Predicting Affective States from Screen Text Sentiment

0
🔍
Sign in to get full access
Overview
- Mobile sensing technologies enable the study of physiological and behavioral phenomena through smartphone sensor data.
- This provides insights into individuals' physical and mental states, enabling personalized treatment and interventions.
- However, the potential of analyzing the textual content viewed on smartphones to predict affective states remains underexplored.
Plain English Explanation
The increasing use of smartphones has made it possible to collect data about people's physical and mental states in real-time, without them having to do anything out of the ordinary. This data can be used to understand individuals better and provide personalized support or treatments.
One area that hasn't been studied much is how the text people see and interact with on their phone screens might influence their mood and emotions. To explore this, researchers looked at data from a study of Australian university students in 2023. They used different analysis techniques, including a large language model, to understand the relationship between the text people see on their phones and their emotional states.
The key finding was that the most advanced analysis technique, called "multi-shot prompting," was the most effective at predicting people's emotions based on the text they view on their phones. This highlights the importance of considering the broader context, not just the specific words, when trying to understand how someone's mood might be affected by what they see on their device.
Overall, this research suggests that incorporating data about the text and sentiment expressed on people's phones could be valuable for better understanding their well-being and developing more personalized support.
Technical Explanation
The researchers used data from a digital phenotyping study of Australian university students conducted in 2023. They employed three different analytical techniques to explore the relationship between the textual content users are exposed to on their smartphone screens and their affective states:
-
Linear Regression: A standard statistical modeling approach that examines the linear relationship between the textual content and affective states.
-
Zero-Shot Prompting: A technique that uses a large language model (LLM) to generate predictions without any task-specific training.
-
Multi-Shot Prompting: An approach that leverages the contextual understanding of the LLM by providing relevant prompts and examples to guide the model's predictions.
The findings indicate that the multi-shot prompting approach substantially outperforms both the linear regression and zero-shot prompting methods in predicting affective states from screen text. This highlights the importance of considering the broader context, rather than just the specific words, when trying to understand how textual content may influence a person's mood and emotions.
Critical Analysis
The paper acknowledges several limitations and areas for further research. For instance, the study was conducted with a specific population (Australian university students) and the findings may not generalize to other demographics or cultural contexts. Additionally, the researchers note that the textual content analyzed was limited to what was visible on the smartphone screen, and did not capture the full context of how users were interacting with and interpreting the information.
While the multi-shot prompting approach showed promising results, the researchers emphasize the need for further investigation into the nuances of how language models can be leveraged to understand the complex relationship between textual content and affective states. There may be opportunities to explore more sophisticated techniques, such as incorporating multimodal data (e.g., combining text with sensor data or behavioral patterns) to gain a more comprehensive understanding of the factors influencing an individual's emotional well-being.
Conclusion
This research suggests that analyzing the textual content users are exposed to on their smartphones could provide valuable insights into their affective states and overall well-being. The finding that multi-shot prompting with a large language model significantly outperforms more basic analytical approaches highlights the importance of considering contextual factors when predicting emotional states from digital data.
As mobile sensing technologies continue to advance, incorporating textual and sentiment data into models for understanding human behavior and mental health could lead to more personalized and effective interventions. This study lays the groundwork for future research to further explore the potential of leveraging language-based data to support individual and societal well-being.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Predicting Affective States from Screen Text Sentiment
Songyan Teng, Tianyi Zhang, Simon D'Alfonso, Vassilis Kostakos
The proliferation of mobile sensing technologies has enabled the study of various physiological and behavioural phenomena through unobtrusive data collection from smartphone sensors. This approach offers real-time insights into individuals' physical and mental states, creating opportunities for personalised treatment and interventions. However, the potential of analysing the textual content viewed on smartphones to predict affective states remains underexplored. To better understand how the screen text that users are exposed to and interact with can influence their affects, we investigated a subset of data obtained from a digital phenotyping study of Australian university students conducted in 2023. We employed linear regression, zero-shot, and multi-shot prompting using a large language model (LLM) to analyse relationships between screen text and affective states. Our findings indicate that multi-shot prompting substantially outperforms both linear regression and zero-shot prompting, highlighting the importance of context in affect prediction. We discuss the value of incorporating textual and sentiment data for improving affect prediction, providing a basis for future advancements in understanding smartphone use and wellbeing.
Read more8/26/2024
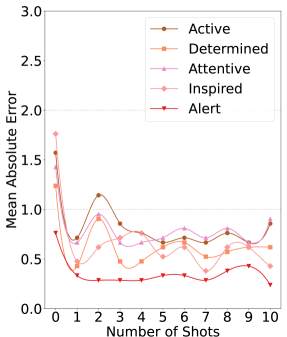
0
Leveraging LLMs to Predict Affective States via Smartphone Sensor Features
Tianyi Zhang, Songyan Teng, Hong Jia, Simon D'Alfonso
As mental health issues for young adults present a pressing public health concern, daily digital mood monitoring for early detection has become an important prospect. An active research area, digital phenotyping, involves collecting and analysing data from personal digital devices such as smartphones (usage and sensors) and wearables to infer behaviours and mental health. Whilst this data is standardly analysed using statistical and machine learning approaches, the emergence of large language models (LLMs) offers a new approach to make sense of smartphone sensing data. Despite their effectiveness across various domains, LLMs remain relatively unexplored in digital mental health, particularly in integrating mobile sensor data. Our study aims to bridge this gap by employing LLMs to predict affect outcomes based on smartphone sensing data from university students. We demonstrate the efficacy of zero-shot and few-shot embedding LLMs in inferring general wellbeing. Our findings reveal that LLMs can make promising predictions of affect measures using solely smartphone sensing data. This research sheds light on the potential of LLMs for affective state prediction, emphasizing the intricate link between smartphone behavioral patterns and affective states. To our knowledge, this is the first work to leverage LLMs for affective state prediction and digital phenotyping tasks.
Read more7/12/2024
0
Towards Understanding Emotions for Engaged Mental Health Conversations
Kellie Yu Hui Sim, Kohleen Tijing Fortuno, Kenny Tsu Wei Choo
Providing timely support and intervention is crucial in mental health settings. As the need to engage youth comfortable with texting increases, mental health providers are exploring and adopting text-based media such as chatbots, community-based forums, online therapies with licensed professionals, and helplines operated by trained responders. To support these text-based media for mental health--particularly for crisis care--we are developing a system to perform passive emotion-sensing using a combination of keystroke dynamics and sentiment analysis. Our early studies of this system posit that the analysis of short text messages and keyboard typing patterns can provide emotion information that may be used to support both clients and responders. We use our preliminary findings to discuss the way forward for applying AI to support mental health providers in providing better care.
Read more6/18/2024
🐍
0
PSentScore: Evaluating Sentiment Polarity in Dialogue Summarization
Yongxin Zhou, Fabien Ringeval, Franc{c}ois Portet
Automatic dialogue summarization is a well-established task with the goal of distilling the most crucial information from human conversations into concise textual summaries. However, most existing research has predominantly focused on summarizing factual information, neglecting the affective content, which can hold valuable insights for analyzing, monitoring, or facilitating human interactions. In this paper, we introduce and assess a set of measures PSentScore, aimed at quantifying the preservation of affective content in dialogue summaries. Our findings indicate that state-of-the-art summarization models do not preserve well the affective content within their summaries. Moreover, we demonstrate that a careful selection of the training set for dialogue samples can lead to improved preservation of affective content in the generated summaries, albeit with a minor reduction in content-related metrics.
Read more5/6/2024