Text Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation

0
Sign in to get full access
Overview
- This paper explores a new approach to audio generation using diffusion models, which are a type of generative AI model.
- The key idea is to enhance the text prompts used to guide the audio generation process with additional sound event information.
- This "sound event enhanced prompt adapter" is shown to improve the quality and ability to match target audio styles, compared to using just text prompts alone.
Plain English Explanation
The researchers behind this paper recognized that text prompts are not enough to fully control the audio generation process. While text can describe the overall concept or scene, it often fails to capture the nuanced details of the desired audio, such as specific sound effects or the characteristic qualities of certain instruments.
To address this, the researchers developed a technique called a sound event enhanced prompt adapter. This allows the text prompt to be augmented with additional information about the types of sounds that should be included, their timing, and other relevant details. By incorporating this extra "sound event" data, the diffusion model is better able to generate audio that matches the target style and creative vision.
The results show that this approach leads to improved audio quality and style transfer compared to using text prompts alone. Users are able to more precisely control the characteristics of the generated audio, unlocking new possibilities for creative audio editing and other applications.
Technical Explanation
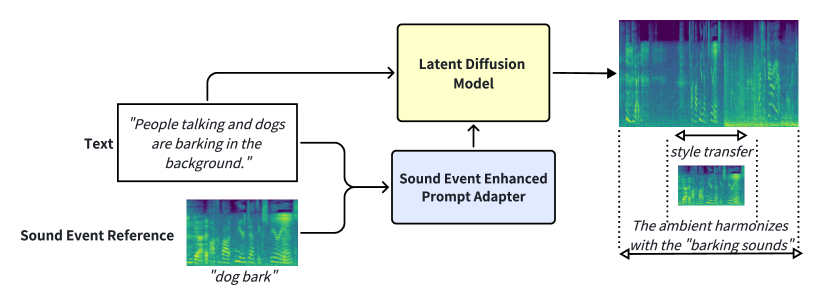
The core of this work is a diffusion model architecture that takes in both a text prompt and a sound event prompt as input. The text prompt describes the overall concept or scene, while the sound event prompt provides additional details about the specific audio elements that should be present.
The sound event prompt is represented as a sequence of tokens, each describing a particular sound (e.g. "dog barking", "piano note", "thunder"). The relative timing of these sound events is also encoded. This combined prompt is then fed into the diffusion model, which generates the target audio waveform.
The researchers thoroughly evaluate this approach through extensive experiments, comparing it to text-only prompts as well as other multi-modal techniques. The results demonstrate significant improvements in audio quality, style matching, and controllability when leveraging the sound event enhanced prompts.
Critical Analysis
A key strength of this research is the recognition that text alone is often insufficient for precise control over generated audio. The sound event enhanced prompt adapter represents an intuitive and effective solution to this problem, grounded in solid technical implementation.
That said, the paper does not extensively explore the limitations or edge cases of this approach. For example, it's unclear how well the system would handle highly complex or abstract sound environments, or whether there are any biases or inconsistencies in the way different sound events are represented and interpreted.
Additionally, the researchers acknowledge that their evaluation is primarily focused on subjective human assessments of audio quality. While this is a reasonable approach, incorporating more objective, quantitative metrics could provide additional insights and help validate the claims more rigorously.
Overall, this work represents an important step forward in audio generation capabilities, and the sound event enhanced prompt adapter is a compelling technique that warrants further investigation and refinement.
Conclusion
This paper introduces a novel approach to audio generation that goes beyond text-only prompts by incorporating additional information about the desired sound events. The resulting "sound event enhanced prompt adapter" is shown to significantly improve the quality, style matching, and controllability of generated audio compared to text-only techniques.
By bridging the gap between high-level conceptual descriptions and the nuanced details of target audio, this research unlocks new possibilities for creative applications like music production, sound design, and beyond. As AI-powered audio tools continue to evolve, techniques like this will likely play a crucial role in empowering users to fully realize their creative visions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Text Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation
Chenxu Xiong, Ruibo Fu, Shuchen Shi, Zhengqi Wen, Jianhua Tao, Tao Wang, Chenxing Li, Chunyu Qiang, Yuankun Xie, Xin Qi, Guanjun Li, Zizheng Yang
Current mainstream audio generation methods primarily rely on simple text prompts, often failing to capture the nuanced details necessary for multi-style audio generation. To address this limitation, the Sound Event Enhanced Prompt Adapter is proposed. Unlike traditional static global style transfer, this method extracts style embedding through cross-attention between text and reference audio for adaptive style control. Adaptive layer normalization is then utilized to enhance the model's capacity to express multiple styles. Additionally, the Sound Event Reference Style Transfer Dataset (SERST) is introduced for the proposed target style audio generation task, enabling dual-prompt audio generation using both text and audio references. Experimental results demonstrate the robustness of the model, achieving state-of-the-art Fr'echet Distance of 26.94 and KL Divergence of 1.82, surpassing Tango, AudioLDM, and AudioGen. Furthermore, the generated audio shows high similarity to its corresponding audio reference. The demo, code, and dataset are publicly available.
Read more9/17/2024

0
Audio Prompt Adapter: Unleashing Music Editing Abilities for Text-to-Music with Lightweight Finetuning
Fang-Duo Tsai, Shih-Lun Wu, Haven Kim, Bo-Yu Chen, Hao-Chung Cheng, Yi-Hsuan Yang
Text-to-music models allow users to generate nearly realistic musical audio with textual commands. However, editing music audios remains challenging due to the conflicting desiderata of performing fine-grained alterations on the audio while maintaining a simple user interface. To address this challenge, we propose Audio Prompt Adapter (or AP-Adapter), a lightweight addition to pretrained text-to-music models. We utilize AudioMAE to extract features from the input audio, and construct attention-based adapters to feedthese features into the internal layers of AudioLDM2, a diffusion-based text-to-music model. With 22M trainable parameters, AP-Adapter empowers users to harness both global (e.g., genre and timbre) and local (e.g., melody) aspects of music, using the original audio and a short text as inputs. Through objective and subjective studies, we evaluate AP-Adapter on three tasks: timbre transfer, genre transfer, and accompaniment generation. Additionally, we demonstrate its effectiveness on out-of-domain audios containing unseen instruments during training.
Read more7/25/2024

0
PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation
Shuchen Shi, Ruibo Fu, Zhengqi Wen, Jianhua Tao, Tao Wang, Chunyu Qiang, Yi Lu, Xin Qi, Xuefei Liu, Yukun Liu, Yongwei Li, Zhiyong Wang, Xiaopeng Wang
Text-to-Audio (TTA) aims to generate audio that corresponds to the given text description, playing a crucial role in media production. The text descriptions in TTA datasets lack rich variations and diversity, resulting in a drop in TTA model performance when faced with complex text. To address this issue, we propose a method called Portable Plug-in Prompt Refiner, which utilizes rich knowledge about textual descriptions inherent in large language models to effectively enhance the robustness of TTA acoustic models without altering the acoustic training set. Furthermore, a Chain-of-Thought that mimics human verification is introduced to enhance the accuracy of audio descriptions, thereby improving the accuracy of generated content in practical applications. The experiments show that our method achieves a state-of-the-art Inception Score (IS) of 8.72, surpassing AudioGen, AudioLDM and Tango.
Read more6/10/2024
🤿
0
Audio Editing with Non-Rigid Text Prompts
Francesco Paissan, Luca Della Libera, Zhepei Wang, Mirco Ravanelli, Paris Smaragdis, Cem Subakan
In this paper, we explore audio-editing with non-rigid text edits. We show that the proposed editing pipeline is able to create audio edits that remain faithful to the input audio. We explore text prompts that perform addition, style transfer, and in-painting. We quantitatively and qualitatively show that the edits are able to obtain results which outperform Audio-LDM, a recently released text-prompted audio generation model. Qualitative inspection of the results points out that the edits given by our approach remain more faithful to the input audio in terms of keeping the original onsets and offsets of the audio events.
Read more6/13/2024