Noise-aware Speech Enhancement using Diffusion Probabilistic Model
2307.08029
0
0
🗣️
Abstract
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech, underexploiting the varying noise information in real world. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner to guide the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks to enhance the noise specificity of conditioner. NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiments on VB-DEMAND dataset show that NASE effectively improves multiple mainstream diffusion SE models, especially on unseen noises.
Create account to get full access
Overview
- This paper proposes a noise-aware speech enhancement (NASE) approach that leverages noise-specific information to guide the reverse process in diffusion models for speech enhancement.
- The key idea is to use a noise classification (NC) model to produce acoustic embeddings as a noise conditioner to guide the reverse denoising process in the diffusion model.
- The authors also devise a multi-task learning scheme to jointly optimize the speech enhancement (SE) and NC tasks, which helps improve the noise specificity of the conditioner.
- NASE is designed as a plug-and-play module that can be generalized to any diffusion-based speech enhancement models.
Plain English Explanation
Speech enhancement (SE) is the process of improving the quality of noisy speech signals. Recent advances in diffusion models, a type of generative AI, have led to a surge of research interest in this area. Diffusion models have great potential for handling a wide range of unseen noises in the real world.
However, existing approaches have mainly focused on the inherent properties of clean speech, without fully leveraging the varying noise information that is present. The proposed NASE approach aims to address this by extracting noise-specific information to guide the reverse denoising process in the diffusion model.
The key idea is to use a noise classification (NC) model to produce acoustic embeddings that can act as a "noise conditioner" to guide the reverse process in the diffusion model. This helps the model better understand the specific type of noise it is dealing with, which can lead to more effective speech enhancement, especially for noises that were not seen during training.
Additionally, the authors use a multi-task learning scheme to jointly optimize the SE and NC tasks, which further enhances the noise specificity of the conditioner. This allows the model to learn more about the relationship between the noise and the clean speech, which can improve its performance.
The NASE approach is designed to be a plug-and-play module, meaning it can be easily integrated with any diffusion-based speech enhancement model. This makes it a versatile and potentially transformative technology for real-world speech enhancement applications.
Technical Explanation
The NASE approach consists of two key components: a noise classification (NC) model and a multi-task learning scheme.
The NC model is used to produce acoustic embeddings that serve as a noise conditioner. These embeddings are then used to guide the reverse denoising process in the diffusion model. The authors hypothesize that by incorporating noise-specific information, the diffusion model can better understand and adapt to the nuances of different types of noise, leading to more effective speech enhancement, especially for unseen noises.
To further enhance the noise specificity of the conditioner, the authors devise a multi-task learning scheme. This involves jointly optimizing the SE and NC tasks, which helps the model learn the relationship between the noise and the clean speech more effectively. The intuition is that by explicitly learning to classify the noise, the model can better incorporate this knowledge into the speech enhancement process.
The NASE approach is designed as a plug-and-play module that can be integrated with any diffusion-based speech enhancement model. This allows the benefits of the noise-aware conditioning and multi-task learning to be easily applied to a wide range of existing and future diffusion SE models.
The authors evaluate the NASE approach on the VB-DEMAND dataset and demonstrate that it can effectively improve the performance of multiple mainstream diffusion SE models, particularly on unseen noises.
Critical Analysis
The NASE approach presents a promising direction for incorporating noise-specific information into diffusion-based speech enhancement models. By using a noise classification model to guide the reverse denoising process, the approach demonstrates the potential to better handle a wider range of real-world noises.
However, the paper does not provide a detailed analysis of the computational complexity or inference time of the NASE approach compared to existing diffusion-based SE methods. This information would be valuable for understanding the practical implications and potential trade-offs of adopting the proposed approach.
Additionally, the authors mention that the NASE approach is designed as a plug-and-play module, but they do not provide specific details on how it can be integrated with different diffusion SE models. A more in-depth discussion of the integration process and potential challenges would be helpful for researchers and practitioners interested in implementing the NASE approach.
Finally, the authors could have explored the potential limitations of the noise classification model and the impact of its performance on the overall speech enhancement results. This could shed light on areas for further research and development to improve the robustness and generalization of the NASE approach.
Conclusion
The NASE approach presented in this paper represents a significant advancement in the field of diffusion-based speech enhancement. By leveraging noise-specific information to guide the reverse denoising process, the approach demonstrates the potential to achieve more effective speech enhancement, particularly for unseen noises in real-world scenarios.
The use of a noise classification model and a multi-task learning scheme are key innovations that allow the NASE approach to better capture the relationship between noise and clean speech, leading to improved performance. Furthermore, the plug-and-play design of the NASE module makes it a versatile solution that can be readily integrated with a variety of diffusion-based speech enhancement models.
While the paper provides a solid technical foundation, further research is needed to address the potential computational and integration challenges, as well as to explore the limitations and areas for improvement of the noise classification model. Nonetheless, the NASE approach represents an exciting step forward in the quest for robust and adaptable speech enhancement solutions powered by the latest advances in generative AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
An Analysis of the Variance of Diffusion-based Speech Enhancement
Bunlong Lay, Timo Gerkmann
0
0
Diffusion models proved to be powerful models for generative speech enhancement. In recent SGMSE+ approaches, training involves a stochastic differential equation for the diffusion process, adding both Gaussian and environmental noise to the clean speech signal gradually. The speech enhancement performance varies depending on the choice of the stochastic differential equation that controls the evolution of the mean and the variance along the diffusion processes when adding environmental and Gaussian noise. In this work, we highlight that the scale of the variance is a dominant parameter for speech enhancement performance and show that it controls the tradeoff between noise attenuation and speech distortions. More concretely, we show that a larger variance increases the noise attenuation and allows for reducing the computational footprint, as fewer function evaluations for generating the estimate are required
6/14/2024

Pre-training Feature Guided Diffusion Model for Speech Enhancement
Yiyuan Yang, Niki Trigoni, Andrew Markham
0
0
Speech enhancement significantly improves the clarity and intelligibility of speech in noisy environments, improving communication and listening experiences. In this paper, we introduce a novel pretraining feature-guided diffusion model tailored for efficient speech enhancement, addressing the limitations of existing discriminative and generative models. By integrating spectral features into a variational autoencoder (VAE) and leveraging pre-trained features for guidance during the reverse process, coupled with the utilization of the deterministic discrete integration method (DDIM) to streamline sampling steps, our model improves efficiency and speech enhancement quality. Demonstrating state-of-the-art results on two public datasets with different SNRs, our model outshines other baselines in efficiency and robustness. The proposed method not only optimizes performance but also enhances practical deployment capabilities, without increasing computational demands.
6/13/2024
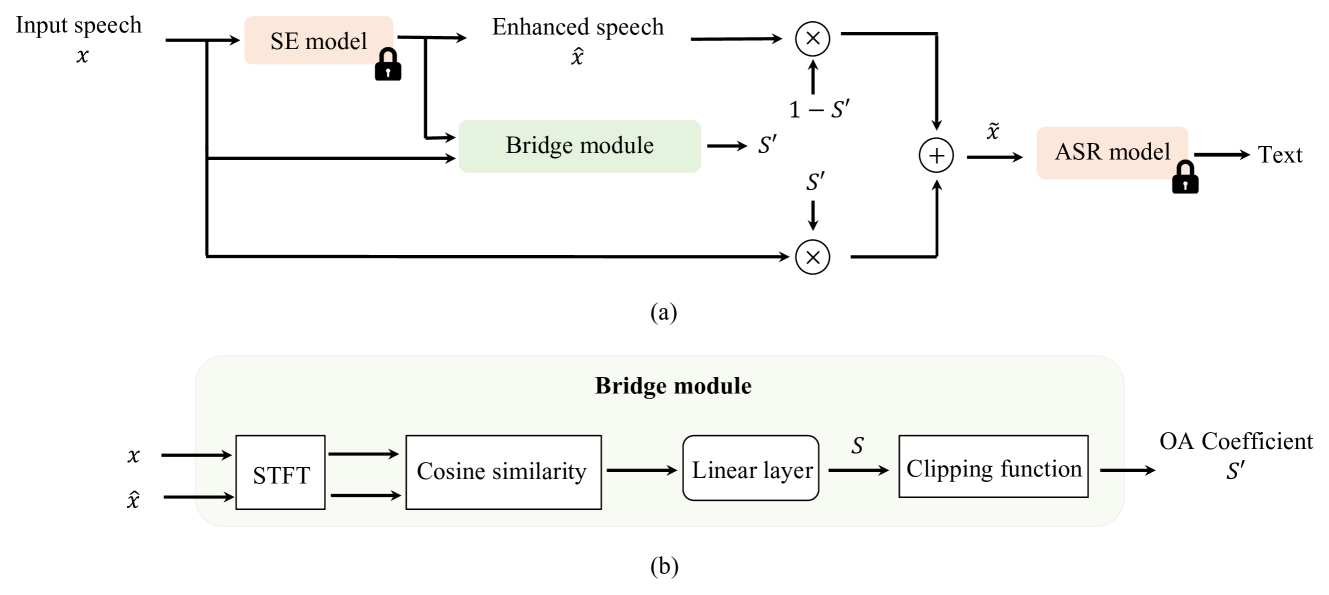
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024

Noise-robust Speech Separation with Fast Generative Correction
Helin Wang, Jesus Villalba, Laureano Moro-Velazquez, Jiarui Hai, Thomas Thebaud, Najim Dehak
0
0
Speech separation, the task of isolating multiple speech sources from a mixed audio signal, remains challenging in noisy environments. In this paper, we propose a generative correction method to enhance the output of a discriminative separator. By leveraging a generative corrector based on a diffusion model, we refine the separation process for single-channel mixture speech by removing noises and perceptually unnatural distortions. Furthermore, we optimize the generative model using a predictive loss to streamline the diffusion model's reverse process into a single step and rectify any associated errors by the reverse process. Our method achieves state-of-the-art performance on the in-domain Libri2Mix noisy dataset, and out-of-domain WSJ with a variety of noises, improving SI-SNR by 22-35% relative to SepFormer, demonstrating robustness and strong generalization capabilities.
6/12/2024