GeMQuAD : Generating Multilingual Question Answering Datasets from Large Language Models using Few Shot Learning
2404.09163
0
0

Abstract
The emergence of Large Language Models (LLMs) with capabilities like In-Context Learning (ICL) has ushered in new possibilities for data generation across various domains while minimizing the need for extensive data collection and modeling techniques. Researchers have explored ways to use this generated synthetic data to optimize smaller student models for reduced deployment costs and lower latency in downstream tasks. However, ICL-generated data often suffers from low quality as the task specificity is limited with few examples used in ICL. In this paper, we propose GeMQuAD - a semi-supervised learning approach, extending the WeakDAP framework, applied to a dataset generated through ICL with just one example in the target language using AlexaTM 20B Seq2Seq LLM. Through our approach, we iteratively identify high-quality data to enhance model performance, especially for low-resource multilingual setting in the context of Extractive Question Answering task. Our framework outperforms the machine translation-augmented model by 0.22/1.68 F1/EM (Exact Match) points for Hindi and 0.82/1.37 F1/EM points for Spanish on the MLQA dataset, and it surpasses the performance of model trained on an English-only dataset by 5.05/6.50 F1/EM points for Hindi and 3.81/3.69 points F1/EM for Spanish on the same dataset. Notably, our approach uses a pre-trained LLM for generation with no fine-tuning (FT), utilizing just a single annotated example in ICL to generate data, providing a cost-effective development process.
Create account to get full access
Overview
- This paper introduces GeMQuAD, a method for generating multilingual question-answering datasets from large language models using few-shot learning.
- The researchers leverage the capabilities of large language models to create high-quality question-answering datasets across multiple languages, which can be used to train and evaluate multilingual question-answering systems.
- The method involves fine-tuning large language models on a small set of annotated examples to generate new questions and answers in various languages.
Plain English Explanation
The paper presents a new way to create datasets for training multilingual question-answering systems. Typically, building such datasets requires a lot of manual effort to annotate questions and answers in multiple languages. However, the researchers show that you can leverage the capabilities of large language models to generate high-quality question-answer pairs automatically, using only a small set of examples to fine-tune the models.
The key idea is to start with a large language model that has been pre-trained on a vast amount of text data. By fine-tuning this model on a few annotated examples of question-answer pairs, you can then use the model to generate new questions and answers in different languages. This "few-shot learning" approach allows you to create diverse, multilingual datasets without the need for extensive manual annotation.
Technical Explanation
The researchers propose the GeMQuAD (Generating Multilingual Question Answering Datasets) method, which uses few-shot learning to create multilingual question-answering datasets from large language models.
The key steps are:
- Pre-training: The researchers start with a large language model that has been pre-trained on a vast amount of text data, such as GPT-3.
- Fine-tuning: They then fine-tune this pre-trained model on a small set of annotated question-answer pairs in one or more languages.
- Generation: Once the model is fine-tuned, they use it to generate new question-answer pairs in various languages, leveraging the model's ability to understand and generate natural language.
The resulting dataset can be used to train and evaluate multilingual question-answering systems, which are crucial for building conversational AI assistants and other applications that need to understand and respond to questions in multiple languages.
Critical Analysis
The researchers acknowledge several limitations and areas for future research:
- The quality of the generated datasets depends on the quality of the fine-tuning data, which may be difficult to obtain for many languages.
- The method has only been evaluated on a few language pairs, and its performance on a wider range of languages is yet to be explored.
- The researchers do not provide a thorough analysis of the biases and potential issues that may arise in the generated datasets, which is an important consideration for real-world applications.
Despite these limitations, the GeMQuAD method represents a promising approach to address the challenge of creating high-quality, multilingual question-answering datasets, which is a crucial step in advancing the field of multilingual natural language processing.
Conclusion
The GeMQuAD method proposed in this paper offers a novel way to generate multilingual question-answering datasets using few-shot learning on large language models. This approach has the potential to significantly reduce the manual effort required to build such datasets, which are essential for training and evaluating multilingual question-answering systems. While the method has some limitations that need further exploration, it represents an important step forward in the quest for more accessible and diverse language resources for artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
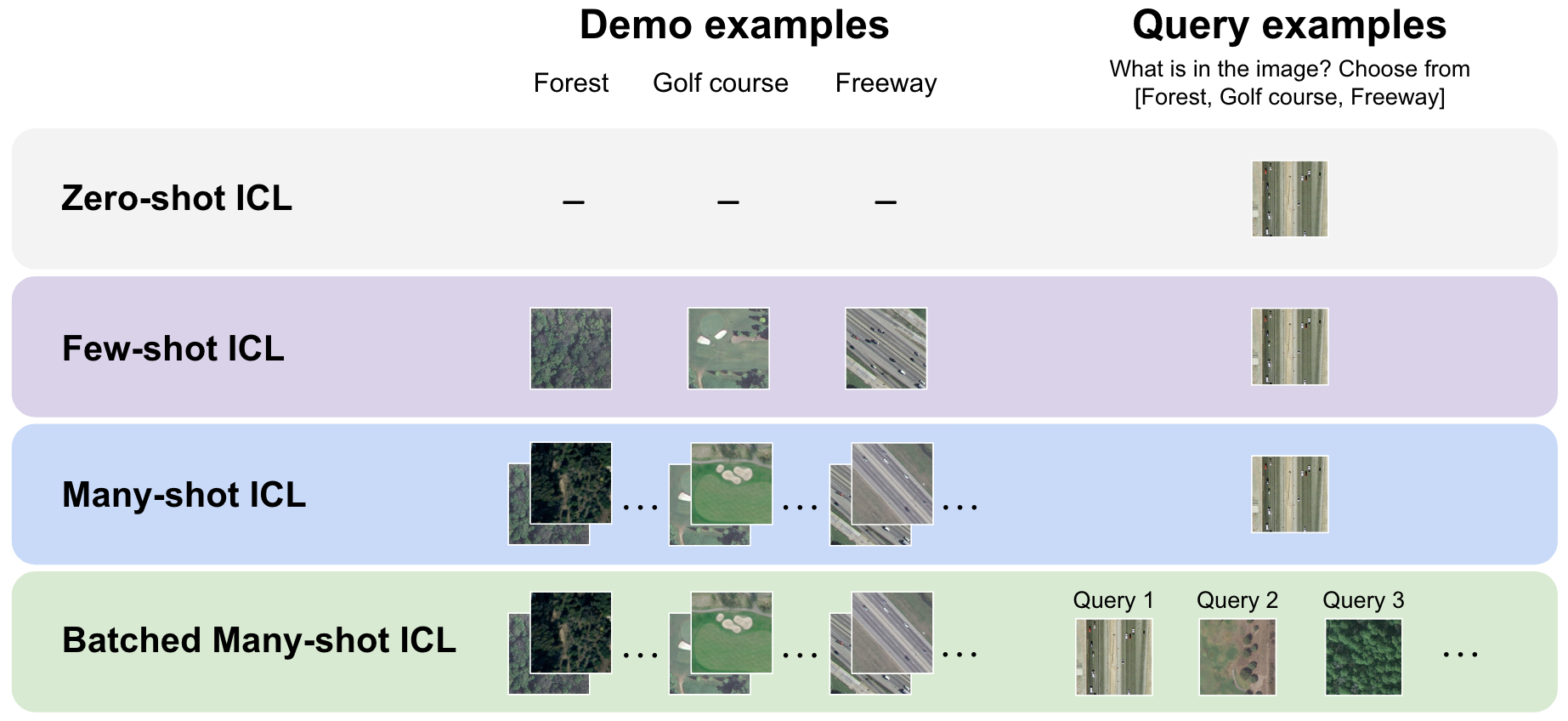
Many-Shot In-Context Learning in Multimodal Foundation Models
Yixing Jiang, Jeremy Irvin, Ji Hun Wang, Muhammad Ahmed Chaudhry, Jonathan H. Chen, Andrew Y. Ng
0
0
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many-shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL .
5/17/2024
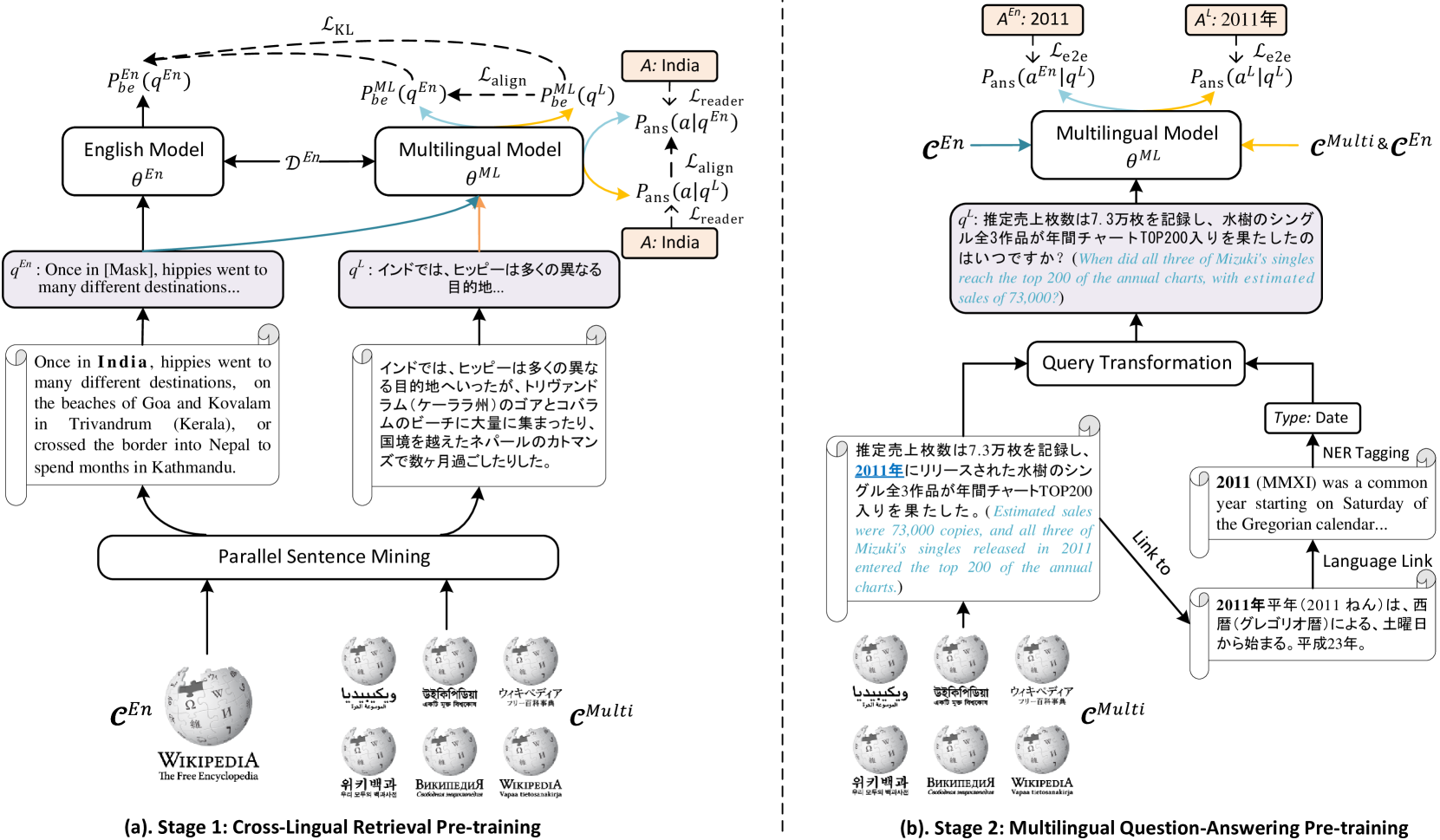
Pre-training Cross-lingual Open Domain Question Answering with Large-scale Synthetic Supervision
Fan Jiang, Tom Drummond, Trevor Cohn
0
0
Cross-lingual open domain question answering (CLQA) is a complex problem, comprising cross-lingual retrieval from a multilingual knowledge base, followed by answer generation in the query language. Both steps are usually tackled by separate models, requiring substantial annotated datasets, and typically auxiliary resources, like machine translation systems to bridge between languages. In this paper, we show that CLQA can be addressed using a single encoder-decoder model. To effectively train this model, we propose a self-supervised method based on exploiting the cross-lingual link structure within Wikipedia. We demonstrate how linked Wikipedia pages can be used to synthesise supervisory signals for cross-lingual retrieval, through a form of cloze query, and generate more natural questions to supervise answer generation. Together, we show our approach, texttt{CLASS}, outperforms comparable methods on both supervised and zero-shot language adaptation settings, including those using machine translation.
6/18/2024
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
0
0
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
5/24/2024
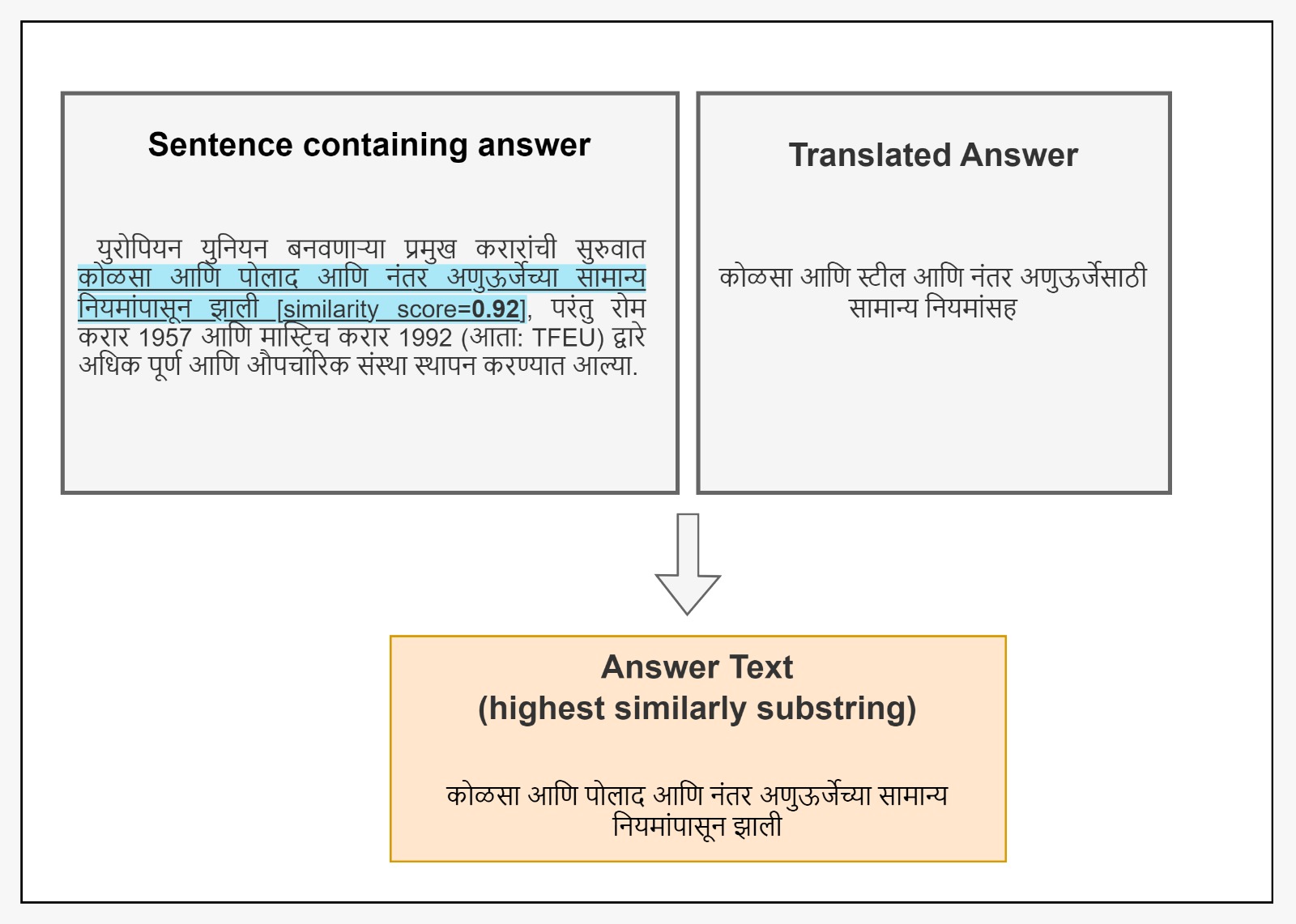
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
0
0
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
4/23/2024