Practical and efficient quantum circuit synthesis and transpiling with Reinforcement Learning
2405.13196
0
0
🏅
Abstract
This paper demonstrates the integration of Reinforcement Learning (RL) into quantum transpiling workflows, significantly enhancing the synthesis and routing of quantum circuits. By employing RL, we achieve near-optimal synthesis of Linear Function, Clifford, and Permutation circuits, up to 9, 11 and 65 qubits respectively, while being compatible with native device instruction sets and connectivity constraints, and orders of magnitude faster than optimization methods such as SAT solvers. We also achieve significant reductions in two-qubit gate depth and count for circuit routing up to 133 qubits with respect to other routing heuristics such as SABRE. We find the method to be efficient enough to be useful in practice in typical quantum transpiling pipelines. Our results set the stage for further AI-powered enhancements of quantum computing workflows.
Create account to get full access
Overview
- This paper explores the integration of Reinforcement Learning (RL) into quantum transpiling workflows, which are used to optimize the synthesis and routing of quantum circuits.
- The researchers demonstrate that by using RL, they can achieve near-optimal synthesis of Linear Function, Clifford, and Permutation circuits, up to 9, 11, and 65 qubits respectively, while also being compatible with native device instruction sets and connectivity constraints.
- The method is also shown to significantly reduce the two-qubit gate depth and count for circuit routing up to 133 qubits, outperforming other routing heuristics like SABRE.
- The researchers find the RL-powered method to be efficient enough to be practical for use in typical quantum transpiling pipelines.
Plain English Explanation
Quantum computers are still in the early stages of development, and one of the key challenges is figuring out how to efficiently program them. This paper explores a way to use a technique called Reinforcement Learning (RL) to help with this problem.
RL is a type of machine learning where an AI system learns by trial and error, getting rewarded for taking actions that lead to good outcomes. In this case, the researchers used RL to help quantum programmers optimize the way they break down and route quantum circuits, which are the instructions that tell a quantum computer what to do.
By using RL, the researchers were able to create quantum circuits that were very close to the best possible ones, with far fewer of the key building blocks (called gates) than circuits made using other optimization methods. This makes the quantum programs more efficient and easier to run on actual quantum hardware.
The researchers also found that their RL-powered method was fast enough to be useful in real-world quantum programming workflows, which is important because quantum computers are still very sensitive and difficult to program.
Overall, this research shows how AI techniques like RL could help unlock the potential of quantum computing by making it easier and more efficient to program these powerful but tricky machines.
Technical Explanation
The paper demonstrates how the researchers integrated Reinforcement Learning (RL) into quantum transpiling workflows, which are the processes used to optimize the synthesis and routing of quantum circuits.
Through their RL-based approach, the researchers were able to achieve near-optimal synthesis of Linear Function, Clifford, and Permutation circuits, up to 9, 11, and 65 qubits respectively. This means they could create highly efficient quantum circuits that were close to the theoretical best possible, while also ensuring compatibility with the native instruction sets and connectivity constraints of quantum hardware.
The researchers also demonstrated significant reductions in two-qubit gate depth and count for circuit routing up to 133 qubits, outperforming other routing heuristics like SABRE. Two-qubit gates are a critical component of quantum circuits, so reducing their usage is an important optimization.
The efficiency of the RL-powered method was found to be suitable for practical use in typical quantum transpiling pipelines, which is crucial given the sensitivity and complexity of current quantum hardware and software.
The researchers note that their work sets the stage for further AI-powered enhancements of quantum computing workflows, showing the potential for machine learning techniques to unlock new capabilities in this emerging field.
Critical Analysis
The paper provides a compelling demonstration of how Reinforcement Learning can be effectively integrated into quantum transpiling workflows. However, the researchers acknowledge some limitations and areas for further research.
For example, the paper focuses on specific types of quantum circuits (Linear Function, Clifford, and Permutation) and does not address the optimization of more complex or application-specific circuits. Additionally, the scalability of the RL-based approach for very large circuits (e.g., hundreds of qubits) is not fully explored.
While the researchers show the efficiency of their method, they do not provide a detailed comparison to the computational costs of other optimization approaches. Further investigation into the tradeoffs between solution quality and runtime would help contextualize the advantages of the RL-based technique.
Additionally, the paper does not delve into the interpretability of the RL agent's decision-making process. Understanding the reasoning behind the RL agent's choices could lead to further insights and potential improvements to the overall approach.
Overall, the research represents an important step forward in leveraging AI techniques to enhance quantum computing capabilities. However, continued exploration of the limitations and potential extensions of this work will be crucial to realizing the full benefits of RL-powered quantum transpiling.
Conclusion
This paper demonstrates the successful integration of Reinforcement Learning (RL) into quantum transpiling workflows, which are used to optimize the synthesis and routing of quantum circuits. The researchers show that by employing RL, they can achieve near-optimal synthesis of various types of quantum circuits, while also significantly reducing the two-qubit gate depth and count during circuit routing.
The efficiency of the RL-powered method makes it practical for use in typical quantum transpiling pipelines, which is a crucial step forward in unlocking the potential of quantum computing. This research sets the stage for further AI-powered enhancements of quantum computing workflows, potentially leading to more accessible and powerful quantum programming tools in the future.
As quantum computing continues to evolve, techniques like the one presented in this paper will play an important role in helping developers and researchers overcome the challenges of programming these complex and sensitive machines. By leveraging the power of machine learning, the field of quantum computing can continue to advance and bring us closer to realizing the transformative potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
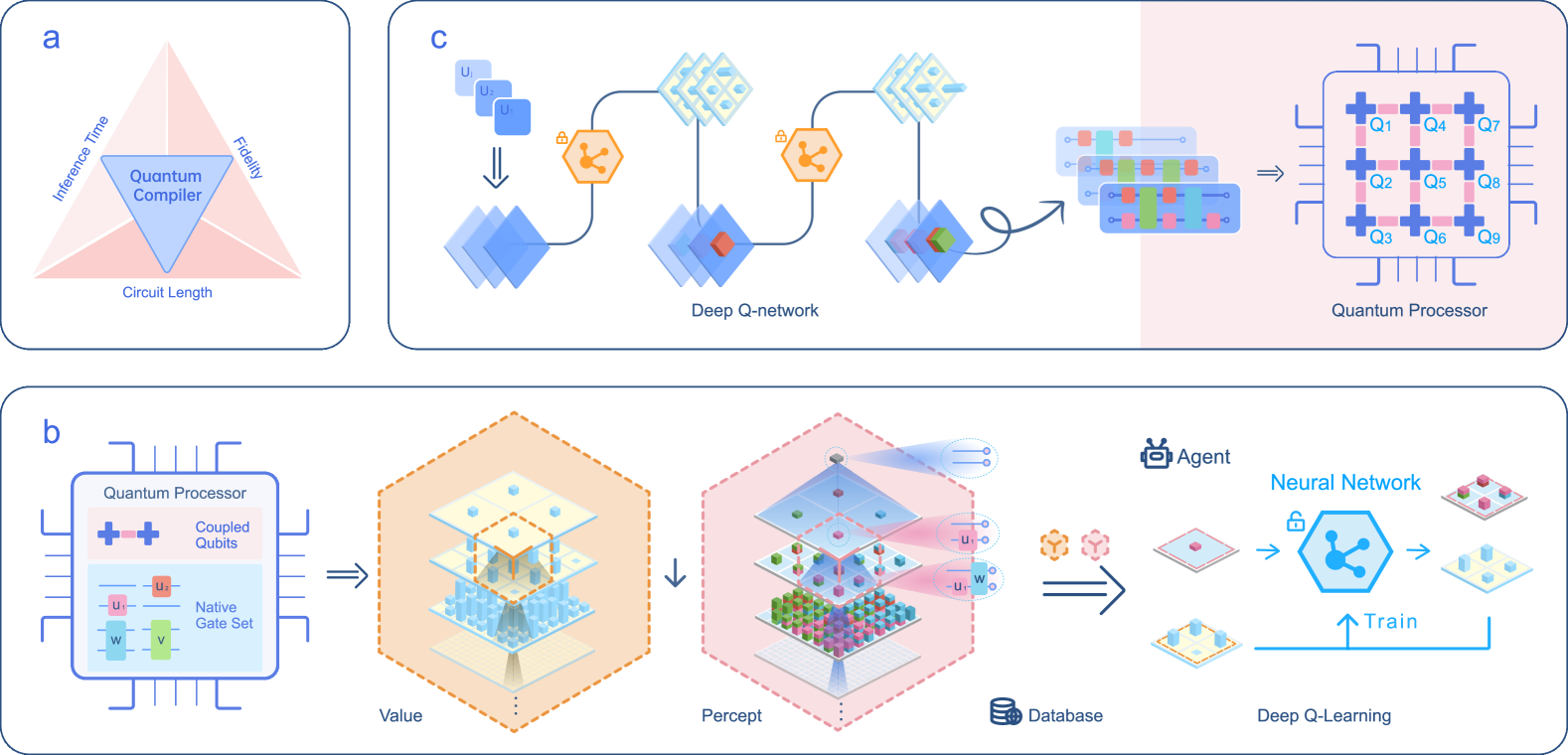
Quantum Compiling with Reinforcement Learning on a Superconducting Processor
Z. T. Wang, Qiuhao Chen, Yuxuan Du, Z. H. Yang, Xiaoxia Cai, Kaixuan Huang, Jingning Zhang, Kai Xu, Jun Du, Yinan Li, Yuling Jiao, Xingyao Wu, Wu Liu, Xiliang Lu, Huikai Xu, Yirong Jin, Ruixia Wang, Haifeng Yu, S. P. Zhao
0
0
To effectively implement quantum algorithms on noisy intermediate-scale quantum (NISQ) processors is a central task in modern quantum technology. NISQ processors feature tens to a few hundreds of noisy qubits with limited coherence times and gate operations with errors, so NISQ algorithms naturally require employing circuits of short lengths via quantum compilation. Here, we develop a reinforcement learning (RL)-based quantum compiler for a superconducting processor and demonstrate its capability of discovering novel and hardware-amenable circuits with short lengths. We show that for the three-qubit quantum Fourier transformation, a compiled circuit using only seven CZ gates with unity circuit fidelity can be achieved. The compiler is also able to find optimal circuits under device topological constraints, with lengths considerably shorter than those by the conventional method. Our study exemplifies the codesign of the software with hardware for efficient quantum compilation, offering valuable insights for the advancement of RL-based compilers.
6/19/2024
🏅
Compiler for Distributed Quantum Computing: a Reinforcement Learning Approach
Panagiotis Promponas, Akrit Mudvari, Luca Della Chiesa, Paul Polakos, Louis Samuel, Leandros Tassiulas
0
0
The practical realization of quantum programs that require large-scale qubit systems is hindered by current technological limitations. Distributed Quantum Computing (DQC) presents a viable path to scalability by interconnecting multiple Quantum Processing Units (QPUs) through quantum links, facilitating the distributed execution of quantum circuits. In DQC, EPR pairs are generated and shared between distant QPUs, which enables quantum teleportation and facilitates the seamless execution of circuits. A primary obstacle in DQC is the efficient mapping and routing of logical qubits to physical qubits across different QPUs, necessitating sophisticated strategies to overcome hardware constraints and optimize communication. We introduce a novel compiler that, unlike existing approaches, prioritizes reducing the expected execution time by jointly managing the generation and routing of EPR pairs, scheduling remote operations, and injecting SWAP gates to facilitate the execution of local gates. We present a real-time, adaptive approach to compiler design, accounting for the stochastic nature of entanglement generation and the operational demands of quantum circuits. Our contributions are twofold: (i) we model the optimal compiler for DQC using a Markov Decision Process (MDP) formulation, establishing the existence of an optimal algorithm, and (ii) we introduce a constrained Reinforcement Learning (RL) method to approximate this optimal compiler, tailored to the complexities of DQC environments. Our simulations demonstrate that Double Deep Q-Networks (DDQNs) are effective in learning policies that minimize the depth of the compiled circuit, leading to a lower expected execution time and likelihood of successful operation before qubits decohere.
4/29/2024
Challenges for Reinforcement Learning in Quantum Circuit Design
Philipp Altmann, Jonas Stein, Michael Kolle, Adelina Barligea, Thomas Gabor, Thomy Phan, Sebastian Feld, Claudia Linnhoff-Popien
0
0
Quantum computing (QC) in the current NISQ era is still limited in size and precision. Hybrid applications mitigating those shortcomings are prevalent to gain early insight and advantages. Hybrid quantum machine learning (QML) comprises both the application of QC to improve machine learning (ML) and ML to improve QC architectures. This work considers the latter, leveraging reinforcement learning (RL) to improve the search for viable quantum architectures, which we formalize by a set of generic challenges. Furthermore, we propose a concrete framework, formalized as a Markov decision process, to enable learning policies capable of controlling a universal set of continuously parameterized quantum gates. Finally, we provide benchmark comparisons to assess the shortcomings and strengths of current state-of-the-art RL algorithms.
4/5/2024
🤿
Quantum Deep Reinforcement Learning for Robot Navigation Tasks
Hans Hohenfeld, Dirk Heimann, Felix Wiebe, Frank Kirchner
0
0
We utilize hybrid quantum deep reinforcement learning to learn navigation tasks for a simple, wheeled robot in simulated environments of increasing complexity. For this, we train parameterized quantum circuits (PQCs) with two different encoding strategies in a hybrid quantum-classical setup as well as a classical neural network baseline with the double deep Q network (DDQN) reinforcement learning algorithm. Quantum deep reinforcement learning (QDRL) has previously been studied in several relatively simple benchmark environments, mainly from the OpenAI gym suite. However, scaling behavior and applicability of QDRL to more demanding tasks closer to real-world problems e. g., from the robotics domain, have not been studied previously. Here, we show that quantum circuits in hybrid quantum-classic reinforcement learning setups are capable of learning optimal policies in multiple robotic navigation scenarios with notably fewer trainable parameters compared to a classical baseline. Across a large number of experimental configurations, we find that the employed quantum circuits outperform the classical neural network baselines when equating for the number of trainable parameters. Yet, the classical neural network consistently showed better results concerning training times and stability, with at least one order of magnitude of trainable parameters more than the best-performing quantum circuits. However, validating the robustness of the learning methods in a large and dynamic environment, we find that the classical baseline produces more stable and better performing policies overall.
6/26/2024