Minimizing PLM-Based Few-Shot Intent Detectors

0

Sign in to get full access
Overview
- This paper presents a method for minimizing the size and complexity of few-shot intent detection models based on large language models (PLMs).
- The goal is to create a more efficient and practical intent detection system that can be deployed on resource-constrained devices.
- The key ideas include model compression techniques like pruning and quantization, as well as a novel training method that leverages transfer learning from a larger PLM.
Plain English Explanation
The paper describes a way to make intent detection models that are based on large language models (PLMs) smaller and more efficient. Intent detection is the task of figuring out what a user is trying to do based on their input, like asking for the weather or setting a reminder. PLM-based intent detectors can do this well, but they are often large and complex, which makes them hard to use on devices with limited computing power, like phones or smart home assistants.
The researchers developed techniques to <a href="https://aimodels.fyi/papers/arxiv/improving-large-models-small-models-lower-costs">compress the large PLM-based models</a> and make them smaller and simpler, without losing too much of their performance. This includes <a href="https://aimodels.fyi/papers/arxiv/one-shot-sensitivity-aware-mixed-sparsity-pruning">pruning out parts of the model</a> that aren't as important, and <a href="https://aimodels.fyi/papers/arxiv/large-language-models-wireless-application-design-context">quantizing the model parameters</a> to use less memory.
They also came up with a new training method that takes advantage of the knowledge in the larger PLM, but in a way that results in a smaller, more efficient intent detection model. The key idea is to use the PLM to help learn a good starting point for the compressed model, rather than training the compressed model from scratch.
The goal is to create intent detection models that are powerful enough to work well, but small and efficient enough to run on devices with limited resources, like phones or smart home gadgets. This could make these technologies more accessible and usable in a wider range of applications.
Technical Explanation
The paper proposes a method for minimizing the size and complexity of few-shot intent detection models based on large pre-trained language models (PLMs). The goal is to create a more efficient and practical intent detection system that can be deployed on resource-constrained devices.
The key technical contributions include:
-
Model Compression: The researchers apply various model compression techniques, such as <a href="https://aimodels.fyi/papers/arxiv/one-shot-sensitivity-aware-mixed-sparsity-pruning">structured and unstructured pruning</a> as well as <a href="https://aimodels.fyi/papers/arxiv/large-language-models-wireless-application-design-context">quantization</a>, to reduce the size and computational complexity of the PLM-based intent detection model.
-
Transfer Learning with Distillation: The paper introduces a novel training method that leverages transfer learning from the larger PLM. Instead of training the compressed model from scratch, the researchers use a distillation-based approach to transfer knowledge from the PLM to the compressed model, helping it learn a good starting point for the task.
-
Few-Shot Learning: The proposed method is designed to work in a few-shot learning scenario, where the intent detection model needs to learn new intents from only a small number of examples. The transfer learning and compression techniques are tailored to this setting.
The experimental results show that the compressed models achieve competitive performance on few-shot intent detection tasks, while being significantly smaller and more efficient than the original PLM-based models. This makes them more suitable for deployment on resource-constrained devices, such as <a href="https://aimodels.fyi/papers/arxiv/large-language-models-wireless-application-design-context">mobile phones or smart home assistants</a>.
Critical Analysis
The paper presents a well-designed and thorough approach to minimizing the size and complexity of PLM-based intent detection models. The researchers have carefully considered the tradeoffs between model performance, size, and efficiency, and have proposed a comprehensive solution to address these challenges.
One potential limitation of the work is that it has only been evaluated on a few-shot learning scenario, which may not fully capture the real-world deployment challenges. It would be interesting to see how the compressed models perform in a more large-scale, production-like setting, where the number of intents and the diversity of user inputs may be much higher.
Additionally, the paper does not provide a detailed analysis of the compressed models' robustness or generalization capabilities. It would be valuable to understand how the model compression and transfer learning techniques impact the models' ability to handle noisy, ambiguous, or out-of-distribution inputs, which are common in real-world intent detection tasks.
Overall, the research presented in this paper is a valuable contribution to the field of efficient and practical intent detection systems. The proposed methods demonstrate the potential to <a href="https://aimodels.fyi/papers/arxiv/plagbench-exploring-duality-large-language-models-plagiarism">leverage large language models while mitigating their high resource requirements</a>, which is an important step towards making these advanced technologies more accessible and deployable in a wider range of applications.
Conclusion
This paper introduces a method for minimizing the size and complexity of few-shot intent detection models based on large language models (PLMs). The key ideas include model compression techniques like pruning and quantization, as well as a novel training method that leverages transfer learning from a larger PLM to help the compressed model learn a good starting point for the task.
The researchers have shown that the compressed models can achieve competitive performance on few-shot intent detection tasks while being significantly smaller and more efficient than the original PLM-based models. This makes them more suitable for deployment on resource-constrained devices, such as mobile phones or smart home assistants, potentially expanding the reach and accessibility of advanced intent detection capabilities.
While the paper demonstrates the effectiveness of the proposed methods, further research is needed to fully understand the models' robustness, generalization, and performance in more realistic, large-scale deployment scenarios. Nonetheless, this work represents an important step towards creating efficient and practical intent detection systems that can leverage the power of large language models without the high resource requirements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Minimizing PLM-Based Few-Shot Intent Detectors
Haode Zhang, Albert Y. S. Lam, Xiao-Ming Wu
Recent research has demonstrated the feasibility of training efficient intent detectors based on pre-trained language model~(PLM) with limited labeled data. However, deploying these detectors in resource-constrained environments such as mobile devices poses challenges due to their large sizes. In this work, we aim to address this issue by exploring techniques to minimize the size of PLM-based intent detectors trained with few-shot data. Specifically, we utilize large language models (LLMs) for data augmentation, employ a cutting-edge model compression method for knowledge distillation, and devise a vocabulary pruning mechanism called V-Prune. Through these approaches, we successfully achieve a compression ratio of 21 in model memory usage, including both Transformer and the vocabulary, while maintaining almost identical performance levels on four real-world benchmarks.
Read more9/17/2024

0
Compact Language Models via Pruning and Knowledge Distillation
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov
Large language models (LLMs) targeting different deployment scales and sizes are currently produced by training each variant from scratch; this is extremely compute-intensive. In this paper, we investigate if pruning an existing LLM and then re-training it with a fraction (<3%) of the original training data can be a suitable alternative to repeated, full retraining. To this end, we develop a set of practical and effective compression best practices for LLMs that combine depth, width, attention and MLP pruning with knowledge distillation-based retraining; we arrive at these best practices through a detailed empirical exploration of pruning strategies for each axis, methods to combine axes, distillation strategies, and search techniques for arriving at optimal compressed architectures. We use this guide to compress the Nemotron-4 family of LLMs by a factor of 2-4x, and compare their performance to similarly-sized models on a variety of language modeling tasks. Deriving 8B and 4B models from an already pretrained 15B model using our approach requires up to 40x fewer training tokens per model compared to training from scratch; this results in compute cost savings of 1.8x for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. We have open-sourced Minitron model weights on Huggingface, with corresponding supplementary material including example code available on GitHub.
Read more7/23/2024
🏷️
0
New!Revisit Few-shot Intent Classification with PLMs: Direct Fine-tuning vs. Continual Pre-training
Haode Zhang, Haowen Liang, Liming Zhan, Albert Y. S. Lam, Xiao-Ming Wu
We consider the task of few-shot intent detection, which involves training a deep learning model to classify utterances based on their underlying intents using only a small amount of labeled data. The current approach to address this problem is through continual pre-training, i.e., fine-tuning pre-trained language models (PLMs) on external resources (e.g., conversational corpora, public intent detection datasets, or natural language understanding datasets) before using them as utterance encoders for training an intent classifier. In this paper, we show that continual pre-training may not be essential, since the overfitting problem of PLMs on this task may not be as serious as expected. Specifically, we find that directly fine-tuning PLMs on only a handful of labeled examples already yields decent results compared to methods that employ continual pre-training, and the performance gap diminishes rapidly as the number of labeled data increases. To maximize the utilization of the limited available data, we propose a context augmentation method and leverage sequential self-distillation to boost performance. Comprehensive experiments on real-world benchmarks show that given only two or more labeled samples per class, direct fine-tuning outperforms many strong baselines that utilize external data sources for continual pre-training. The code can be found at https://github.com/hdzhang-code/DFTPlus.
Read more9/17/2024
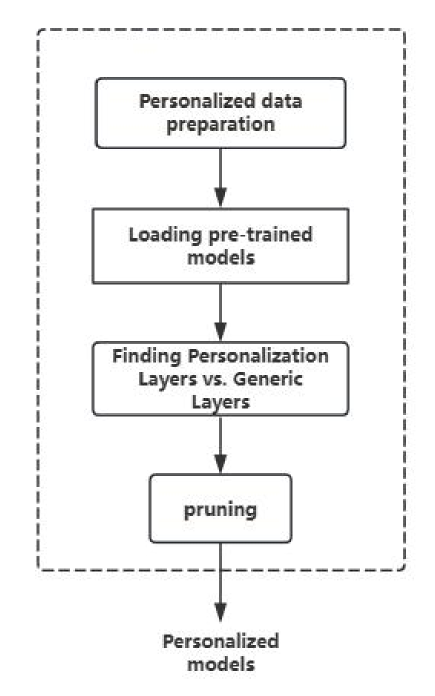
0
Research on Personalized Compression Algorithm for Pre-trained Models Based on Homomorphic Entropy Increase
Yicong Li, Xing Guo, Haohua Du
In this article, we explore the challenges and evolution of two key technologies in the current field of AI: Vision Transformer model and Large Language Model (LLM). Vision Transformer captures global information by splitting images into small pieces and leveraging Transformer's multi-head attention mechanism, but its high reference count and compute overhead limit deployment on mobile devices. At the same time, the rapid development of LLM has revolutionized natural language processing, but it also faces huge deployment challenges. To address these issues, we investigate model pruning techniques, with a particular focus on how to reduce redundant parameters without losing accuracy to accommodate personalized data and resource-constrained environments. In this paper, a new layered pruning strategy is proposed to distinguish the personalized layer from the common layer by compressed sensing and random sampling, thus significantly reducing the model parameters. Our experimental results show that the introduced step buffering mechanism further improves the accuracy of the model after pruning, providing new directions and possibilities for the deployment of efficient and personalized AI models on mobile devices in the future.
Read more8/19/2024