Practical Persistent Multi-Word Compare-and-Swap Algorithms for Many-Core CPUs
2404.01710
0
0

Abstract
In the last decade, academic and industrial researchers have focused on persistent memory because of the development of the first practical product, Intel Optane. One of the main challenges of persistent memory programming is to guarantee consistent durability over separate memory addresses, and Wang et al. proposed a persistent multi-word compare-and-swap (PMwCAS) algorithm to solve this problem. However, their algorithm contains redundant compare-and-swap (CAS) and cache flush instructions and does not achieve sufficient performance on many-core CPUs. This paper proposes a new algorithm to improve performance on many-core CPUs by removing useless CAS/flush instructions from PMwCAS operations. We also exclude dirty flags, which help ensure consistent durability in the original algorithm, from our algorithm using PMwCAS descriptors as write-ahead logs. Experimental results show that the proposed method is up to ten times faster than the original algorithm and suggests several productive uses of PMwCAS operations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper presents practical algorithms for performing persistent multi-word compare-and-swap operations on many-core CPUs.
- Compare-and-swap is a fundamental synchronization primitive used in concurrent programming to ensure data consistency.
- The proposed algorithms address the challenge of performing this operation reliably on modern many-core systems.
Plain English Explanation
Imagine you have a shopping cart with multiple items, and you want to update the contents all at once in a safe way. The compare-and-swap operation allows you to check if the cart contents match what you expected, and if so, update them atomically (all at once). This is important to prevent race conditions where two people try to modify the cart at the same time.
However, as computer systems have become more complex with many processing cores, performing this multi-item compare-and-swap operation reliably has become a challenge. The researchers in this paper have developed new algorithms to address this problem, making it easier for software developers to build concurrent applications that can safely modify multiple pieces of data together.
By overcoming this technical hurdle, the researchers have enabled more efficient and robust concurrent programming, which is crucial as computer systems continue to utilize an increasing number of processing cores.
Technical Explanation
The paper presents two new persistent multi-word compare-and-swap (PMWCS) algorithms designed for many-core CPUs. These algorithms allow for atomic updates to multiple memory locations, which is important for ensuring data consistency in concurrent programs.
The first algorithm, called PMWCS-Lock, uses a lock-based approach to coordinate access to the shared data. It employs a novel lock acquisition mechanism to reduce contention and improve performance. The second algorithm, called PMWCS-LockFree, is a lock-free implementation that avoids the use of locks altogether, further improving scalability.
The researchers conducted extensive experiments to evaluate the performance and scalability of their algorithms compared to existing approaches. They measured various metrics, such as throughput, latency, and scalability, across different workloads and system configurations. The results show that the proposed algorithms outperform the state-of-the-art in terms of both efficiency and scalability, particularly on many-core systems.
Critical Analysis
The paper provides a thorough evaluation of the proposed PMWCS algorithms, including comparisons to existing solutions. The authors have identified and addressed key challenges in designing efficient and scalable multi-word compare-and-swap operations for modern many-core CPUs.
One potential limitation mentioned in the paper is the assumption of a non-volatile main memory (NVMM) system, which may not be widely available yet. The algorithms could be further evaluated on traditional volatile memory systems to assess their broader applicability.
Additionally, the paper does not discuss the impact of the PMWCS algorithms on the overall system complexity or development effort required by software engineers. While the performance benefits are clear, the trade-offs in terms of system complexity and programming effort could be an area for further investigation.
Conclusion
This research paper presents practical and efficient algorithms for performing persistent multi-word compare-and-swap operations on many-core CPUs. The proposed solutions address a critical challenge in concurrent programming, enabling more robust and scalable applications that can safely modify multiple pieces of data together.
By overcoming this technical hurdle, the researchers have contributed to the advancement of concurrent programming techniques, which will become increasingly important as computer systems continue to leverage more processing cores. The performance and scalability improvements demonstrated in the paper suggest that these algorithms can have a significant impact on the development of efficient and reliable concurrent applications.
Related Papers
🔄
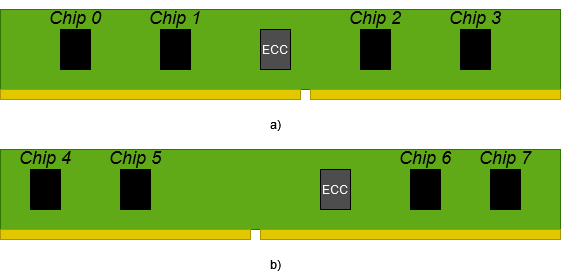
On Error Correction for Nonvolatile Processing-In-Memory
Husrev C{i}lasun, Salonik Resch, Zamshed I. Chowdhury, Masoud Zabihi, Yang Lv, Brandon Zink, Jian-Ping Wang, Sachin S. Sapatnekar, Ulya R. Karpuzcu
0
0
Processing in memory (PiM) represents a promising computing paradigm to enhance performance of numerous data-intensive applications. Variants performing computing directly in emerging nonvolatile memories can deliver very high energy efficiency. PiM architectures directly inherit the vulnerabilities of the underlying memory substrates, but they also are subject to errors due to the computation in place. Numerous well-established error correcting codes (ECC) for memory exist, and are also considered in the PiM context, however, they typically ignore errors that occur throughout computation. In this paper we revisit the error correction design space for nonvolatile PiM, considering both storage/memory and computation-induced errors, surveying several self-checking and homomorphic approaches. We propose several solutions and analyze their complex performance-area-coverage trade-off, using three representative nonvolatile PiM technologies. All of these solutions guarantee single error correction for both, bulk bitwise computations and ordinary memory/storage errors.
4/30/2024

Tascade: Hardware Support for Atomic-free, Asynchronous and Efficient Reduction Trees
Marcelo Orenes-Vera, Esin Tureci, David Wentzlaff, Margaret Martonosi
0
0
Graph search and sparse data-structure traversal workloads contain challenging irregular memory patterns on global data structures that need to be modified atomically. Distributed processing of these workloads has relied on server threads operating on their own data copies that are merged upon global synchronization. As parallelism increases within each server, the communication challenges that arose in distributed systems a decade ago are now being encountered within large manycore servers. Prior work has achieved scalability for sparse applications up to thousands of PUs on-chip, but does not scale further due to increasing communication distances and load-imbalance across PUs. To address these challenges we propose Tascade, a hardware-software co-design that offers support for storage-efficient data-private reductions as well as asynchronous and opportunistic reduction trees. Tascade introduces an execution model along with supporting hardware design that allows coalescing of data updates regionally and merges the data from these regions through cascaded updates. Together, Tascade innovations minimize communication and increase work balance in task-based parallelization schemes and scales up to a million PUs. We evaluate six applications and four datasets to provide a detailed analysis of Tascade's performance, power, and traffic-reduction gains over prior work. Our parallelization of Breadth-First-Search with RMAT-26 across a million PUs -- the largest of the literature -- reaches over 7600 GTEPS.
4/23/2024
Multicore DRAM Bank-& Row-Conflict Bomb for Timing Attacks in Mixed-Criticality Systems
Antonio Savino, Gautam Gala, Marcello Cinque, Gerhard Fohler
0
0
With the increasing use of multicore platforms to realize mixed-criticality systems, understanding the underlying shared resources, such as the memory hierarchy shared among cores, and achieving isolation between co-executing tasks running on the same platform with different criticality levels becomes relevant. In addition to safety considerations, a malicious entity can exploit shared resources to create timing attacks on critical applications. In this paper, we focus on understanding the shared DRAM dual in-line memory module and created a timing attack, that we named the bank & row conflict bomb, to target a victim task in a multicore platform. We also created a navigate algorithm to understand how victim requests are managed by the Memory Controller and provide valuable inputs for designing the bank & row conflict bomb. We performed experimental tests on a 2nd Gen Intel Xeon Processor with an 8GB DDR4-2666 DRAM module to show that such an attack can produce a significant increase in the execution time of the victim task by about 150%, motivating the need for proper countermeasures to help ensure the safety and security of critical applications.
4/3/2024
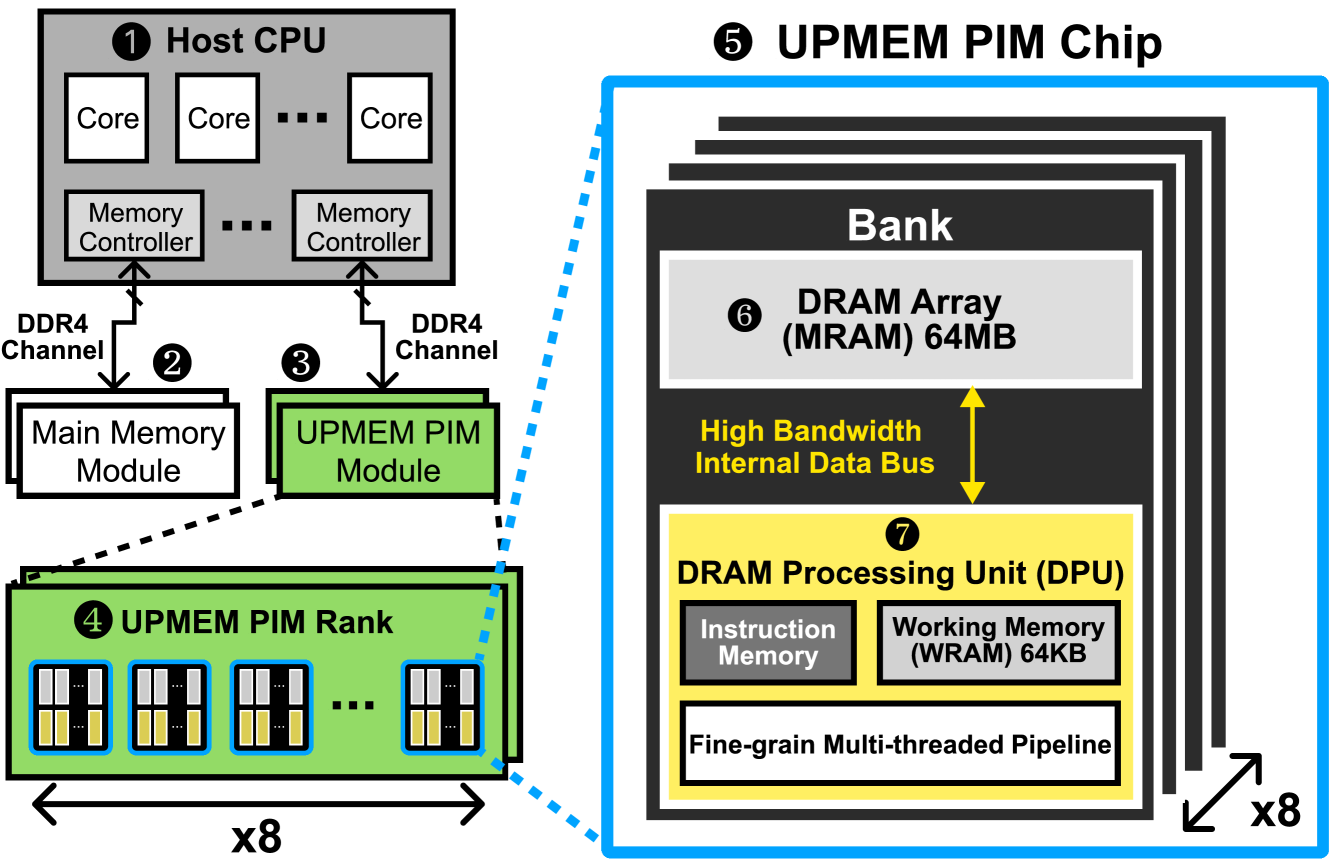
Analysis of Distributed Optimization Algorithms on a Real Processing-In-Memory System
Steve Rhyner, Haocong Luo, Juan G'omez-Luna, Mohammad Sadrosadati, Jiawei Jiang, Ataberk Olgun, Harshita Gupta, Ce Zhang, Onur Mutlu
0
0
Machine Learning (ML) training on large-scale datasets is a very expensive and time-consuming workload. Processor-centric architectures (e.g., CPU, GPU) commonly used for modern ML training workloads are limited by the data movement bottleneck, i.e., due to repeatedly accessing the training dataset. As a result, processor-centric systems suffer from performance degradation and high energy consumption. Processing-In-Memory (PIM) is a promising solution to alleviate the data movement bottleneck by placing the computation mechanisms inside or near memory. Our goal is to understand the capabilities and characteristics of popular distributed optimization algorithms on real-world PIM architectures to accelerate data-intensive ML training workloads. To this end, we 1) implement several representative centralized distributed optimization algorithms on UPMEM's real-world general-purpose PIM system, 2) rigorously evaluate these algorithms for ML training on large-scale datasets in terms of performance, accuracy, and scalability, 3) compare to conventional CPU and GPU baselines, and 4) discuss implications for future PIM hardware and the need to shift to an algorithm-hardware codesign perspective to accommodate decentralized distributed optimization algorithms. Our results demonstrate three major findings: 1) Modern general-purpose PIM architectures can be a viable alternative to state-of-the-art CPUs and GPUs for many memory-bound ML training workloads, when operations and datatypes are natively supported by PIM hardware, 2) the importance of carefully choosing the optimization algorithm that best fit PIM, and 3) contrary to popular belief, contemporary PIM architectures do not scale approximately linearly with the number of nodes for many data-intensive ML training workloads. To facilitate future research, we aim to open-source our complete codebase.
4/11/2024