ESP-Zero: Unsupervised enhancement of zero-shot classification for Extremely Sparse Point cloud

0
🤷
Sign in to get full access
Overview
- Zero-shot learning, where machine learning models classify objects without prior training, has become a focus of research due to its flexibility and generality.
- Many approaches have been proposed to achieve zero-shot classification of 3D point clouds, following the success of the CLIP model.
- However, in the real world, point clouds can be extremely sparse, which limits the effectiveness of 3D point cloud encoders and causes misalignment between point cloud features and text embeddings.
- The paper proposes an unsupervised model adaptation approach to enhance point cloud encoders for extremely sparse point clouds, without the need to re-run the pre-training process.
Plain English Explanation
The paper looks at a machine learning technique called "zero-shot learning," which allows models to classify objects without being explicitly trained on them. This is an exciting area of research because it could make these models more flexible and useful in the real world.
Researchers have developed various approaches to apply zero-shot learning to 3D point clouds, which are digital representations of objects in three-dimensional space. The CLIP model has been particularly influential in this area.
However, the researchers note that in real-world situations, these 3D point clouds can be very sparse, meaning there are only a few data points representing the object. This makes it challenging for the 3D point cloud encoders (the parts of the model that process the point cloud data) to work effectively. As a result, the point cloud features don't align well with the text descriptions that the model uses to recognize the objects.
To address this problem, the researchers propose a new approach that can adapt the point cloud encoder to work better with extremely sparse point clouds, without having to go through the entire pre-training process again. This is important because re-training the model from scratch can be very time-consuming and expensive.
The key aspects of their approach are:
- A "fused-cross attention layer" that expands the pre-trained self-attention layer of the encoder, allowing it to better handle the sparse point cloud data while maintaining the alignment with the text descriptions.
- A "learning-based self-distillation" technique that encourages the modified features to be distinct from the irrelevant text embeddings, preventing the model from overfitting.
The researchers show through extensive experiments that their approach can significantly improve the zero-shot capabilities of the model when dealing with extremely sparse point clouds, outperforming other state-of-the-art adaptation methods.
Technical Explanation
The paper proposes an unsupervised model adaptation approach to enhance point cloud encoders for extremely sparse point clouds, without the need to re-run the pre-training process.
The key components of the approach are:
-
Fused-Cross Attention Layer: The researchers expand the pre-trained self-attention layer of the point cloud encoder with additional learnable tokens and attention blocks. This allows the encoder to effectively modify the point cloud features while maintaining the alignment between the point cloud features and text embeddings.
-
Learning-Based Self-Distillation: The researchers introduce a complementary learning-based self-distillation schema that encourages the modified features to be pulled apart from the irrelevant text embeddings. This prevents the model from overfitting the feature space to the observed text embeddings.
The researchers conduct extensive experiments to evaluate the proposed approach, demonstrating that it can significantly increase the zero-shot capability on extremely sparse point clouds, outperforming other state-of-the-art model adaptation approaches like Point-JEPA, Cross-Modal Self-Training, and Zero-Shot Point Cloud Completion.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenge of zero-shot learning on extremely sparse point clouds. The proposed unsupervised model adaptation technique, with the fused-cross attention layer and learning-based self-distillation, appears to be an effective way to enhance the point cloud encoder without the need for costly re-training.
However, the paper does not discuss the potential limitations or caveats of the approach. For example, it would be valuable to understand the computational and memory requirements of the fused-cross attention layer, as well as the sensitivity of the self-distillation process to hyperparameter settings.
Additionally, the paper could have explored the performance of the adapted model on a wider range of point cloud datasets, including those with varying degrees of sparsity, to better understand the generalizability of the approach.
Further research could also investigate the potential for transfer learning, where the adapted point cloud encoder could be fine-tuned on specific tasks or datasets, leveraging the improved handling of sparse point clouds.
Overall, the paper presents a compelling solution to an important problem in the field of 3D point cloud understanding, and the proposed techniques merit further exploration and refinement.
Conclusion
This paper introduces an unsupervised model adaptation approach to enhance 3D point cloud encoders for handling extremely sparse point clouds, a common challenge in real-world applications. The key innovations are the fused-cross attention layer, which expands the pre-trained encoder to better process sparse data, and the learning-based self-distillation technique, which prevents the model from overfitting to the text embeddings.
The extensive experiments demonstrate the effectiveness of the proposed approach in improving zero-shot classification performance on sparse point clouds, outperforming other state-of-the-art adaptation methods. This work represents an important step forward in making zero-shot learning on 3D point clouds more robust and practical, with potential applications in areas like autonomous navigation, robotics, and virtual/augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
ESP-Zero: Unsupervised enhancement of zero-shot classification for Extremely Sparse Point cloud
Jiayi Han, Zidi Cao, Weibo Zheng, Xiangguo Zhou, Xiangjian He, Yuanfang Zhang, Daisen Wei
In recent years, zero-shot learning has attracted the focus of many researchers, due to its flexibility and generality. Many approaches have been proposed to achieve the zero-shot classification of the point clouds for 3D object understanding, following the schema of CLIP. However, in the real world, the point clouds could be extremely sparse, dramatically limiting the effectiveness of the 3D point cloud encoders, and resulting in the misalignment of point cloud features and text embeddings. To the point cloud encoders to fit the extremely sparse point clouds without re-running the pre-training procedure which could be time-consuming and expensive, in this work, we propose an unsupervised model adaptation approach to enhance the point cloud encoder for the extremely sparse point clouds. We propose a novel fused-cross attention layer that expands the pre-trained self-attention layer with additional learnable tokens and attention blocks, which effectively modifies the point cloud features while maintaining the alignment between point cloud features and text embeddings. We also propose a complementary learning-based self-distillation schema that encourages the modified features to be pulled apart from the irrelevant text embeddings without overfitting the feature space to the observed text embeddings. Extensive experiments demonstrate that the proposed approach effectively increases the zero-shot capability on extremely sparse point clouds, and overwhelms other state-of-the-art model adaptation approaches.
Read more5/1/2024

0
Zero-Shot Object-Centric Representation Learning
Aniket Didolkar, Andrii Zadaianchuk, Anirudh Goyal, Mike Mozer, Yoshua Bengio, Georg Martius, Maximilian Seitzer
The goal of object-centric representation learning is to decompose visual scenes into a structured representation that isolates the entities. Recent successes have shown that object-centric representation learning can be scaled to real-world scenes by utilizing pre-trained self-supervised features. However, so far, object-centric methods have mostly been applied in-distribution, with models trained and evaluated on the same dataset. This is in contrast to the wider trend in machine learning towards general-purpose models directly applicable to unseen data and tasks. Thus, in this work, we study current object-centric methods through the lens of zero-shot generalization by introducing a benchmark comprising eight different synthetic and real-world datasets. We analyze the factors influencing zero-shot performance and find that training on diverse real-world images improves transferability to unseen scenarios. Furthermore, inspired by the success of task-specific fine-tuning in foundation models, we introduce a novel fine-tuning strategy to adapt pre-trained vision encoders for the task of object discovery. We find that the proposed approach results in state-of-the-art performance for unsupervised object discovery, exhibiting strong zero-shot transfer to unseen datasets.
Read more8/20/2024
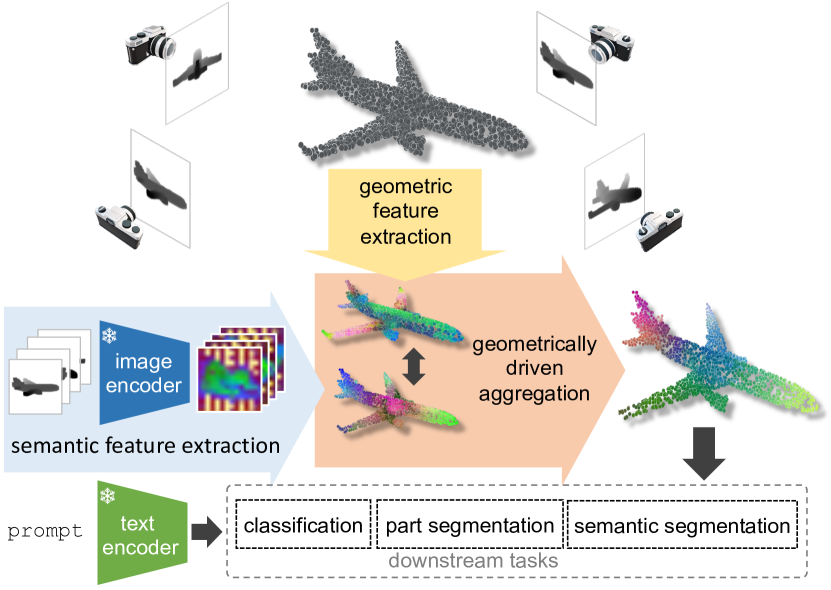
0
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
Read more4/16/2024

0
Towards Zero-shot Point Cloud Anomaly Detection: A Multi-View Projection Framework
Yuqi Cheng, Yunkang Cao, Guoyang Xie, Zhichao Lu, Weiming Shen
Detecting anomalies within point clouds is crucial for various industrial applications, but traditional unsupervised methods face challenges due to data acquisition costs, early-stage production constraints, and limited generalization across product categories. To overcome these challenges, we introduce the Multi-View Projection (MVP) framework, leveraging pre-trained Vision-Language Models (VLMs) to detect anomalies. Specifically, MVP projects point cloud data into multi-view depth images, thereby translating point cloud anomaly detection into image anomaly detection. Following zero-shot image anomaly detection methods, pre-trained VLMs are utilized to detect anomalies on these depth images. Given that pre-trained VLMs are not inherently tailored for zero-shot point cloud anomaly detection and may lack specificity, we propose the integration of learnable visual and adaptive text prompting techniques to fine-tune these VLMs, thereby enhancing their detection performance. Extensive experiments on the MVTec 3D-AD and Real3D-AD demonstrate our proposed MVP framework's superior zero-shot anomaly detection performance and the prompting techniques' effectiveness. Real-world evaluations on automotive plastic part inspection further showcase that the proposed method can also be generalized to practical unseen scenarios. The code is available at https://github.com/hustCYQ/MVP-PCLIP.
Read more9/23/2024