PerkwE_COQA: enhance Persian Conversational Question Answering by combining contextual keyword extraction with Large Language Models
2404.05406
0
0
⛏️
Abstract
Smart cities need the involvement of their residents to enhance quality of life. Conversational query-answering is an emerging approach for user engagement. There is an increasing demand of an advanced conversational question-answering that goes beyond classic systems. Existing approaches have shown that LLMs offer promising capabilities for CQA, but may struggle to capture the nuances of conversational contexts. The new approach involves understanding the content and engaging in a multi-step conversation with the user to fulfill their needs. This paper presents a novel method to elevate the performance of Persian Conversational question-answering (CQA) systems. It combines the strengths of Large Language Models (LLMs) with contextual keyword extraction. Our method extracts keywords specific to the conversational flow, providing the LLM with additional context to understand the user's intent and generate more relevant and coherent responses. We evaluated the effectiveness of this combined approach through various metrics, demonstrating significant improvements in CQA performance compared to an LLM-only baseline. The proposed method effectively handles implicit questions, delivers contextually relevant answers, and tackles complex questions that rely heavily on conversational context. The findings indicate that our method outperformed the evaluation benchmarks up to 8% higher than existing methods and the LLM-only baseline.
Create account to get full access
Overview
- Smart cities need the involvement of their residents to enhance quality of life.
- Conversational query-answering is an emerging approach for user engagement in smart cities.
- There is an increasing demand for advanced conversational question-answering that goes beyond classic systems.
- Existing approaches have shown that Large Language Models (LLMs) offer promising capabilities for Conversational Question Answering (CQA), but may struggle to capture the nuances of conversational contexts.
- The new approach involves understanding the content and engaging in a multi-step conversation with the user to fulfill their needs.
Plain English Explanation
Smart cities aim to improve the lives of their residents, but they need the active participation of those residents to succeed. One way to engage residents is through conversational question-answering systems, which allow people to ask questions and get helpful responses.
Current conversational question-answering systems have limitations. While advanced language models can provide decent answers, they may struggle to fully understand the context and flow of a conversation.
This paper presents a new method to enhance Persian Conversational Question Answering (CQA) systems. It combines the strengths of powerful language models with an additional technique to extract keywords that are specific to the conversation. This extra context helps the language model better understand the user's intent and provide more relevant and coherent responses.
The researchers evaluated this combined approach and found significant improvements in CQA performance compared to using a language model alone. The new method can handle implicit questions, deliver answers tailored to the conversation, and tackle complex questions that rely heavily on the broader context.
Technical Explanation
This paper introduces a novel method to enhance the performance of Persian Conversational Question Answering (CQA) systems. The approach combines the capabilities of Large Language Models (LLMs) with a contextual keyword extraction technique.
LLMs have shown promising results for CQA, but can struggle to fully capture the nuances of conversational contexts. To address this, the researchers developed a technique to extract keywords that are specific to the flow of the conversation. These keywords provide additional contextual information to the LLM, helping it better understand the user's intent and generate more relevant and coherent responses.
The researchers evaluated their combined approach using various metrics and benchmarks. They demonstrated significant improvements in CQA performance compared to an LLM-only baseline. The proposed method effectively handles implicit questions, delivers contextually relevant answers, and tackles complex questions that rely heavily on conversational context.
The findings indicate that the researchers' method outperformed the evaluation benchmarks by up to 8% higher than existing methods and the LLM-only baseline. This suggests that the combination of LLMs and contextual keyword extraction is a promising direction for enhancing the capabilities of CQA systems, particularly in scenarios where understanding the nuances of conversational contexts is crucial.
Critical Analysis
The paper provides a compelling approach for improving Conversational Question Answering (CQA) systems, but there are a few potential limitations and areas for further research that could be explored.
One potential limitation is the focus on the Persian language. While the researchers demonstrate the effectiveness of their method in this context, it would be valuable to investigate how well the approach generalizes to other languages and domains. Expanding the evaluation to include more languages and use cases could help validate the broader applicability of the technique.
Additionally, the paper does not delve into the specific types of questions or conversational contexts that the proposed method excels at handling. A more detailed analysis of the strengths and weaknesses of the approach across different question types and conversation dynamics could provide deeper insights and guide future improvements.
Another area for further research could be exploring the role of iterative conversational query reformulation and knowledge graph-based approaches to enhance the contextual understanding and response generation capabilities of the CQA system. Combining these techniques with the researchers' approach could potentially lead to even more robust and versatile conversational question-answering systems.
Overall, the paper presents a promising direction for improving CQA systems, and the findings suggest that the combination of LLMs and contextual keyword extraction is a valuable area for further exploration and development.
Conclusion
This paper introduces a novel method to enhance the performance of Persian Conversational Question Answering (CQA) systems. By combining the strengths of Large Language Models (LLMs) with a contextual keyword extraction technique, the researchers have demonstrated significant improvements in CQA performance compared to using LLMs alone.
The key innovation of this approach is its ability to capture the nuances of conversational contexts, which can be a challenge for classic CQA systems. By extracting keywords specific to the flow of the conversation, the method provides the LLM with additional context to better understand the user's intent and generate more relevant and coherent responses.
The findings from the researchers' evaluation indicate that this combined approach outperforms existing methods and the LLM-only baseline by up to 8%. This suggests that the integration of LLMs and contextual keyword extraction is a promising direction for advancing the capabilities of CQA systems, particularly in smart city applications where engaging residents through natural conversations is critical.
As cities continue to strive for improved quality of life for their residents, innovative conversational query-answering approaches like the one presented in this paper could play a key role in fostering deeper engagement and better meeting the evolving needs of urban communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Embodied Question Answering via Multi-LLM Systems
Bhrij Patel, Vishnu Sashank Dorbala, Dinesh Manocha, Amrit Singh Bedi
0
0
Embodied Question Answering (EQA) is an important problem, which involves an agent exploring the environment to answer user queries. In the existing literature, EQA has exclusively been studied in single-agent scenarios, where exploration can be time-consuming and costly. In this work, we consider EQA in a multi-agent framework involving multiple large language models (LLM) based agents independently answering queries about a household environment. To generate one answer for each query, we use the individual responses to train a Central Answer Model (CAM) that aggregates responses for a robust answer. Using CAM, we observe a $50%$ higher EQA accuracy when compared against aggregation methods for ensemble LLM, such as voting schemes and debates. CAM does not require any form of agent communication, alleviating it from the associated costs. We ablate CAM with various nonlinear (neural network, random forest, decision tree, XGBoost) and linear (logistic regression classifier, SVM) algorithms. Finally, we present a feature importance analysis for CAM via permutation feature importance (PFI), quantifying CAMs reliance on each independent agent and query context.
6/19/2024

Cost-efficient Knowledge-based Question Answering with Large Language Models
Junnan Dong, Qinggang Zhang, Chuang Zhou, Hao Chen, Daochen Zha, Xiao Huang
0
0
Knowledge-based question answering (KBQA) is widely used in many scenarios that necessitate domain knowledge. Large language models (LLMs) bring opportunities to KBQA, while their costs are significantly higher and absence of domain-specific knowledge during pre-training. We are motivated to combine LLMs and prior small models on knowledge graphs (KGMs) for both inferential accuracy and cost saving. However, it remains challenging since accuracy and cost are not readily combined in the optimization as two distinct metrics. It is also laborious for model selection since different models excel in diverse knowledge. To this end, we propose Coke, a novel cost-efficient strategy for KBQA with LLMs, modeled as a tailored multi-armed bandit problem to minimize calls to LLMs within limited budgets. We first formulate the accuracy expectation with a cluster-level Thompson Sampling for either KGMs or LLMs. A context-aware policy is optimized to further distinguish the expert model subject to the question semantics. The overall decision is bounded by the cost regret according to historical expenditure on failures. Extensive experiments showcase the superior performance of Coke, which moves the Pareto frontier with up to 20.89% saving of GPT-4 fees while achieving a 2.74% higher accuracy on the benchmark datasets.
5/28/2024
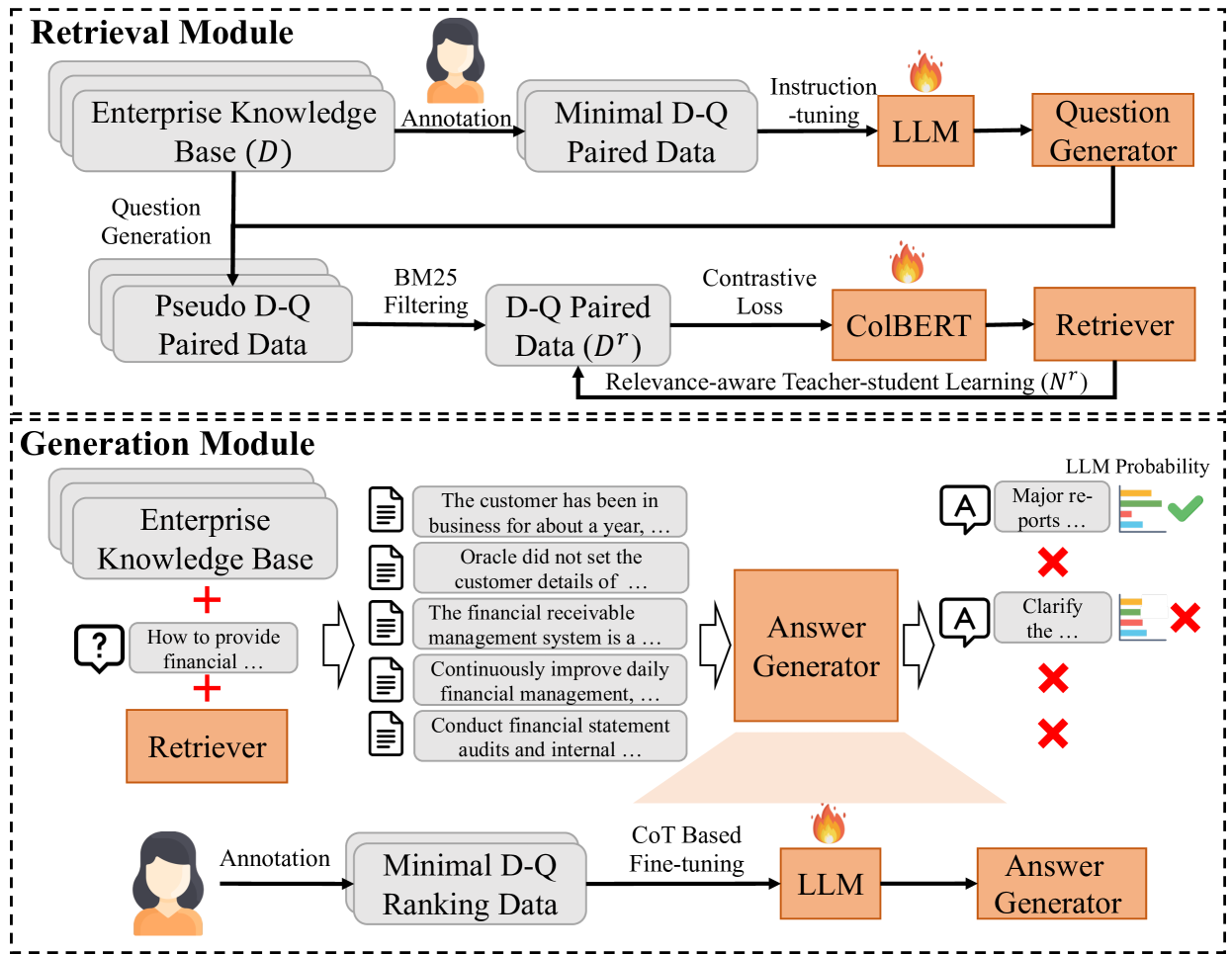
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024

CHIQ: Contextual History Enhancement for Improving Query Rewriting in Conversational Search
Fengran Mo, Abbas Ghaddar, Kelong Mao, Mehdi Rezagholizadeh, Boxing Chen, Qun Liu, Jian-Yun Nie
0
0
In this paper, we study how open-source large language models (LLMs) can be effectively deployed for improving query rewriting in conversational search, especially for ambiguous queries. We introduce CHIQ, a two-step method that leverages the capabilities of LLMs to resolve ambiguities in the conversation history before query rewriting. This approach contrasts with prior studies that predominantly use closed-source LLMs to directly generate search queries from conversation history. We demonstrate on five well-established benchmarks that CHIQ leads to state-of-the-art results across most settings, showing highly competitive performances with systems leveraging closed-source LLMs. Our study provides a first step towards leveraging open-source LLMs in conversational search, as a competitive alternative to the prevailing reliance on commercial LLMs. Data, models, and source code will be publicly available upon acceptance at https://github.com/fengranMark/CHIQ.
6/11/2024