Pre-training Feature Guided Diffusion Model for Speech Enhancement
2406.07646
0
0

Abstract
Speech enhancement significantly improves the clarity and intelligibility of speech in noisy environments, improving communication and listening experiences. In this paper, we introduce a novel pretraining feature-guided diffusion model tailored for efficient speech enhancement, addressing the limitations of existing discriminative and generative models. By integrating spectral features into a variational autoencoder (VAE) and leveraging pre-trained features for guidance during the reverse process, coupled with the utilization of the deterministic discrete integration method (DDIM) to streamline sampling steps, our model improves efficiency and speech enhancement quality. Demonstrating state-of-the-art results on two public datasets with different SNRs, our model outshines other baselines in efficiency and robustness. The proposed method not only optimizes performance but also enhances practical deployment capabilities, without increasing computational demands.
Create account to get full access
Overview
- This paper presents a pre-training feature guided diffusion model for speech enhancement, which aims to improve the quality and intelligibility of speech by removing background noise and distortions.
- The model is pre-trained on a large speech dataset to learn general speech features, and then fine-tuned on a smaller dataset of noisy speech samples.
- The key aspects of the model include a diffusion-based architecture, the use of various speech features to guide the enhancement process, and a novel training strategy that leverages both the pre-trained features and the noisy speech samples.
Plain English Explanation
The goal of this research is to create a system that can take noisy or distorted speech recordings and make them sound clearer and easier to understand. The researchers used a machine learning technique called a "diffusion model" to do this.
A diffusion model works by gradually adding noise to a clean audio signal, and then learning how to reverse that process to remove the noise and restore the original audio. The researchers pre-trained their diffusion model on a large dataset of clean speech, so it could learn the general characteristics of good speech. Then they fine-tuned the model using a smaller dataset of noisy speech samples, so it could learn how to remove specific types of distortions and background noise.
Importantly, the researchers also incorporated various speech features - like pitch, volume, and spectral information - to help guide the model's enhancement process. This allowed the model to focus on the most important aspects of the speech signal and produce higher-quality results.
Overall, this pre-training and feature-guided approach appears to be an effective way to improve speech enhancement, which has important applications in areas like voice-controlled assistants, audio editing, and speech recognition.
Technical Explanation
The core of this paper is a diffusion-based speech enhancement model that is pre-trained on a large dataset of clean speech and then fine-tuned on a smaller dataset of noisy speech samples. The diffusion process gradually adds noise to the clean audio signal, and the model learns to reverse this process to remove the noise and restore the original audio.
To guide the enhancement process, the researchers incorporate various speech features, including fundamental frequency, spectral features, and energy-based features. These features are concatenated with the input audio and used as additional inputs to the diffusion model, helping it focus on the most important aspects of the speech signal.
The pre-training stage involves training the model on a large dataset of clean speech, allowing it to learn general speech characteristics and feature representations. The fine-tuning stage then adapts the pre-trained model to the specific task of speech enhancement using the noisy speech dataset.
The researchers conduct extensive experiments to evaluate their approach, comparing it to various baseline models and state-of-the-art speech enhancement methods. The results show that their pre-training feature-guided diffusion model outperforms the competitors in terms of speech quality and intelligibility metrics.
Critical Analysis
One potential limitation of this approach is the reliance on a pre-trained model, which may not be practical or accessible for all users or applications. The researchers acknowledge this and suggest that future work could explore ways to reduce the dependence on pre-training or make the pre-training process more efficient.
Additionally, the researchers only evaluated their model on a limited set of noise types and speech distortions. It would be valuable to see how the model performs on a wider range of real-world noise conditions, such as reverberant environments, overlapping speakers, or music in the background.
While the researchers provide insights into the model's behavior and the importance of the various speech features, a more detailed analysis of the model's internal workings and the specific mechanisms behind its performance improvements could further our understanding of the approach and its potential applications.
Overall, the pre-training feature-guided diffusion model presented in this paper is a promising technique for speech enhancement, with the potential to benefit a range of audio-based technologies. However, as with any research, there are avenues for further exploration and improvement.
Conclusion
This paper introduces a pre-training feature-guided diffusion model for speech enhancement, which aims to improve the quality and intelligibility of speech by removing background noise and distortions. The key aspects of the model include a diffusion-based architecture, the incorporation of various speech features to guide the enhancement process, and a novel training strategy that leverages both pre-trained features and noisy speech samples.
The researchers demonstrate the effectiveness of their approach through extensive experiments, showing that it outperforms state-of-the-art speech enhancement methods. While the paper highlights some potential limitations and areas for further research, the overall findings suggest that this pre-training feature-guided diffusion model is a promising technique for enhancing speech in a wide range of applications, from voice-controlled assistants to audio editing tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Yuchen Hu, Chen Chen, Ruizhe Li, Qiushi Zhu, Eng Siong Chng
0
0
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech, underexploiting the varying noise information in real world. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner to guide the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks to enhance the noise specificity of conditioner. NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiments on VB-DEMAND dataset show that NASE effectively improves multiple mainstream diffusion SE models, especially on unseen noises.
6/5/2024
🗣️
An Analysis of the Variance of Diffusion-based Speech Enhancement
Bunlong Lay, Timo Gerkmann
0
0
Diffusion models proved to be powerful models for generative speech enhancement. In recent SGMSE+ approaches, training involves a stochastic differential equation for the diffusion process, adding both Gaussian and environmental noise to the clean speech signal gradually. The speech enhancement performance varies depending on the choice of the stochastic differential equation that controls the evolution of the mean and the variance along the diffusion processes when adding environmental and Gaussian noise. In this work, we highlight that the scale of the variance is a dominant parameter for speech enhancement performance and show that it controls the tradeoff between noise attenuation and speech distortions. More concretely, we show that a larger variance increases the noise attenuation and allows for reducing the computational footprint, as fewer function evaluations for generating the estimate are required
6/14/2024
🗣️
AV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement
Ju-Chieh Chou, Chung-Ming Chien, Karen Livescu
0
0
Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement (AVSE), there is not as much ground-truth clean data available; most audio-visual datasets are collected in real-world environments with background noise and reverberation, hampering the development of AVSE. In this work, we introduce AV2Wav, a resynthesis-based audio-visual speech enhancement approach that can generate clean speech despite the challenges of real-world training data. We obtain a subset of nearly clean speech from an audio-visual corpus using a neural quality estimator, and then train a diffusion model on this subset to generate waveforms conditioned on continuous speech representations from AV-HuBERT with noise-robust training. We use continuous rather than discrete representations to retain prosody and speaker information. With this vocoding task alone, the model can perform speech enhancement better than a masking-based baseline. We further fine-tune the diffusion model on clean/noisy utterance pairs to improve the performance. Our approach outperforms a masking-based baseline in terms of both automatic metrics and a human listening test and is close in quality to the target speech in the listening test. Audio samples can be found at https://home.ttic.edu/~jcchou/demo/avse/avse_demo.html.
4/10/2024
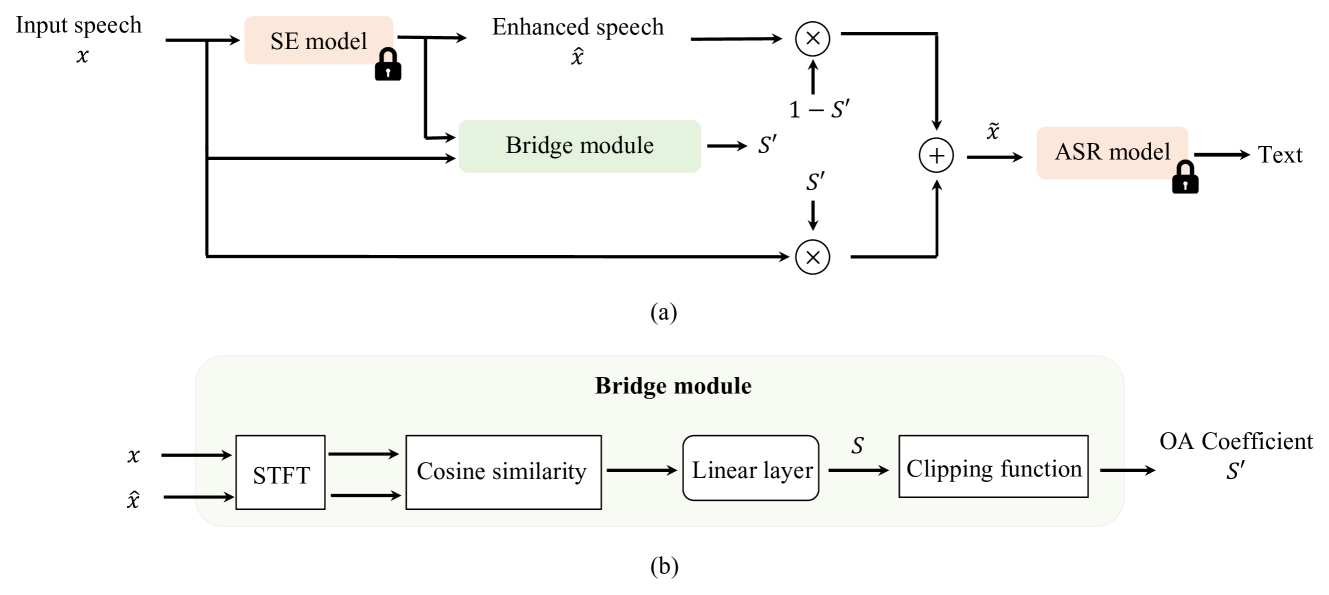
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024