PRENet: A Plane-Fit Redundancy Encoding Point Cloud Sequence Network for Real-Time 3D Action Recognition

0
Sign in to get full access
Overview
- Introduces a new deep learning model called PRENet for real-time 3D action recognition from point cloud sequences
- Proposes a plane-fit redundancy encoding technique to effectively represent 3D point cloud data
- Demonstrates state-of-the-art performance on several benchmark 3D action recognition datasets
Plain English Explanation
PRENet is a deep learning model designed for recognizing human actions in real-time using 3D point cloud data. Point clouds are 3D representations of objects or scenes captured by sensors like LIDAR or depth cameras. Recognizing actions from point clouds is important for various applications like understanding human behavior in 3D.
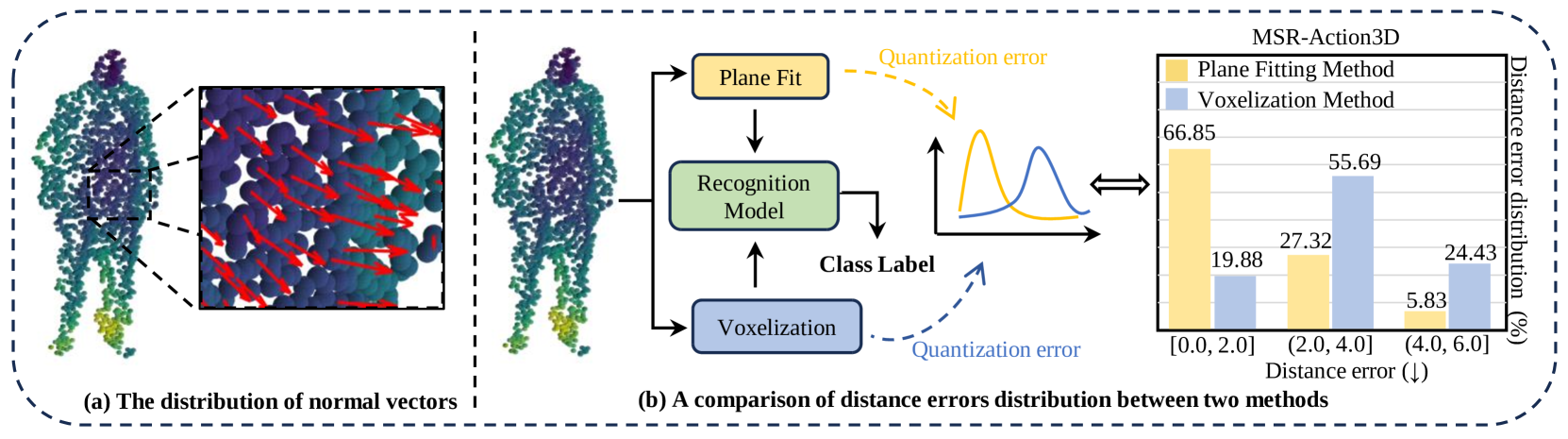
The key innovation of PRENet is its "plane-fit redundancy encoding" technique, which efficiently represents the 3D point cloud data. Instead of treating each point independently, PRENet groups nearby points into planar regions and encodes the relationships between these planes. This helps the model capture the underlying 3D structure of the scene more effectively than previous approaches.
By using this more compact and informative representation, PRENet is able to achieve state-of-the-art performance on popular 3D action recognition benchmarks, while also running in real-time. This makes it a promising technique for real-world applications that require fast and accurate 3D action understanding.
Technical Explanation
The key technical components of PRENet are:
-
Plane-Fit Redundancy Encoding: PRENet first fits planes to local point cloud regions using robust principal component analysis (RPCA). It then encodes the relationships between these planar regions, including their relative positions, orientations, and other geometric properties. This compact representation captures the 3D structure of the scene more effectively than using the raw point cloud data.
-
Temporal Encoding: To model the dynamics of human actions, PRENet uses a sequence-to-sequence architecture that takes in a temporal sequence of point cloud frames. It combines the plane-fit encoding of each frame with a recurrent neural network to learn the temporal evolution of the 3D structures.
-
Action Recognition Network: The final component of PRENet is the action recognition network, which takes the encoded point cloud sequences and classifies them into different action categories. PRENet uses a combination of convolutional and recurrent layers to extract both spatial and temporal features for accurate action recognition.
The researchers evaluate PRENet on several benchmark 3D action recognition datasets, including NTU RGB+D, Northwestern-UCLA, and UWA3DII. They show that PRENet outperforms previous state-of-the-art methods, while also running in real-time on commodity hardware.
Critical Analysis
The researchers acknowledge several limitations of their work. First, PRENet's performance may degrade if the input point clouds are sparse or noisy, as the plane-fitting process could be less reliable in such cases. Additionally, the model is primarily designed for frame-based action recognition, and may not be as effective for continuous or more complex activity understanding tasks.
Another potential concern is the reliance on RPCA for plane fitting, which could be computationally expensive for large-scale point clouds. The researchers suggest exploring more efficient plane segmentation techniques as future work to improve the scalability of PRENet.
Furthermore, the paper does not provide extensive analysis of PRENet's robustness to variations in sensor types, viewing angles, or environmental conditions. Evaluating the model's performance in more diverse and challenging real-world scenarios would be a valuable next step.
Conclusion
Overall, PRENet presents a promising approach for real-time 3D action recognition using point cloud data. Its novel plane-fit redundancy encoding technique effectively captures the 3D structure of the scene, allowing the model to achieve state-of-the-art performance on benchmark datasets. While the current work has some limitations, the researchers have outlined several promising directions for future improvements and applications.
The success of PRENet highlights the potential of deep learning methods for understanding human behavior in 3D and opens up new opportunities for real-world applications, such as smart surveillance, autonomous navigation, and human-robot interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PRENet: A Plane-Fit Redundancy Encoding Point Cloud Sequence Network for Real-Time 3D Action Recognition
Shenglin He, Xiaoyang Qu, Jiguang Wan, Guokuan Li, Changsheng Xie, Jianzong Wang
Recognizing human actions from point cloud sequence has attracted tremendous attention from both academia and industry due to its wide applications. However, most previous studies on point cloud action recognition typically require complex networks to extract intra-frame spatial features and inter-frame temporal features, resulting in an excessive number of redundant computations. This leads to high latency, rendering them impractical for real-world applications. To address this problem, we propose a Plane-Fit Redundancy Encoding point cloud sequence network named PRENet. The primary concept of our approach involves the utilization of plane fitting to mitigate spatial redundancy within the sequence, concurrently encoding the temporal redundancy of the entire sequence to minimize redundant computations. Specifically, our network comprises two principal modules: a Plane-Fit Embedding module and a Spatio-Temporal Consistency Encoding module. The Plane-Fit Embedding module capitalizes on the observation that successive point cloud frames exhibit unique geometric features in physical space, allowing for the reuse of spatially encoded data for temporal stream encoding. The Spatio-Temporal Consistency Encoding module amalgamates the temporal structure of the temporally redundant part with its corresponding spatial arrangement, thereby enhancing recognition accuracy. We have done numerous experiments to verify the effectiveness of our network. The experimental results demonstrate that our method achieves almost identical recognition accuracy while being nearly four times faster than other state-of-the-art methods.
Read more5/14/2024

0
KAN-HyperpointNet for Point Cloud Sequence-Based 3D Human Action Recognition
Zhaoyu Chen, Xing Li, Qian Huang, Qiang Geng, Tianjin Yang, Shihao Han
Point cloud sequence-based 3D action recognition has achieved impressive performance and efficiency. However, existing point cloud sequence modeling methods cannot adequately balance the precision of limb micro-movements with the integrity of posture macro-structure, leading to the loss of crucial information cues in action inference. To overcome this limitation, we introduce D-Hyperpoint, a novel data type generated through a D-Hyperpoint Embedding module. D-Hyperpoint encapsulates both regional-momentary motion and global-static posture, effectively summarizing the unit human action at each moment. In addition, we present a D-Hyperpoint KANsMixer module, which is recursively applied to nested groupings of D-Hyperpoints to learn the action discrimination information and creatively integrates Kolmogorov-Arnold Networks (KAN) to enhance spatio-temporal interaction within D-Hyperpoints. Finally, we propose KAN-HyperpointNet, a spatio-temporal decoupled network architecture for 3D action recognition. Extensive experiments on two public datasets: MSR Action3D and NTU-RGB+D 60, demonstrate the state-of-the-art performance of our method.
Read more9/17/2024
✅
0
Inter-Frame Compression for Dynamic Point Cloud Geometry Coding
Anique Akhtar, Zhu Li, Geert Van der Auwera
Efficient point cloud compression is essential for applications like virtual and mixed reality, autonomous driving, and cultural heritage. This paper proposes a deep learning-based inter-frame encoding scheme for dynamic point cloud geometry compression. We propose a lossy geometry compression scheme that predicts the latent representation of the current frame using the previous frame by employing a novel feature space inter-prediction network. The proposed network utilizes sparse convolutions with hierarchical multiscale 3D feature learning to encode the current frame using the previous frame. The proposed method introduces a novel predictor network for motion compensation in the feature domain to map the latent representation of the previous frame to the coordinates of the current frame to predict the current frame's feature embedding. The framework transmits the residual of the predicted features and the actual features by compressing them using a learned probabilistic factorized entropy model. At the receiver, the decoder hierarchically reconstructs the current frame by progressively rescaling the feature embedding. The proposed framework is compared to the state-of-the-art Video-based Point Cloud Compression (V-PCC) and Geometry-based Point Cloud Compression (G-PCC) schemes standardized by the Moving Picture Experts Group (MPEG). The proposed method achieves more than 88% BD-Rate (Bjontegaard Delta Rate) reduction against G-PCCv20 Octree, more than 56% BD-Rate savings against G-PCCv20 Trisoup, more than 62% BD-Rate reduction against V-PCC intra-frame encoding mode, and more than 52% BD-Rate savings against V-PCC P-frame-based inter-frame encoding mode using HEVC. These significant performance gains are cross-checked and verified in the MPEG working group.
Read more9/4/2024
✨
0
Multi-View Representation is What You Need for Point-Cloud Pre-Training
Siming Yan, Chen Song, Youkang Kong, Qixing Huang
A promising direction for pre-training 3D point clouds is to leverage the massive amount of data in 2D, whereas the domain gap between 2D and 3D creates a fundamental challenge. This paper proposes a novel approach to point-cloud pre-training that learns 3D representations by leveraging pre-trained 2D networks. Different from the popular practice of predicting 2D features first and then obtaining 3D features through dimensionality lifting, our approach directly uses a 3D network for feature extraction. We train the 3D feature extraction network with the help of the novel 2D knowledge transfer loss, which enforces the 2D projections of the 3D feature to be consistent with the output of pre-trained 2D networks. To prevent the feature from discarding 3D signals, we introduce the multi-view consistency loss that additionally encourages the projected 2D feature representations to capture pixel-wise correspondences across different views. Such correspondences induce 3D geometry and effectively retain 3D features in the projected 2D features. Experimental results demonstrate that our pre-trained model can be successfully transferred to various downstream tasks, including 3D shape classification, part segmentation, 3D object detection, and semantic segmentation, achieving state-of-the-art performance.
Read more4/30/2024