Predictive Simultaneous Interpretation: Harnessing Large Language Models for Democratizing Real-Time Multilingual Communication

0
💬
Sign in to get full access
Overview
- This study introduces a novel approach to simultaneous interpretation that leverages the predictive capabilities of Large Language Models (LLMs).
- The researchers present a new algorithm that generates real-time translations by predicting speaker utterances and expanding multiple possibilities in a tree-like structure.
- This method aims to overcome the structural differences between languages more effectively than existing systems, potentially leading to more natural and fluent translations with minimal latency.
Plain English Explanation
The paper describes a groundbreaking way to do simultaneous interpretation, which is the process of translating spoken language in real-time. The key innovation is using large language models - powerful AI systems that can understand and generate human-like text.
The researchers have developed an algorithm that predicts what the speaker will say next and then generates multiple possible translations in a branching, tree-like structure. This allows the system to be highly flexible and adapt to the differences between languages, potentially resulting in translations that sound more natural and smooth, with very little delay.
The paper's main goal is to share this innovative concept with the research community, in the hopes of inspiring further development and improvement in this area. Simultaneous interpretation is an important tool for enabling multilingual communication, and this new approach could make it more accessible and effective.
Technical Explanation
The paper presents a novel algorithm that leverages the predictive capabilities of Large Language Models to perform simultaneous interpretation. The key innovation is the use of a tree-like structure to generate multiple possible translations in real-time, expanding on the speaker's utterances.
The algorithm works by first predicting the speaker's next words using the LLM. It then generates a set of possible translations for those predicted words, creating a branching tree of translation hypotheses. As the speaker continues, the algorithm expands this tree, continuously updating the translations to match the evolving utterance.
This approach is intended to overcome the challenges posed by the structural differences between languages. By generating multiple translation options and dynamically updating them, the system can adapt more flexibly than traditional simultaneous interpretation techniques. The researchers provide theoretical analysis and illustrative examples to demonstrate the potential for this method to enable more natural, fluent translations with minimal latency.
Critical Analysis
The paper presents a promising new direction for simultaneous interpretation, but it also acknowledges several potential implementation challenges and areas for further research. One key concern is the computational complexity of maintaining and expanding the translation tree in real-time, which could limit the scalability of the approach.
Additionally, the paper does not provide empirical evaluation of the system's performance compared to existing simultaneous interpretation methods. While the theoretical analysis is compelling, more practical testing and user studies would be needed to fully assess the benefits and limitations of this approach.
Another potential issue is the reliance on the accuracy and robustness of the underlying LLM. If the language model makes incorrect predictions or struggles with certain linguistic phenomena, this could negatively impact the quality of the generated translations. Strategies for mitigating such model vulnerabilities would need to be explored.
Despite these caveats, the core concept of leveraging LLM capabilities for simultaneous interpretation is a promising direction that warrants further investigation. By encouraging readers to think critically about the research and its implications, the paper lays the groundwork for future advancements in this important field.
Conclusion
This study introduces an innovative approach to simultaneous interpretation that directly harnesses the predictive power of Large Language Models. The proposed algorithm generates real-time translations by dynamically expanding a tree of translation hypotheses, aiming to overcome language-specific structural differences more effectively than existing systems.
While the paper acknowledges various implementation challenges, the theoretical analysis and illustrative examples suggest that this technique could lead to more natural, fluent translations with minimal latency. By sharing this concept with the academic community, the researchers hope to inspire further research and development in this area, ultimately contributing to the democratization of multilingual communication.
The potential of this approach lies in its ability to adapt to the nuances of different languages, potentially making simultaneous interpretation more accessible and effective across a wide range of applications, from international conferences to cross-cultural business negotiations. As the field of natural language processing continues to advance, innovations like this could play a crucial role in breaking down language barriers and fostering greater global connectivity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Predictive Simultaneous Interpretation: Harnessing Large Language Models for Democratizing Real-Time Multilingual Communication
Kurando Iida, Kenjiro Mimura, Nobuo Ito
This study introduces a groundbreaking approach to simultaneous interpretation by directly leveraging the predictive capabilities of Large Language Models (LLMs). We present a novel algorithm that generates real-time translations by predicting speaker utterances and expanding multiple possibilities in a tree-like structure. This method demonstrates unprecedented flexibility and adaptability, potentially overcoming the structural differences between languages more effectively than existing systems. Our theoretical analysis, supported by illustrative examples, suggests that this approach could lead to more natural and fluent translations with minimal latency. The primary purpose of this paper is to share this innovative concept with the academic community, stimulating further research and development in this field. We discuss the theoretical foundations, potential advantages, and implementation challenges of this technique, positioning it as a significant step towards democratizing multilingual communication.
Read more7/22/2024
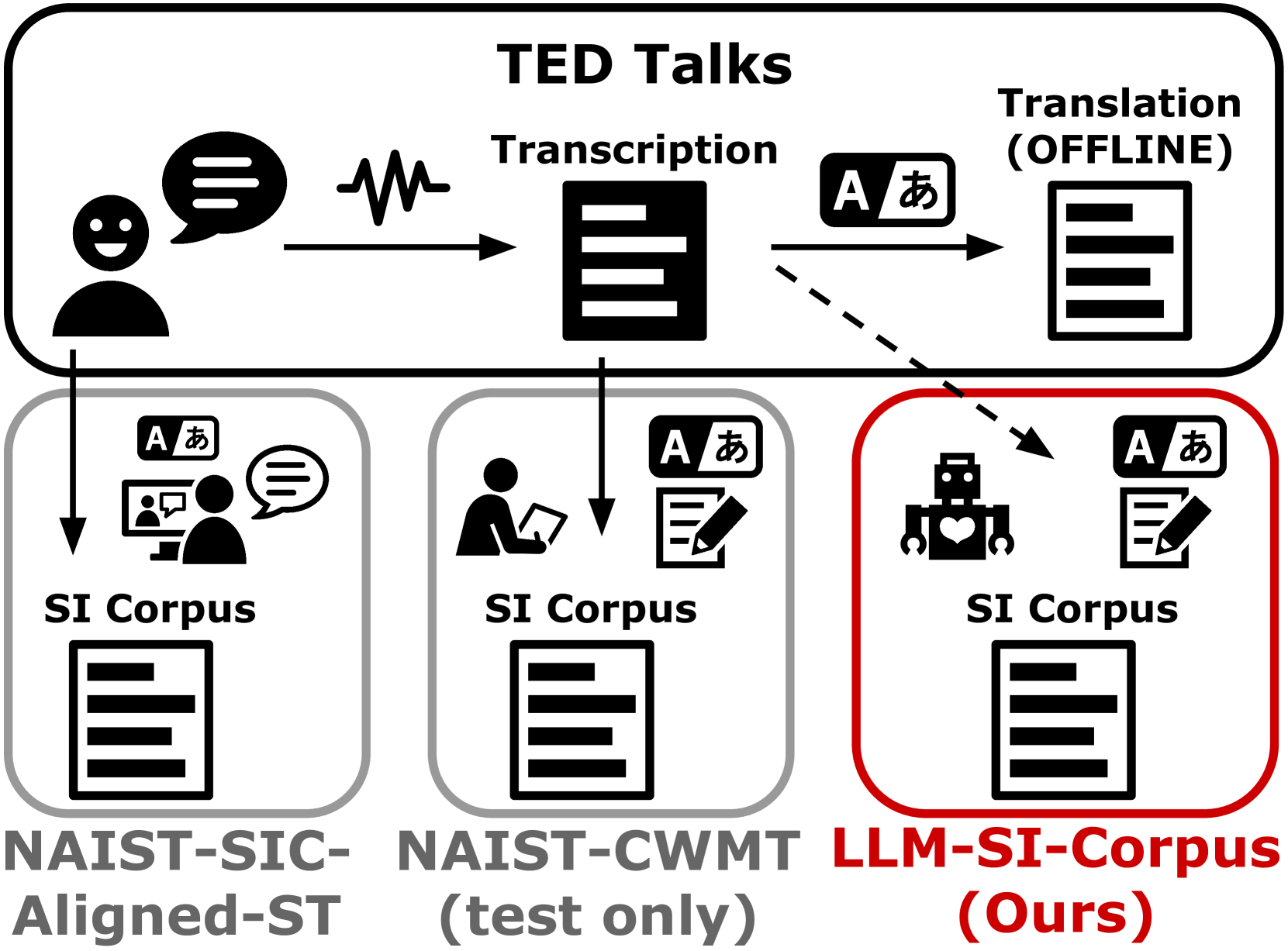
0
Simultaneous Interpretation Corpus Construction by Large Language Models in Distant Language Pair
Yusuke Sakai, Mana Makinae, Hidetaka Kamigaito, Taro Watanabe
In Simultaneous Machine Translation (SiMT) systems, training with a simultaneous interpretation (SI) corpus is an effective method for achieving high-quality yet low-latency systems. However, it is very challenging to curate such a corpus due to limitations in the abilities of annotators, and hence, existing SI corpora are limited. Therefore, we propose a method to convert existing speech translation corpora into interpretation-style data, maintaining the original word order and preserving the entire source content using Large Language Models (LLM-SI-Corpus). We demonstrate that fine-tuning SiMT models in text-to-text and speech-to-text settings with the LLM-SI-Corpus reduces latencies while maintaining the same level of quality as the models trained with offline datasets. The LLM-SI-Corpus is available at url{https://github.com/yusuke1997/LLM-SI-Corpus}.
Read more4/19/2024
💬
0
Conversational SimulMT: Efficient Simultaneous Translation with Large Language Models
Minghan Wang, Thuy-Trang Vu, Yuxia Wang, Ehsan Shareghi, Gholamreza Haffari
Simultaneous machine translation (SimulMT) presents a challenging trade-off between translation quality and latency. Recent studies have shown that LLMs can achieve good performance in SimulMT tasks. However, this often comes at the expense of high inference cost and latency. In this paper, we propose a conversational SimulMT framework to enhance the inference efficiency of LLM-based SimulMT through multi-turn-dialogue-based decoding. Our experiments with Llama2-7b-chat on two SimulMT benchmarks demonstrate the superiority of LLM in translation quality while achieving comparable computational latency to specialized SimulMT models.
Read more6/24/2024

0
Simul-LLM: A Framework for Exploring High-Quality Simultaneous Translation with Large Language Models
Victor Agostinelli, Max Wild, Matthew Raffel, Kazi Ahmed Asif Fuad, Lizhong Chen
Large language models (LLMs) with billions of parameters and pretrained on massive amounts of data are now capable of near or better than state-of-the-art performance in a variety of downstream natural language processing tasks. Neural machine translation (NMT) is one such task that LLMs have been applied to with great success. However, little research has focused on applying LLMs to the more difficult subset of NMT called simultaneous translation (SimulMT), where translation begins before the entire source context is available to the model. In this paper, we address key challenges facing LLMs fine-tuned for SimulMT, validate classical SimulMT concepts and practices in the context of LLMs, explore adapting LLMs that are fine-tuned for NMT to the task of SimulMT, and introduce Simul-LLM, the first open-source fine-tuning and evaluation pipeline development framework for LLMs focused on SimulMT.
Read more7/8/2024