Pretrained-Guided Conditional Diffusion Models for Microbiome Data Analysis

0

Sign in to get full access
Overview
- The paper proposes a novel Pretrained-Guided Conditional Diffusion Model (PGCDM) for microbiome data analysis.
- The model leverages a pre-trained transformer to guide the diffusion process, enabling improved imputation of missing microbiome data.
- The approach also allows for the generation of synthetic microbiome samples that maintain key statistical properties of the original data.
Plain English Explanation
The human microbiome refers to the trillions of microorganisms that live in our bodies, particularly in the gut. Analyzing microbiome data is important for understanding how these microbial communities influence our health. However, microbiome datasets often have missing data, which can make it challenging to draw accurate insights.
The researchers in this paper have developed a new machine learning model to address this challenge. Their Pretrained-Guided Conditional Diffusion Model (PGCDM) uses a pre-trained transformer to help "fill in the blanks" in microbiome datasets. The transformer provides additional context to guide the diffusion process, leading to more accurate imputation of the missing data.
In addition, the PGCDM model can be used to generate new, synthetic microbiome samples that have similar statistical properties to the original data. This synthetic data could be useful for tasks like testing the robustness of microbiome analysis algorithms or simulating the effects of interventions on the microbiome.
Overall, this research represents an important step forward in the field of microbiome data analysis, providing a powerful tool to address the challenges of missing data and enable more reliable insights from this complex biological system.
Technical Explanation
The Pretrained-Guided Conditional Diffusion Model (PGCDM) is a novel approach that combines a diffusion model with a pre-trained transformer to enable improved imputation and generation of microbiome data.
The key components of the PGCDM architecture include:
-
Diffusion Model: The core of the model is a diffusion-based generative model, which learns to add controlled noise to the input data and then reverse the process to generate new samples.
-
Transformer Encoder: A pre-trained transformer encoder is used to provide additional contextual information to the diffusion model. This helps guide the diffusion process and lead to more accurate imputation of missing data.
-
Conditional Input: The model takes as input the partially observed microbiome data, along with any available metadata (e.g., patient characteristics). This conditional information is used to generate the completed microbiome profiles.
The researchers evaluate the PGCDM model on several microbiome datasets, comparing its performance to other state-of-the-art imputation and generation methods. The results demonstrate that the PGCDM approach outperforms these baselines, both in terms of imputation accuracy and the quality of the generated synthetic data.
Critical Analysis
The paper presents a well-designed study and a compelling approach to addressing the challenges of missing data in microbiome analysis. The use of a pre-trained transformer to guide the diffusion process is a novel and promising idea that leverages the strengths of both transformer and diffusion models.
One potential limitation is the reliance on the availability of a suitable pre-trained transformer model. The researchers used a transformer pre-trained on general text data, but it's unclear how well this would generalize to different microbiome datasets or domains. Future work could explore training the transformer component in a more domain-specific manner.
Additionally, the paper does not provide a detailed analysis of the computational complexity or training time of the PGCDM model. As microbiome datasets can be large and high-dimensional, the scalability of the approach may be an important consideration for real-world applications.
Overall, this research represents a significant contribution to the field of microbiome data analysis, and the PGCDM model shows promise as a powerful tool for addressing the challenges of missing data and enabling more reliable insights from this complex biological system.
Conclusion
The Pretrained-Guided Conditional Diffusion Model (PGCDM) proposed in this paper offers a novel approach to microbiome data analysis, leveraging the strengths of diffusion models and pre-trained transformers to enable improved imputation of missing data and generation of synthetic microbiome samples.
The results demonstrate the effectiveness of the PGCDM approach, which outperforms other state-of-the-art methods in terms of imputation accuracy and synthetic data quality. This research represents an important step forward in addressing the challenges of missing data in microbiome analysis, and the PGCDM model could have significant implications for advancing our understanding of the human microbiome and its relationship to health and disease.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pretrained-Guided Conditional Diffusion Models for Microbiome Data Analysis
Xinyuan Shi, Fangfang Zhu, Wenwen Min
Emerging evidence indicates that human cancers are intricately linked to human microbiomes, forming an inseparable connection. However, due to limited sample sizes and significant data loss during collection for various reasons, some machine learning methods have been proposed to address the issue of missing data. These methods have not fully utilized the known clinical information of patients to enhance the accuracy of data imputation. Therefore, we introduce mbVDiT, a novel pre-trained conditional diffusion model for microbiome data imputation and denoising, which uses the unmasked data and patient metadata as conditional guidance for imputating missing values. It is also uses VAE to integrate the the other public microbiome datasets to enhance model performance. The results on the microbiome datasets from three different cancer types demonstrate the performance of our methods in comparison with existing methods.
Read more8/16/2024

0
Diffusion Models for Tabular Data Imputation and Synthetic Data Generation
Mario Villaiz'an-Vallelado, Matteo Salvatori, Carlos Segura, Ioannis Arapakis
Data imputation and data generation have important applications for many domains, like healthcare and finance, where incomplete or missing data can hinder accurate analysis and decision-making. Diffusion models have emerged as powerful generative models capable of capturing complex data distributions across various data modalities such as image, audio, and time series data. Recently, they have been also adapted to generate tabular data. In this paper, we propose a diffusion model for tabular data that introduces three key enhancements: (1) a conditioning attention mechanism, (2) an encoder-decoder transformer as the denoising network, and (3) dynamic masking. The conditioning attention mechanism is designed to improve the model's ability to capture the relationship between the condition and synthetic data. The transformer layers help model interactions within the condition (encoder) or synthetic data (decoder), while dynamic masking enables our model to efficiently handle both missing data imputation and synthetic data generation tasks within a unified framework. We conduct a comprehensive evaluation by comparing the performance of diffusion models with transformer conditioning against state-of-the-art techniques, such as Variational Autoencoders, Generative Adversarial Networks and Diffusion Models, on benchmark datasets. Our evaluation focuses on the assessment of the generated samples with respect to three important criteria, namely: (1) Machine Learning efficiency, (2) statistical similarity, and (3) privacy risk mitigation. For the task of data imputation, we consider the efficiency of the generated samples across different levels of missing features.
Read more7/4/2024

0
Cross-conditioned Diffusion Model for Medical Image to Image Translation
Zhaohu Xing, Sicheng Yang, Sixiang Chen, Tian Ye, Yijun Yang, Jing Qin, Lei Zhu
Multi-modal magnetic resonance imaging (MRI) provides rich, complementary information for analyzing diseases. However, the practical challenges of acquiring multiple MRI modalities, such as cost, scan time, and safety considerations, often result in incomplete datasets. This affects both the quality of diagnosis and the performance of deep learning models trained on such data. Recent advancements in generative adversarial networks (GANs) and denoising diffusion models have shown promise in natural and medical image-to-image translation tasks. However, the complexity of training GANs and the computational expense associated with diffusion models hinder their development and application in this task. To address these issues, we introduce a Cross-conditioned Diffusion Model (CDM) for medical image-to-image translation. The core idea of CDM is to use the distribution of target modalities as guidance to improve synthesis quality while achieving higher generation efficiency compared to conventional diffusion models. First, we propose a Modality-specific Representation Model (MRM) to model the distribution of target modalities. Then, we design a Modality-decoupled Diffusion Network (MDN) to efficiently and effectively learn the distribution from MRM. Finally, a Cross-conditioned UNet (C-UNet) with a Condition Embedding module is designed to synthesize the target modalities with the source modalities as input and the target distribution for guidance. Extensive experiments conducted on the BraTS2023 and UPenn-GBM benchmark datasets demonstrate the superiority of our method.
Read more9/16/2024
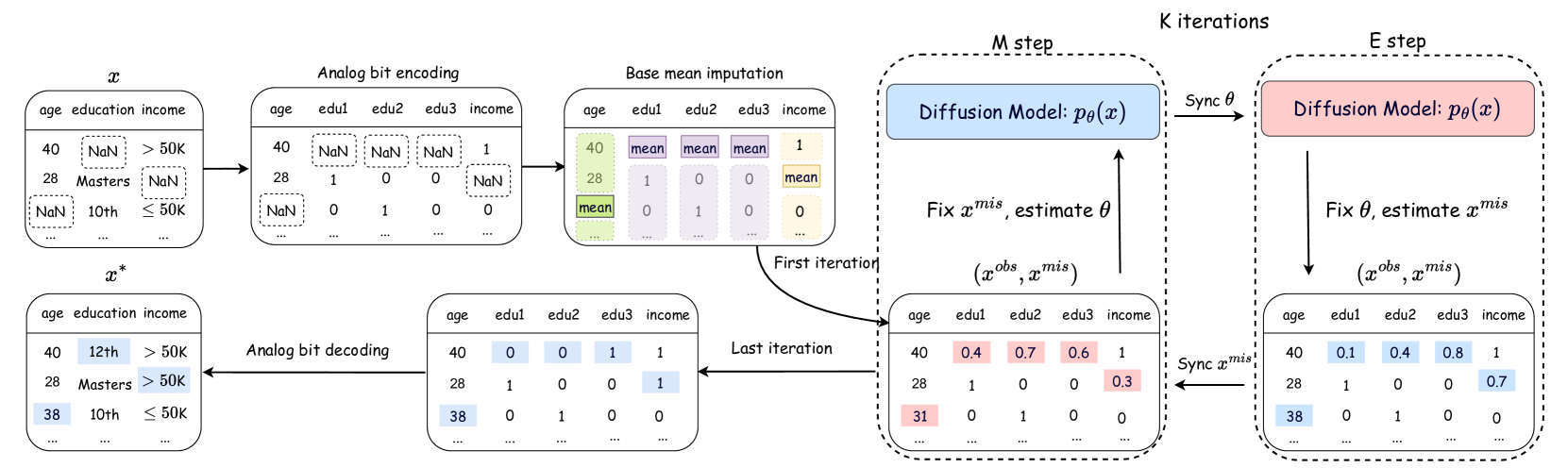
0
Unleashing the Potential of Diffusion Models for Incomplete Data Imputation
Hengrui Zhang, Liancheng Fang, Philip S. Yu
This paper introduces DiffPuter, an iterative method for missing data imputation that leverages the Expectation-Maximization (EM) algorithm and Diffusion Models. By treating missing data as hidden variables that can be updated during model training, we frame the missing data imputation task as an EM problem. During the M-step, DiffPuter employs a diffusion model to learn the joint distribution of both the observed and currently estimated missing data. In the E-step, DiffPuter re-estimates the missing data based on the conditional probability given the observed data, utilizing the diffusion model learned in the M-step. Starting with an initial imputation, DiffPuter alternates between the M-step and E-step until convergence. Through this iterative process, DiffPuter progressively refines the complete data distribution, yielding increasingly accurate estimations of the missing data. Our theoretical analysis demonstrates that the unconditional training and conditional sampling processes of the diffusion model align precisely with the objectives of the M-step and E-step, respectively. Empirical evaluations across 10 diverse datasets and comparisons with 16 different imputation methods highlight DiffPuter's superior performance. Notably, DiffPuter achieves an average improvement of 8.10% in MAE and 5.64% in RMSE compared to the most competitive existing method.
Read more6/3/2024