Predictability and Causality in Spanish and English Natural Language Generation

0

Sign in to get full access
Overview
- Explores the predictability and causality in natural language generation (NLG) systems for Spanish and English
- Investigates how linguistic and cultural factors influence the generation process
- Aims to improve understanding of the causal mechanisms underlying NLG
Plain English Explanation
The paper examines how predictable and causal relationships work in natural language generation (NLG) systems for Spanish and English. It looks at how factors like language and culture affect the way these systems generate text. The goal is to better understand the underlying causal mechanisms that drive NLG, which could help improve these systems.
Technical Explanation
The paper investigates the predictability and causality inherent in natural language generation (NLG) systems for Spanish and English. It examines how linguistic and cultural factors, such as word order, semantic relationships, and pragmatic conventions, influence the generation process and the resulting text.
The researchers conducted a series of experiments to quantify the causal effects of various linguistic and contextual variables on the generated text. They used techniques like causal discovery and causal intervention to uncover the underlying causal mechanisms driving the NLG process.
Critical Analysis
The paper provides valuable insights into the predictability and causality of natural language generation systems, but it also acknowledges several limitations. The experiments were conducted on a relatively small dataset, which may limit the generalizability of the findings. Additionally, the paper does not explore the potential biases or ethical implications of the causal relationships uncovered, which could be an important area for further investigation.
Conclusion
This research offers a deeper understanding of the predictability and causality inherent in natural language generation systems for Spanish and English. By uncovering the causal mechanisms underlying these systems, the findings could inform the development of more robust and reliable NLG models, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Predictability and Causality in Spanish and English Natural Language Generation
Andrea Busto-Casti~neira, Francisco J. Gonz'alez-Casta~no, Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez
In recent years, the field of Natural Language Generation (NLG) has been boosted by the recent advances in deep learning technologies. Nonetheless, these new data-intensive methods introduce language-dependent disparities in NLG as the main training data sets are in English. Also, most neural NLG systems use decoder-only (causal) transformer language models, which work well for English, but were not designed with other languages in mind. In this work we depart from the hypothesis that they may introduce generation bias in target languages with less rigid word ordering, subject omission, or different attachment preferences for relative clauses, so that for these target languages other language generation strategies may be more desirable. This paper first compares causal and non-causal language modeling for English and Spanish, two languages with different grammatical structures and over 1.5 billion and 0.5 billion speakers, respectively. For this purpose, we define a novel metric of average causal and non-causal context-conditioned entropy of the grammatical category distribution for both languages as an information-theoretic a priori approach. The evaluation of natural text sources (such as training data) in both languages reveals lower average non-causal conditional entropy in Spanish and lower causal conditional entropy in English. According to this experiment, Spanish is more predictable than English given a non-causal context. Then, by applying a conditional relative entropy metric to text generation experiments, we obtain as insights that the best performance is respectively achieved with causal NLG in English, and with non-causal NLG in Spanish. These insights support further research in NLG in Spanish using bidirectional transformer language models.
Read more8/27/2024

0
A Library for Automatic Natural Language Generation of Spanish Texts
Silvia Garc'ia-M'endez, Milagros Fern'andez-Gavilanes, Enrique Costa-Montenegro, Jonathan Juncal-Mart'inez, F. Javier Gonz'alez-Casta~no
In this article we present a novel system for natural language generation (NLG) of Spanish sentences from a minimum set of meaningful words (such as nouns, verbs and adjectives) which, unlike other state-of-the-art solutions, performs the NLG task in a fully automatic way, exploiting both knowledge-based and statistical approaches. Relying on its linguistic knowledge of vocabulary and grammar, the system is able to generate complete, coherent and correctly spelled sentences from the main word sets presented by the user. The system, which was designed to be integrable, portable and efficient, can be easily adapted to other languages by design and can feasibly be integrated in a wide range of digital devices. During its development we also created a supplementary lexicon for Spanish, aLexiS, with wide coverage and high precision, as well as syntactic trees from a freely available definite-clause grammar. The resulting NLG library has been evaluated both automatically and manually (annotation). The system can potentially be used in different application domains such as augmentative communication and automatic generation of administrative reports or news.
Read more5/28/2024
0
Cause and Effect: Can Large Language Models Truly Understand Causality?
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
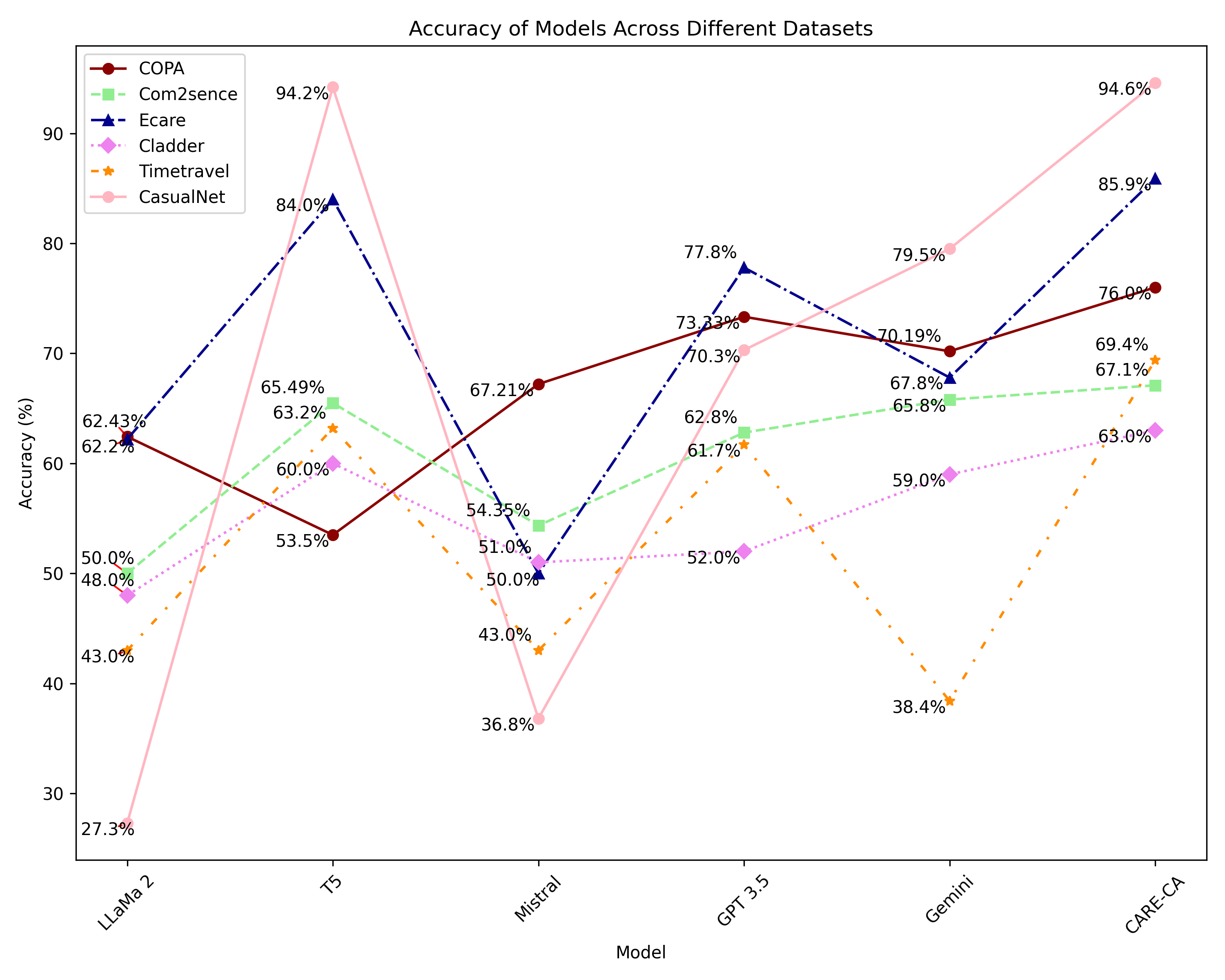
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
Read more4/17/2024
0
End-To-End Causal Effect Estimation from Unstructured Natural Language Data
Nikita Dhawan, Leonardo Cotta, Karen Ullrich, Rahul G. Krishnan, Chris J. Maddison
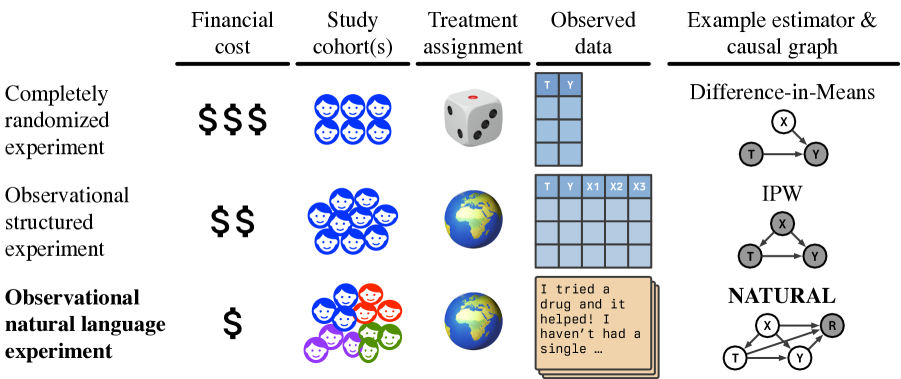
Knowing the effect of an intervention is critical for human decision-making, but current approaches for causal effect estimation rely on manual data collection and structuring, regardless of the causal assumptions. This increases both the cost and time-to-completion for studies. We show how large, diverse observational text data can be mined with large language models (LLMs) to produce inexpensive causal effect estimates under appropriate causal assumptions. We introduce NATURAL, a novel family of causal effect estimators built with LLMs that operate over datasets of unstructured text. Our estimators use LLM conditional distributions (over variables of interest, given the text data) to assist in the computation of classical estimators of causal effect. We overcome a number of technical challenges to realize this idea, such as automating data curation and using LLMs to impute missing information. We prepare six (two synthetic and four real) observational datasets, paired with corresponding ground truth in the form of randomized trials, which we used to systematically evaluate each step of our pipeline. NATURAL estimators demonstrate remarkable performance, yielding causal effect estimates that fall within 3 percentage points of their ground truth counterparts, including on real-world Phase 3/4 clinical trials. Our results suggest that unstructured text data is a rich source of causal effect information, and NATURAL is a first step towards an automated pipeline to tap this resource.
Read more8/26/2024