the types of prompts or audio content where PPPR is most effective. Understanding the strengths and weaknesses of the prompt refinement approach could help guide future improvements.
- While PPPR is designed to be a portable plug-in, the paper does not address potential performance or integration challenges when combining PPPR with complex or computationally-intensive text-to-audio models.
- The paper does not discuss the computational overhead or latency introduced by the PPPR module, which could be an important consideration for real-time or low-resource applications.
Overall, the PPPR approach is an interesting contribution to the field of text-to-audio generation, but further research and evaluation is needed to fully understand its capabilities and limitations.
Conclusion
The PPPR (Portable Plug-in Prompt Refiner) method presented in this paper offers a promising way to enhance the performance of text-to-audio generation models. By refining the input text prompts before passing them to the audio generation model, PPPR is able to consistently improve the quality of the generated audio across multiple benchmark tests.
The key advantages of PPPR are its portability and flexibility - it can be easily integrated as a plug-in module with existing text-to-audio models without requiring modifications to their core architecture. This makes PPPR a versatile tool for improving the capabilities of a wide range of text-to-audio systems.
While further research is needed to fully understand PPPR's strengths and limitations, this work represents an important step forward in advancing the state-of-the-art in text-to-audio generation. By focusing on improving the input prompts, PPPR demonstrates the value of considering the broader system design when developing advanced AI models for tasks like speech synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation
Shuchen Shi, Ruibo Fu, Zhengqi Wen, Jianhua Tao, Tao Wang, Chunyu Qiang, Yi Lu, Xin Qi, Xuefei Liu, Yukun Liu, Yongwei Li, Zhiyong Wang, Xiaopeng Wang
Text-to-Audio (TTA) aims to generate audio that corresponds to the given text description, playing a crucial role in media production. The text descriptions in TTA datasets lack rich variations and diversity, resulting in a drop in TTA model performance when faced with complex text. To address this issue, we propose a method called Portable Plug-in Prompt Refiner, which utilizes rich knowledge about textual descriptions inherent in large language models to effectively enhance the robustness of TTA acoustic models without altering the acoustic training set. Furthermore, a Chain-of-Thought that mimics human verification is introduced to enhance the accuracy of audio descriptions, thereby improving the accuracy of generated content in practical applications. The experiments show that our method achieves a state-of-the-art Inception Score (IS) of 8.72, surpassing AudioGen, AudioLDM and Tango.
Read more6/10/2024
0
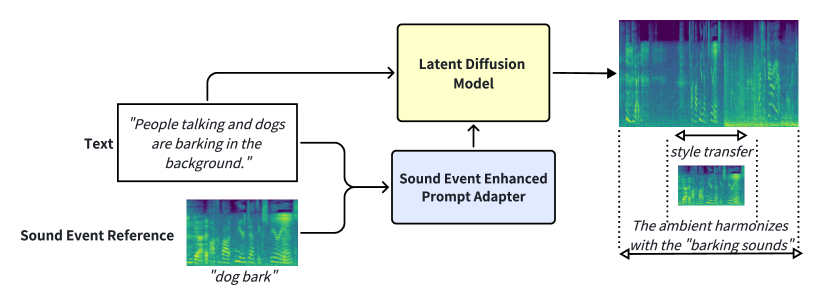
New!Text Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation
Chenxu Xiong, Ruibo Fu, Shuchen Shi, Zhengqi Wen, Jianhua Tao, Tao Wang, Chenxing Li, Chunyu Qiang, Yuankun Xie, Xin Qi, Guanjun Li, Zizheng Yang
Current mainstream audio generation methods primarily rely on simple text prompts, often failing to capture the nuanced details necessary for multi-style audio generation. To address this limitation, the Sound Event Enhanced Prompt Adapter is proposed. Unlike traditional static global style transfer, this method extracts style embedding through cross-attention between text and reference audio for adaptive style control. Adaptive layer normalization is then utilized to enhance the model's capacity to express multiple styles. Additionally, the Sound Event Reference Style Transfer Dataset (SERST) is introduced for the proposed target style audio generation task, enabling dual-prompt audio generation using both text and audio references. Experimental results demonstrate the robustness of the model, achieving state-of-the-art Fr'echet Distance of 26.94 and KL Divergence of 1.82, surpassing Tango, AudioLDM, and AudioGen. Furthermore, the generated audio shows high similarity to its corresponding audio reference. The demo, code, and dataset are publicly available.
Read more9/17/2024

0
Audio Prompt Adapter: Unleashing Music Editing Abilities for Text-to-Music with Lightweight Finetuning
Fang-Duo Tsai, Shih-Lun Wu, Haven Kim, Bo-Yu Chen, Hao-Chung Cheng, Yi-Hsuan Yang
Text-to-music models allow users to generate nearly realistic musical audio with textual commands. However, editing music audios remains challenging due to the conflicting desiderata of performing fine-grained alterations on the audio while maintaining a simple user interface. To address this challenge, we propose Audio Prompt Adapter (or AP-Adapter), a lightweight addition to pretrained text-to-music models. We utilize AudioMAE to extract features from the input audio, and construct attention-based adapters to feedthese features into the internal layers of AudioLDM2, a diffusion-based text-to-music model. With 22M trainable parameters, AP-Adapter empowers users to harness both global (e.g., genre and timbre) and local (e.g., melody) aspects of music, using the original audio and a short text as inputs. Through objective and subjective studies, we evaluate AP-Adapter on three tasks: timbre transfer, genre transfer, and accompaniment generation. Additionally, we demonstrate its effectiveness on out-of-domain audios containing unseen instruments during training.
Read more7/25/2024

0
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, Soujanya Poria
Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
Read more7/18/2024