Predicting fluorescent labels in label-free microscopy images with pix2pix and adaptive loss in Light My Cells challenge

0
Sign in to get full access
Overview
- This paper describes a method for predicting fluorescent labels in label-free microscopy images using a pix2pix model with an adaptive loss function.
- The researchers applied this approach to the Light My Cells challenge, which aims to generate fluorescent protein labels from unlabeled microscopy images.
- The proposed method can help reduce the need for fluorescent labeling, which can be time-consuming and perturb cellular processes.
Plain English Explanation
Microscopes are commonly used to study cells and other small biological structures. Traditionally, scientists would add fluorescent dyes or proteins to cells to make specific structures visible under the microscope. However, this labeling process can be difficult and can sometimes interfere with the natural behavior of the cells.
In this research, the team developed a way to predict what the fluorescent labels would look like, without actually adding them to the cells. They used a type of machine learning model called pix2pix, which is good at converting one type of image into another. The researchers also used an "adaptive loss" function, which helped the model learn more effectively.
The researchers tested their approach on a dataset called "Light My Cells," where the goal is to generate fluorescent protein labels from regular microscope images. By being able to predict the fluorescent labels, scientists may be able to study cells in a more natural state, without the need for labeling. This could lead to new discoveries about how cells function.
Technical Explanation
The researchers used a pix2pix architecture, a type of conditional generative adversarial network (cGAN), to convert label-free microscopy images into predicted fluorescent label images. Pix2pix models are known for their ability to translate between different image domains.
To improve the model's performance, the researchers introduced an adaptive loss function. This loss function adapts to the complexity of different regions within the image, placing more emphasis on challenging areas that are difficult to predict accurately.
The model was trained and evaluated on the Light My Cells dataset, which contains paired label-free and fluorescent microscopy images of cells. The researchers compared their approach to a baseline pix2pix model without the adaptive loss, as well as other state-of-the-art methods for fluorescence prediction.
Critical Analysis
The researchers acknowledge several limitations of their approach. First, the method relies on the availability of paired label-free and fluorescent microscopy images, which may not always be the case in real-world scenarios. Second, the adaptive loss function, while improving performance, adds complexity to the model and training process.
Additionally, the researchers note that their method may not generalize well to all types of fluorescent labels or cell types. Further research is needed to understand the broader applicability of the approach and its performance on more diverse datasets.
It would also be valuable to investigate the model's interpretability, as understanding which image features the model uses to predict fluorescent labels could provide insights into the underlying biological processes.
Conclusion
This research presents a promising approach for predicting fluorescent labels in label-free microscopy images using a pix2pix model with an adaptive loss function. By reducing the need for fluorescent labeling, this method could enable the study of cells in a more natural state, potentially leading to new discoveries in cell biology. However, further research is needed to address the limitations and expand the applicability of the approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Predicting fluorescent labels in label-free microscopy images with pix2pix and adaptive loss in Light My Cells challenge
Han Liu, Hao Li, Jiacheng Wang, Yubo Fan, Zhoubing Xu, Ipek Oguz
Fluorescence labeling is the standard approach to reveal cellular structures and other subcellular constituents for microscopy images. However, this invasive procedure may perturb or even kill the cells and the procedure itself is highly time-consuming and complex. Recently, in silico labeling has emerged as a promising alternative, aiming to use machine learning models to directly predict the fluorescently labeled images from label-free microscopy. In this paper, we propose a deep learning-based in silico labeling method for the Light My Cells challenge. Built upon pix2pix, our proposed method can be trained using the partially labeled datasets with an adaptive loss. Moreover, we explore the effectiveness of several training strategies to handle different input modalities, such as training them together or separately. The results show that our method achieves promising performance for in silico labeling. Our code is available at https://github.com/MedICL-VU/LightMyCells.
Read more6/26/2024

0
Patch-Based Encoder-Decoder Architecture for Automatic Transmitted Light to Fluorescence Imaging Transition: Contribution to the LightMyCells Challenge
Marek Wodzinski, Henning Muller
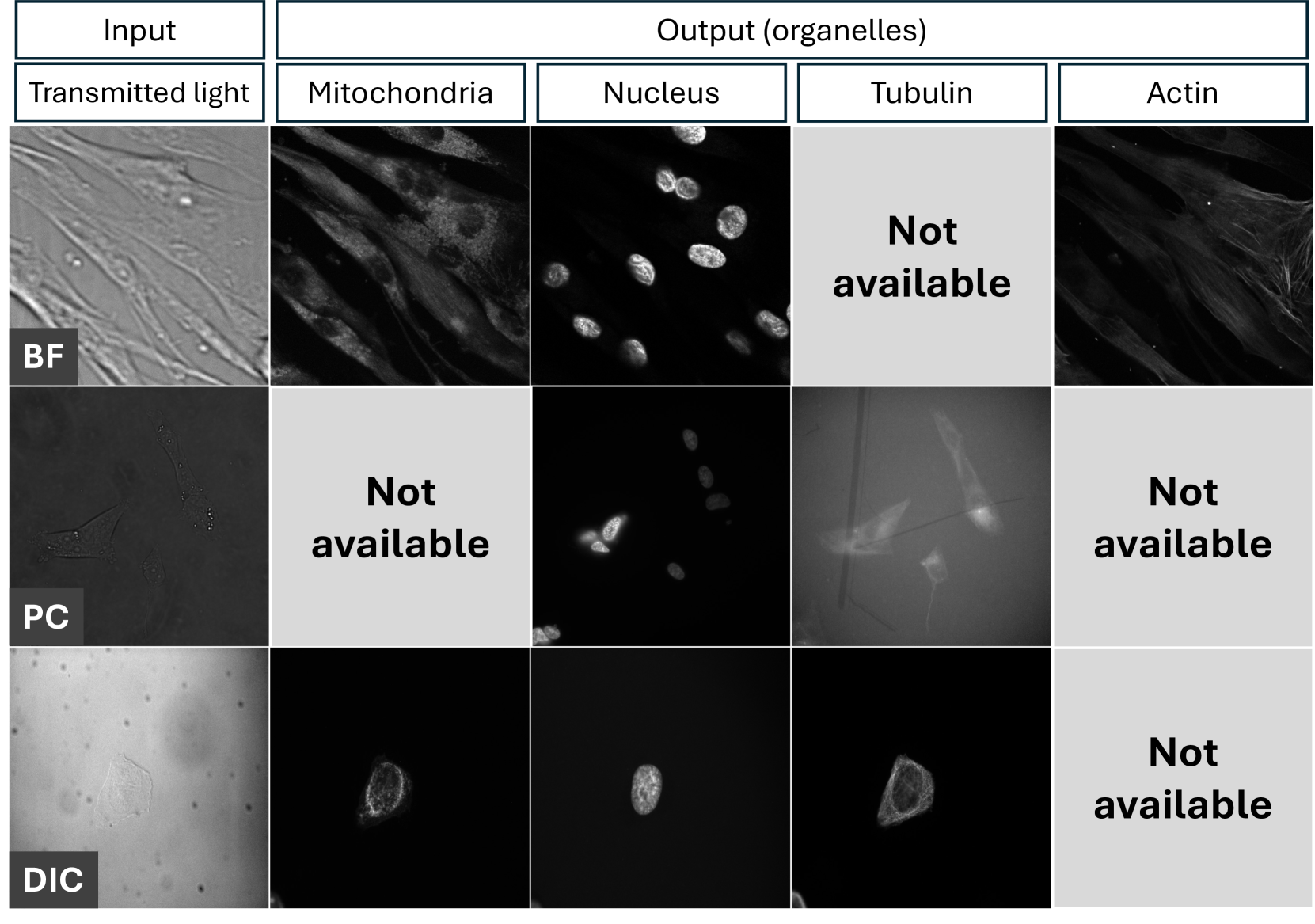
Automatic prediction of fluorescently labeled organelles from label-free transmitted light input images is an important, yet difficult task. The traditional way to obtain fluorescence images is related to performing biochemical labeling which is time-consuming and costly. Therefore, an automatic algorithm to perform the task based on the label-free transmitted light microscopy could be strongly beneficial. The importance of the task motivated researchers from the France-BioImaging to organize the LightMyCells challenge where the goal is to propose an algorithm that automatically predicts the fluorescently labeled nucleus, mitochondria, tubulin, and actin, based on the input consisting of bright field, phase contrast, or differential interference contrast microscopic images. In this work, we present the contribution of the AGHSSO team based on a carefully prepared and trained encoder-decoder deep neural network that achieves a considerable score in the challenge, being placed among the best-performing teams.
Read more6/4/2024

0
Semi-supervised variational autoencoder for cell feature extraction in multiplexed immunofluorescence images
Piumi Sandarenu, Julia Chen, Iveta Slapetova, Lois Browne, Peter H. Graham, Alexander Swarbrick, Ewan K. A. Millar, Yang Song, Erik Meijering
Advancements in digital imaging technologies have sparked increased interest in using multiplexed immunofluorescence (mIF) images to visualise and identify the interactions between specific immunophenotypes with the tumour microenvironment at the cellular level. Current state-of-the-art multiplexed immunofluorescence image analysis pipelines depend on cell feature representations characterised by morphological and stain intensity-based metrics generated using simple statistical and machine learning-based tools. However, these methods are not capable of generating complex representations of cells. We propose a deep learning-based cell feature extraction model using a variational autoencoder with supervision using a latent subspace to extract cell features in mIF images. We perform cell phenotype classification using a cohort of more than 44,000 multiplexed immunofluorescence cell image patches extracted across 1,093 tissue microarray cores of breast cancer patients, to demonstrate the success of our model against current and alternative methods.
Read more7/1/2024
↗️
0
A Novel Generative Artificial Intelligence Method for Interference Study on Multiplex Brightfield Immunohistochemistry Images
Satarupa Mukherjee, Jim Martin, Yao Nie
Multiplex brightfield imaging offers the advantage of simultaneously analyzing multiple biomarkers on a single slide, as opposed to single biomarker labeling on multiple consecutive slides. To accurately analyze multiple biomarkers localized at the same cellular compartment, two representative biomarker sets were selected as assay models - cMET-PDL1-EGFR and CD8-LAG3-PDL1, where all three biomarkers can co-localize on the cell membrane. One of the most crucial preliminary stages for analyzing such assay is identifying each unique chromogen on individual cells. This is a challenging problem due to the co-localization of membrane stains from all the three biomarkers. It requires advanced color unmixing for creating the equivalent singleplex images from each triplex image for each biomarker. In this project, we developed a cycle-Generative Adversarial Network (cycle-GAN) method for unmixing the triplex images generated from the above-mentioned assays. Three different models were designed to generate the singleplex image for each of the three stains Tamra (purple), QM-Dabsyl (yellow) and Green. A notable novelty of our approach was that the input to the network were images in the optical density domain instead of conventionally used RGB images. The use of the optical density domain helped in reducing the blurriness of the synthetic singleplex images, which was often observed when the network was trained on RGB images. The cycle-GAN models were validated on 10,800 lung, gastric and colon images for the cMET-PDL1-EGFR assay and 3600 colon images for the CD8-LAG3-PDL1 assay. Visual as well as quantified assessments demonstrated that the proposed method is effective and efficient when compared with the manual reviewing results and is readily applicable to various multiplex assays.
Read more8/16/2024