PQA: Exploring the Potential of Product Quantization in DNN Hardware Acceleration
2305.18334
0
0
⛏️
Abstract
Conventional multiply-accumulate (MAC) operations have long dominated computation time for deep neural networks (DNNs), espcially convolutional neural networks (CNNs). Recently, product quantization (PQ) has been applied to these workloads, replacing MACs with memory lookups to pre-computed dot products. To better understand the efficiency tradeoffs of product-quantized DNNs (PQ-DNNs), we create a custom hardware accelerator to parallelize and accelerate nearest-neighbor search and dot-product lookups. Additionally, we perform an empirical study to investigate the efficiency--accuracy tradeoffs of different PQ parameterizations and training methods. We identify PQ configurations that improve performance-per-area for ResNet20 by up to 3.1$times$, even when compared to a highly optimized conventional DNN accelerator, with similar improvements on two additional compact DNNs. When comparing to recent PQ solutions, we outperform prior work by $4times$ in terms of performance-per-area with a 0.6% accuracy degradation. Finally, we reduce the bitwidth of PQ operations to investigate the impact on both hardware efficiency and accuracy. With only 2-6-bit precision on three compact DNNs, we were able to maintain DNN accuracy eliminating the need for DSPs.
Get summaries of the top AI research delivered straight to your inbox:
The paper explores using product quantization (PQ) to replace multiply-accumulate (MAC) operations in deep neural networks (DNNs) with memory lookups. The authors:
-
Created a custom hardware accelerator to speed up nearest-neighbor search and dot-product lookups for product-quantized DNNs (PQ-DNNs).
-
Studied the efficiency-accuracy tradeoffs of different PQ configurations and training methods.
-
Found PQ setups that improved performance-per-area for ResNet20 by up to 3.1x compared to an optimized conventional DNN accelerator, with similar gains on two other compact DNNs.
-
Outperformed recent PQ solutions by 4x in performance-per-area with only a 0.6% accuracy drop.
-
Reduced PQ operation bitwidth to 2-6 bits on three compact DNNs while maintaining accuracy, eliminating the need for DSPs.
The work demonstrates the potential of PQ to significantly improve DNN hardware efficiency with minimal impact on accuracy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Quantization and Mapping Synergy in Hardware-Aware Deep Neural Network Accelerators
Jan Klhufek, Miroslav Safar, Vojtech Mrazek, Zdenek Vasicek, Lukas Sekanina
0
0
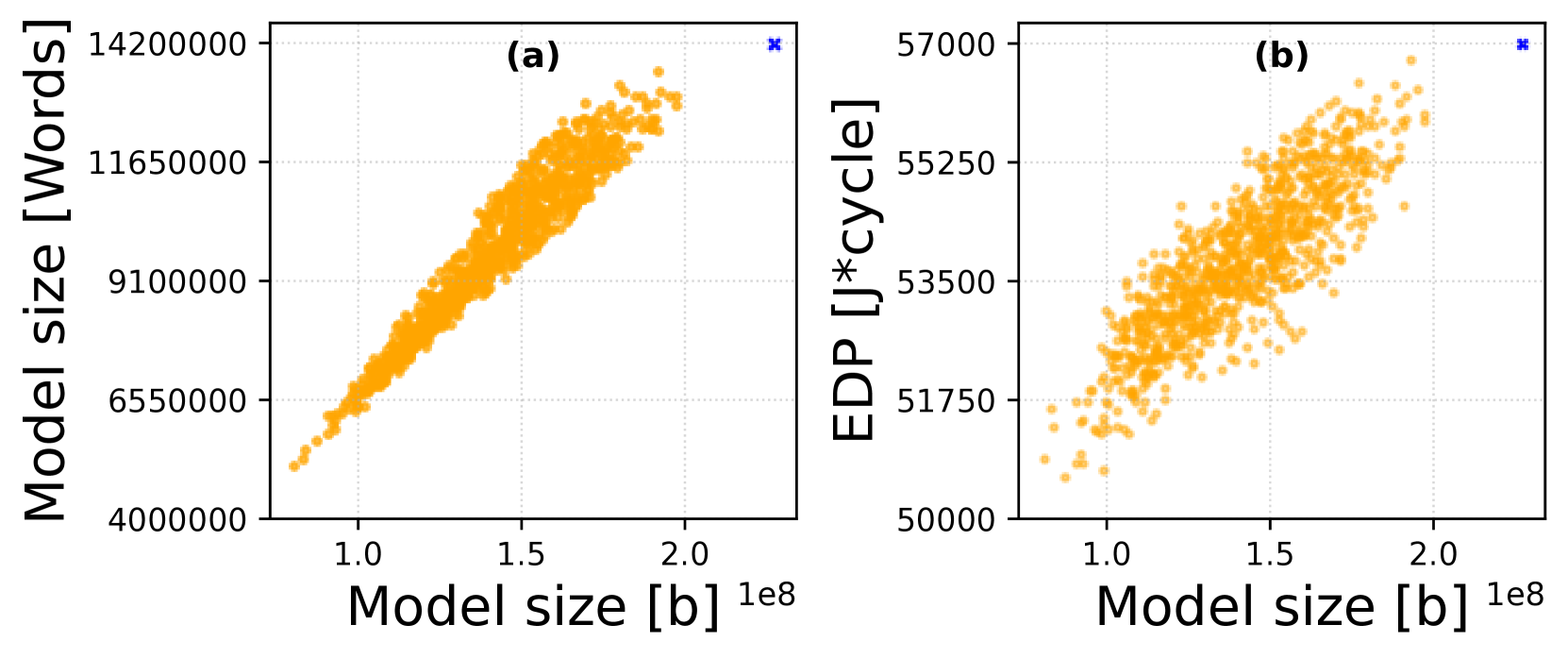
Energy efficiency and memory footprint of a convolutional neural network (CNN) implemented on a CNN inference accelerator depend on many factors, including a weight quantization strategy (i.e., data types and bit-widths) and mapping (i.e., placement and scheduling of DNN elementary operations on hardware units of the accelerator). We show that enabling rich mixed quantization schemes during the implementation can open a previously hidden space of mappings that utilize the hardware resources more effectively. CNNs utilizing quantized weights and activations and suitable mappings can significantly improve trade-offs among the accuracy, energy, and memory requirements compared to less carefully optimized CNN implementations. To find, analyze, and exploit these mappings, we: (i) extend a general-purpose state-of-the-art mapping tool (Timeloop) to support mixed quantization, which is not currently available; (ii) propose an efficient multi-objective optimization algorithm to find the most suitable bit-widths and mapping for each DNN layer executed on the accelerator; and (iii) conduct a detailed experimental evaluation to validate the proposed method. On two CNNs (MobileNetV1 and MobileNetV2) and two accelerators (Eyeriss and Simba) we show that for a given quality metric (such as the accuracy on ImageNet), energy savings are up to 37% without any accuracy drop.
4/9/2024
DNN Memory Footprint Reduction via Post-Training Intra-Layer Multi-Precision Quantization
Behnam Ghavami, Amin Kamjoo, Lesley Shannon, Steve Wilton
0
0
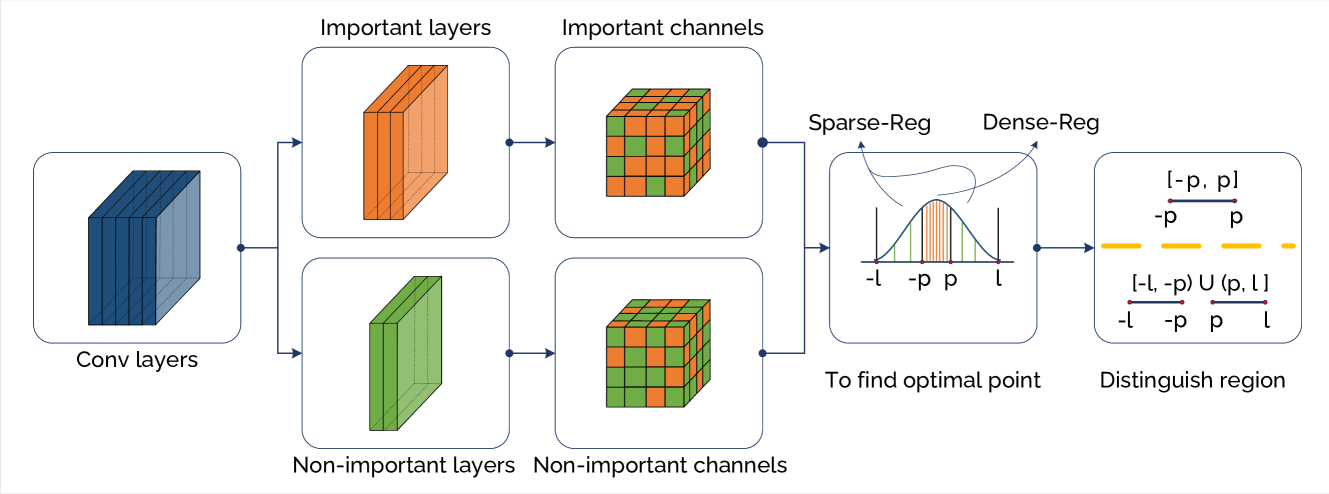
The imperative to deploy Deep Neural Network (DNN) models on resource-constrained edge devices, spurred by privacy concerns, has become increasingly apparent. To facilitate the transition from cloud to edge computing, this paper introduces a technique that effectively reduces the memory footprint of DNNs, accommodating the limitations of resource-constrained edge devices while preserving model accuracy. Our proposed technique, named Post-Training Intra-Layer Multi-Precision Quantization (PTILMPQ), employs a post-training quantization approach, eliminating the need for extensive training data. By estimating the importance of layers and channels within the network, the proposed method enables precise bit allocation throughout the quantization process. Experimental results demonstrate that PTILMPQ offers a promising solution for deploying DNNs on edge devices with restricted memory resources. For instance, in the case of ResNet50, it achieves an accuracy of 74.57% with a memory footprint of 9.5 MB, representing a 25.49% reduction compared to previous similar methods, with only a minor 1.08% decrease in accuracy.
4/5/2024
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
Chang Sun, Thea K. {AA}rrestad, Vladimir Loncar, Jennifer Ngadiuba, Maria Spiropulu
0
0
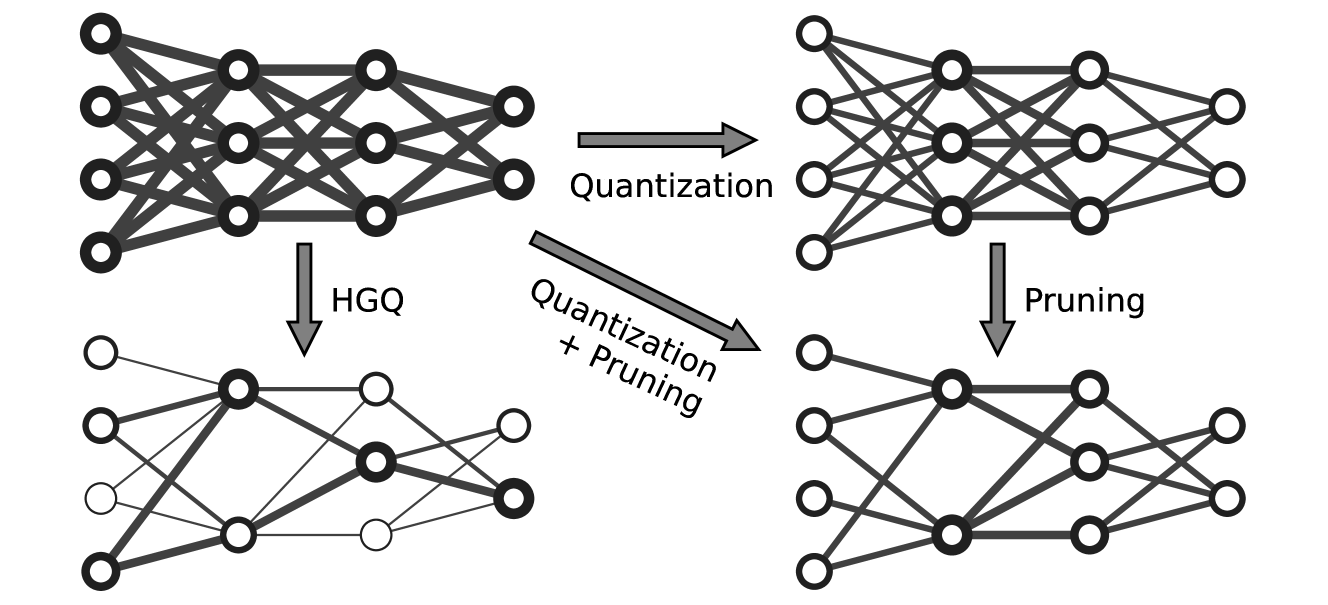
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
5/2/2024
David and Goliath: An Empirical Evaluation of Attacks and Defenses for QNNs at the Deep Edge
Miguel Costa, Sandro Pinto
0
0
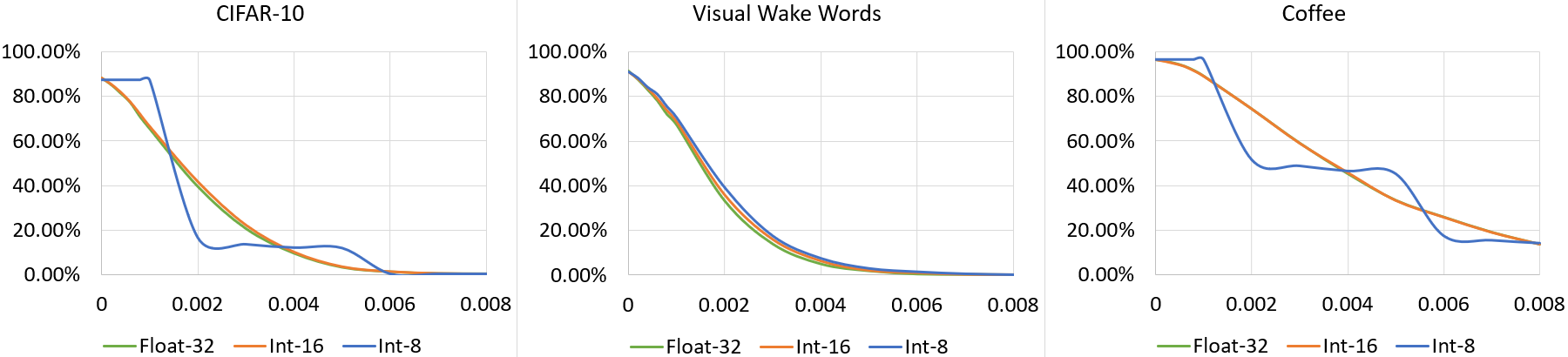
ML is shifting from the cloud to the edge. Edge computing reduces the surface exposing private data and enables reliable throughput guarantees in real-time applications. Of the panoply of devices deployed at the edge, resource-constrained MCUs, e.g., Arm Cortex-M, are more prevalent, orders of magnitude cheaper, and less power-hungry than application processors or GPUs. Thus, enabling intelligence at the deep edge is the zeitgeist, with researchers focusing on unveiling novel approaches to deploy ANNs on these constrained devices. Quantization is a well-established technique that has proved effective in enabling the deployment of neural networks on MCUs; however, it is still an open question to understand the robustness of QNNs in the face of adversarial examples. To fill this gap, we empirically evaluate the effectiveness of attacks and defenses from (full-precision) ANNs on (constrained) QNNs. Our evaluation includes three QNNs targeting TinyML applications, ten attacks, and six defenses. With this study, we draw a set of interesting findings. First, quantization increases the point distance to the decision boundary and leads the gradient estimated by some attacks to explode or vanish. Second, quantization can act as a noise attenuator or amplifier, depending on the noise magnitude, and causes gradient misalignment. Regarding adversarial defenses, we conclude that input pre-processing defenses show impressive results on small perturbations; however, they fall short as the perturbation increases. At the same time, train-based defenses increase the average point distance to the decision boundary, which holds after quantization. However, we argue that train-based defenses still need to smooth the quantization-shift and gradient misalignment phenomenons to counteract adversarial example transferability to QNNs. All artifacts are open-sourced to enable independent validation of results.
5/6/2024