Practical token pruning for foundation models in few-shot conversational virtual assistant systems

0
🧪
Sign in to get full access
Overview
- This paper proposes a practical token pruning method for foundation models used in few-shot conversational virtual assistant systems.
- The goal is to reduce the computational cost of these models while maintaining their accuracy and performance.
- The key ideas include selectively pruning tokens based on their importance and using efficient attention mechanisms.
Plain English Explanation
The paper is about making foundation models - which are large, powerful AI models - more efficient and practical to use in conversational virtual assistant systems, especially when there is only a small amount of training data available.
The core problem is that these large foundation models can be computationally expensive to run, requiring a lot of processing power and memory. The researchers develop a method to prune - or selectively remove - certain parts of the model, called "tokens", without significantly impacting the model's accuracy or performance.
This pruning allows the model to run more efficiently, using less computing resources, which is important for real-world virtual assistant applications where speed and responsiveness are crucial. The approach involves intelligently selecting which tokens to keep or remove based on their importance to the task at hand.
Technical Explanation
The paper introduces a token pruning method for foundation models used in few-shot conversational virtual assistant systems. The key ideas are:
- Selective Token Pruning: The model selectively prunes tokens based on their importance, removing less relevant tokens to reduce computational cost.
- Efficient Attention Mechanism: The model employs an efficient attention mechanism that can operate on the pruned token representations, further improving efficiency.
- Few-shot Adaptation: The model can be efficiently adapted to new tasks using only a small amount of training data, leveraging the power of the foundation model.
Experiments show this approach can significantly reduce the computational requirements of the foundation model while maintaining its accuracy and performance on conversational tasks, making it more practical for real-world virtual assistant applications.
Critical Analysis
The paper provides a thorough and well-designed study on improving the efficiency of foundation models for few-shot conversational tasks. The proposed token pruning and efficient attention mechanisms seem promising, and the experimental results demonstrate their effectiveness.
However, the paper does not address potential limitations or edge cases, such as how the pruning method might perform on more complex or diverse conversational tasks, or how it would scale to larger foundation models. Additionally, the paper does not explore the trade-offs between the level of pruning and the model's performance, which could be useful for practitioners to understand.
Further research could investigate the generalizability of this approach to other foundation models and tasks, as well as explore more advanced pruning techniques or ways to automatically adjust the level of pruning based on the specific requirements of the application.
Conclusion
This paper presents a practical solution for making foundation models more efficient and suitable for use in few-shot conversational virtual assistant systems. By selectively pruning tokens and employing an efficient attention mechanism, the researchers demonstrate a way to significantly reduce the computational cost of these large, powerful models without sacrificing their accuracy or performance.
This work has the potential to enable more widespread adoption of foundation models in real-world virtual assistant applications, where speed, responsiveness, and resource-efficiency are critical. The ideas and techniques introduced in this paper could also serve as a foundation for further research and development in this important area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
Practical token pruning for foundation models in few-shot conversational virtual assistant systems
Haode Qi, Cheng Qian, Jian Ni, Pratyush Singh, Reza Fazeli, Gengyu Wang, Zhongzheng Shu, Eric Wayne, Juergen Bross
In an enterprise Virtual Assistant (VA) system, intent classification is the crucial component that determines how a user input is handled based on what the user wants. The VA system is expected to be a cost-efficient SaaS service with low training and inference time while achieving high accuracy even with a small number of training samples. We pretrain a transformer-based sentence embedding model with a contrastive learning objective and leverage the embedding of the model as features when training intent classification models. Our approach achieves the state-of-the-art results for few-shot scenarios and performs better than other commercial solutions on popular intent classification benchmarks. However, generating features via a transformer-based model increases the inference time, especially for longer user inputs, due to the quadratic runtime of the transformer's attention mechanism. On top of model distillation, we introduce a practical multi-task adaptation approach that configures dynamic token pruning without the need for task-specific training for intent classification. We demonstrate that this approach improves the inference speed of popular sentence transformer models without affecting model performance.
Read more8/22/2024

0
Focus on the Core: Efficient Attention via Pruned Token Compression for Document Classification
Jungmin Yun, Mihyeon Kim, Youngbin Kim
Transformer-based models have achieved dominant performance in numerous NLP tasks. Despite their remarkable successes, pre-trained transformers such as BERT suffer from a computationally expensive self-attention mechanism that interacts with all tokens, including the ones unfavorable to classification performance. To overcome these challenges, we propose integrating two strategies: token pruning and token combining. Token pruning eliminates less important tokens in the attention mechanism's key and value as they pass through the layers. Additionally, we adopt fuzzy logic to handle uncertainty and alleviate potential mispruning risks arising from an imbalanced distribution of each token's importance. Token combining, on the other hand, condenses input sequences into smaller sizes in order to further compress the model. By integrating these two approaches, we not only improve the model's performance but also reduce its computational demands. Experiments with various datasets demonstrate superior performance compared to baseline models, especially with the best improvement over the existing BERT model, achieving +5%p in accuracy and +5.6%p in F1 score. Additionally, memory cost is reduced to 0.61x, and a speedup of 1.64x is achieved.
Read more6/4/2024
🏷️
0
Zero-TPrune: Zero-Shot Token Pruning through Leveraging of the Attention Graph in Pre-Trained Transformers
Hongjie Wang, Bhishma Dedhia, Niraj K. Jha
Deployment of Transformer models on edge devices is becoming increasingly challenging due to the exponentially growing inference cost that scales quadratically with the number of tokens in the input sequence. Token pruning is an emerging solution to address this challenge due to its ease of deployment on various Transformer backbones. However, most token pruning methods require computationally expensive fine-tuning, which is undesirable in many edge deployment cases. In this work, we propose Zero-TPrune, the first zero-shot method that considers both the importance and similarity of tokens in performing token pruning. It leverages the attention graph of pre-trained Transformer models to produce an importance distribution for tokens via our proposed Weighted Page Rank (WPR) algorithm. This distribution further guides token partitioning for efficient similarity-based pruning. Due to the elimination of the fine-tuning overhead, Zero-TPrune can prune large models at negligible computational cost, switch between different pruning configurations at no computational cost, and perform hyperparameter tuning efficiently. We evaluate the performance of Zero-TPrune on vision tasks by applying it to various vision Transformer backbones and testing them on ImageNet. Without any fine-tuning, Zero-TPrune reduces the FLOPs cost of DeiT-S by 34.7% and improves its throughput by 45.3% with only 0.4% accuracy loss. Compared with state-of-the-art pruning methods that require fine-tuning, Zero-TPrune not only eliminates the need for fine-tuning after pruning but also does so with only 0.1% accuracy loss. Compared with state-of-the-art fine-tuning-free pruning methods, Zero-TPrune reduces accuracy loss by up to 49% with similar FLOPs budgets. Project webpage: https://jha-lab.github.io/zerotprune.
Read more4/9/2024
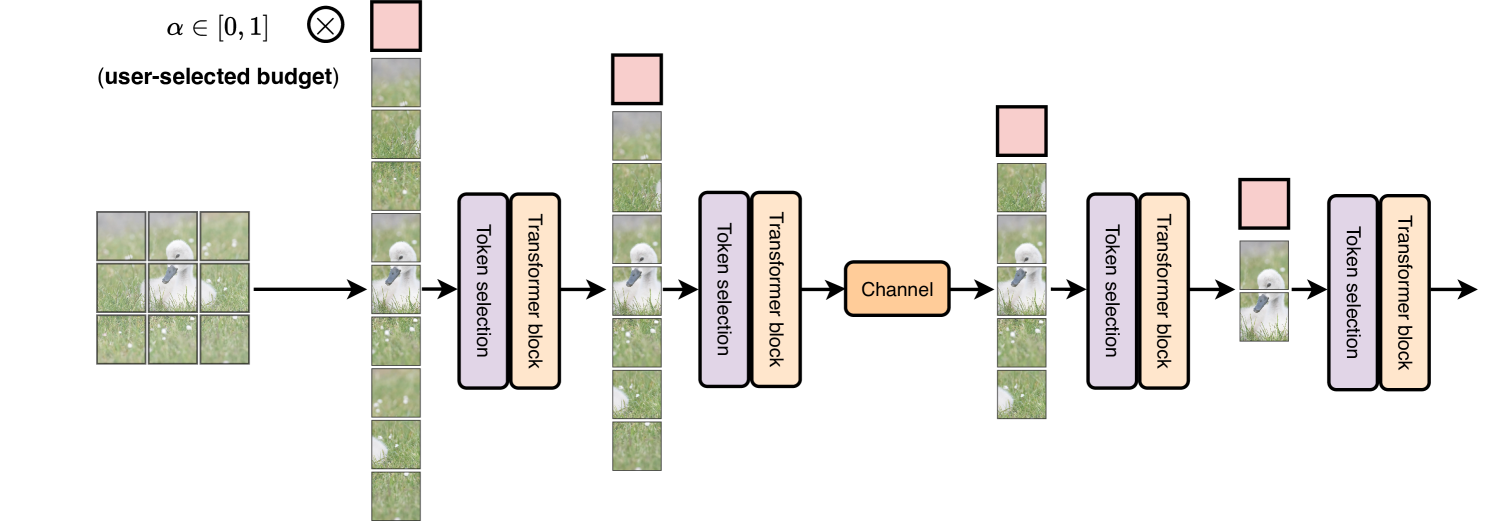
0
Adaptive Semantic Token Selection for AI-native Goal-oriented Communications
Alessio Devoto, Simone Petruzzi, Jary Pomponi, Paolo Di Lorenzo, Simone Scardapane
In this paper, we propose a novel design for AI-native goal-oriented communications, exploiting transformer neural networks under dynamic inference constraints on bandwidth and computation. Transformers have become the standard architecture for pretraining large-scale vision and text models, and preliminary results have shown promising performance also in deep joint source-channel coding (JSCC). Here, we consider a dynamic model where communication happens over a channel with variable latency and bandwidth constraints. Leveraging recent works on conditional computation, we exploit the structure of the transformer blocks and the multihead attention operator to design a trainable semantic token selection mechanism that learns to select relevant tokens (e.g., image patches) from the input signal. This is done dynamically, on a per-input basis, with a rate that can be chosen as an additional input by the user. We show that our model improves over state-of-the-art token selection mechanisms, exhibiting high accuracy for a wide range of latency and bandwidth constraints, without the need for deploying multiple architectures tailored to each constraint. Last, but not least, the proposed token selection mechanism helps extract powerful semantics that are easy to understand and explain, paving the way for interpretable-by-design models for the next generation of AI-native communication systems.
Read more5/7/2024