Simul-LLM: A Framework for Exploring High-Quality Simultaneous Translation with Large Language Models
2312.04691
0
0

Abstract
Large language models (LLMs) with billions of parameters and pretrained on massive amounts of data are now capable of near or better than state-of-the-art performance in a variety of downstream natural language processing tasks. Neural machine translation (NMT) is one such task that LLMs have been applied to with great success. However, little research has focused on applying LLMs to the more difficult subset of NMT called simultaneous translation (SimulMT), where translation begins before the entire source context is available to the model. In this paper, we address key challenges facing LLMs fine-tuned for SimulMT, validate classical SimulMT concepts and practices in the context of LLMs, explore adapting LLMs that are fine-tuned for NMT to the task of SimulMT, and introduce Simul-LLM, the first open-source fine-tuning and evaluation pipeline development framework for LLMs focused on SimulMT.
Create account to get full access
Overview
- This paper presents a framework called "Simul-LLM" for exploring high-quality simultaneous translation using large language models (LLMs).
- The authors investigate the capabilities of LLMs for real-time, low-latency translation, which is a critical task for many applications.
- The paper explores different approaches to leveraging LLMs for simultaneous translation, including techniques like simultaneous masking and FlyFusion.
Plain English Explanation
The paper introduces a new framework called "Simul-LLM" that explores how large language models (LLMs) can be used for high-quality, real-time translation. LLMs are powerful AI models that can understand and generate human-like text across many languages. The researchers wanted to see if these models could be adapted for simultaneous translation, where the translation happens as the original text is being spoken or written.
Simultaneous translation is an important capability for many applications, like video calls, live presentations, and interpretations at conferences. But it's a challenging task because the translator needs to keep up with the input and provide accurate translations quickly, without any delays.
The paper examines different techniques the researchers tried to make LLMs better at simultaneous translation. For example, they experimented with "simultaneous masking", which involves hiding parts of the input text to force the model to predict the translation incrementally. They also explored an approach called "FlyFusion" that combines the strengths of different translation models.
Overall, the goal of this work is to push the boundaries of what LLMs can do for real-time, high-quality translation, which could have a big impact on how we communicate across language barriers in the digital age.
Technical Explanation
The Simul-LLM framework proposed in this paper explores ways to leverage large language models (LLMs) for simultaneous translation - the ability to translate text or speech in real-time with low latency. This is a crucial task for many applications, but a challenging one for traditional machine translation models.
The authors investigate several approaches to adapt LLMs for simultaneous translation:
-
Simultaneous Masking: This technique involves incrementally revealing the input text to the model, forcing it to predict the translation in a step-by-step fashion rather than waiting for the full input. This mimics the constraints of real-time translation. The paper compares different masking strategies and their impact on translation quality and latency.
-
FlyFusion: This method combines the strengths of different translation models, including LLMs and more specialized machine translation models. The models work in parallel, with the FlyFusion module dynamically selecting the best output to use based on factors like translation quality and latency.
-
Fine-tuning Multilingual LLMs: The researchers explore how well off-the-shelf multilingual LLMs, such as those studied in this paper, can be fine-tuned for simultaneous translation tasks, and the tradeoffs involved.
Through extensive experiments on benchmark datasets, the paper provides insights into the capabilities and limitations of LLMs for simultaneous translation. The results demonstrate the potential of the Simul-LLM framework to enable high-quality, low-latency translation, while also highlighting areas for further research and improvement.
Critical Analysis
The Simul-LLM framework represents an important step forward in leveraging large language models for real-time translation. However, the paper also acknowledges several caveats and areas for further research:
-
Latency vs. Quality Tradeoffs: The techniques explored, like simultaneous masking, do improve latency, but there is still a tradeoff with translation quality. More work is needed to find the right balance for different use cases.
-
Multilingual Limitations: While multilingual LLMs show promise, the paper finds they may still struggle with less-resourced language pairs. Continued research is needed to improve the multilingual capabilities of LLMs.
-
Specialized Translation Knowledge: The authors note that while LLMs can leverage their broad language understanding, more specialized translation knowledge may still be needed for high-quality simultaneous translation in some domains.
-
Evaluation Metrics: The paper uses standard translation metrics, but acknowledges the need for new evaluation frameworks that capture the unique requirements of simultaneous translation, such as latency.
Overall, the Simul-LLM framework represents an important contribution, but there is still significant room for improvement in making LLMs truly reliable and effective for real-time, high-quality translation across diverse applications and language pairs.
Conclusion
This paper presents the Simul-LLM framework, which explores novel ways to leverage the power of large language models (LLMs) for simultaneous translation - the ability to translate text or speech in real-time with low latency. The researchers investigate techniques like simultaneous masking and FlyFusion to adapt LLMs for this challenging task.
The results demonstrate the potential of LLMs for high-quality, low-latency translation, but also highlight key tradeoffs and limitations that require further research. Areas for improvement include better balancing latency and translation quality, enhancing multilingual capabilities, and developing specialized translation knowledge within LLMs.
As language barriers continue to be a major obstacle in our globalized world, the work presented in this paper represents an important step forward in bridging those gaps through the power of large language models and advanced translation techniques. Continued advancements in this area could have significant implications for how we communicate and collaborate across linguistic boundaries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Conversational SimulMT: Efficient Simultaneous Translation with Large Language Models
Minghan Wang, Thuy-Trang Vu, Yuxia Wang, Ehsan Shareghi, Gholamreza Haffari
0
0
Simultaneous machine translation (SimulMT) presents a challenging trade-off between translation quality and latency. Recent studies have shown that LLMs can achieve good performance in SimulMT tasks. However, this often comes at the expense of high inference cost and latency. In this paper, we propose a conversational SimulMT framework to enhance the inference efficiency of LLM-based SimulMT through multi-turn-dialogue-based decoding. Our experiments with Llama2-7b-chat on two SimulMT benchmarks demonstrate the superiority of LLM in translation quality while achieving comparable computational latency to specialized SimulMT models.
6/24/2024
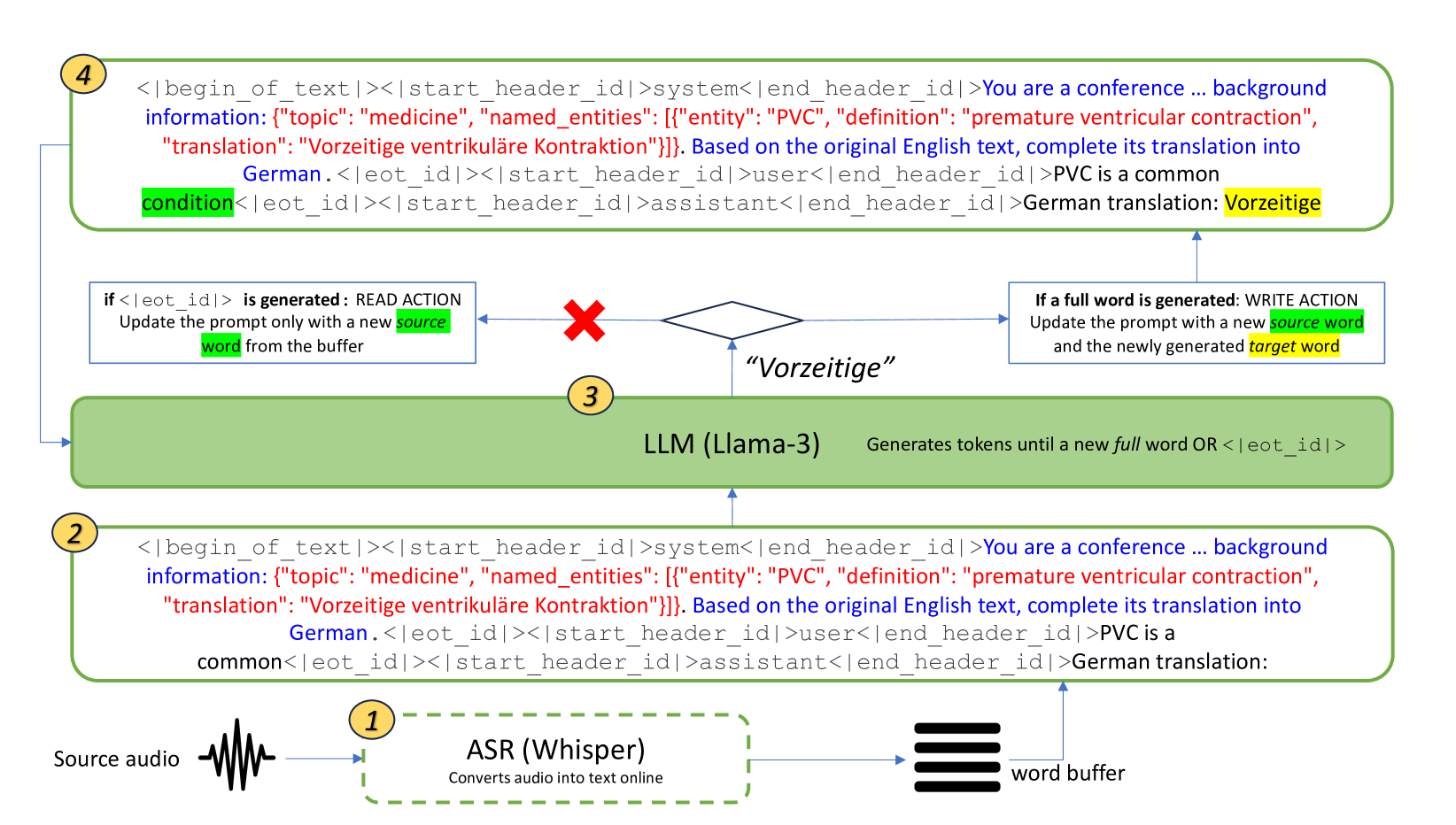
LLMs Are Zero-Shot Context-Aware Simultaneous Translators
Roman Koshkin, Katsuhito Sudoh, Satoshi Nakamura
0
0
The advent of transformers has fueled progress in machine translation. More recently large language models (LLMs) have come to the spotlight thanks to their generality and strong performance in a wide range of language tasks, including translation. Here we show that open-source LLMs perform on par with or better than some state-of-the-art baselines in simultaneous machine translation (SiMT) tasks, zero-shot. We also demonstrate that injection of minimal background information, which is easy with an LLM, brings further performance gains, especially on challenging technical subject-matter. This highlights LLMs' potential for building next generation of massively multilingual, context-aware and terminologically accurate SiMT systems that require no resource-intensive training or fine-tuning.
6/24/2024

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024

Simultaneous Masking, Not Prompting Optimization: A Paradigm Shift in Fine-tuning LLMs for Simultaneous Translation
Matthew Raffel, Victor Agostinelli, Lizhong Chen
0
0
Large language models (LLMs) have achieved state-of-the-art performance in various language processing tasks, motivating their adoption in simultaneous translation. Current fine-tuning methods to adapt LLMs for simultaneous translation focus on prompting optimization strategies using either data augmentation or prompt structure modifications. However, these methods suffer from several issues, such as unnecessarily expanded training sets, computational inefficiency from dumping the key and value cache, increased prompt sizes, or restriction to a single decision policy. To eliminate these issues, in this work, we propose SimulMask, a new paradigm for fine-tuning LLMs for simultaneous translation. It utilizes a novel attention mask approach that models simultaneous translation during fine-tuning by masking attention for a desired decision policy. Applying the proposed SimulMask on a Falcon LLM for the IWSLT 2017 dataset, we have observed a significant translation quality improvement compared to state-of-the-art prompting optimization strategies on five language pairs while reducing the computational cost.
6/28/2024