Pretraining a Neural Operator in Lower Dimensions

0
Sign in to get full access
Overview
- This paper explores pretraining a neural operator in lower dimensions to improve its performance on partial differential equation (PDE) problems.
- The key idea is to first train the neural operator on a simpler, lower-dimensional PDE problem, and then use that as a starting point for training on the full, higher-dimensional PDE.
- This pretraining approach is shown to outperform training the neural operator directly on the high-dimensional PDE.
Plain English Explanation
Partial differential equations (PDEs) are mathematical models that describe various physical phenomena, like the flow of fluids or the propagation of waves. These PDEs can be very complex, especially when they involve many different variables or dimensions.
Neural operators are a type of machine learning model that can be used to approximate the solutions to these high-dimensional PDEs. However, training neural operators on these complex PDEs can be challenging and computationally intensive.
The key insight of this research is that it may be beneficial to first train the neural operator on a simpler, lower-dimensional version of the PDE. This "pretraining" step allows the model to learn some of the underlying patterns and structures of the PDE before being asked to tackle the full, high-dimensional problem.
The researchers demonstrate that this pretraining approach leads to better performance compared to training the neural operator directly on the high-dimensional PDE. The pretraining gives the model a head start, allowing it to converge to a better solution more quickly and efficiently.
This idea of leveraging pretraining on simpler tasks to improve performance on more complex ones is a common technique in machine learning. By breaking down a difficult problem into more manageable steps, the model can build up the necessary knowledge and capabilities in a structured way.
Technical Explanation
The researchers propose a pretraining strategy for neural operators to improve their performance on high-dimensional PDE problems. The key steps are:
-
Pretraining on a lower-dimensional PDE: The neural operator is first trained on a simplified, lower-dimensional version of the target PDE problem. This allows the model to learn the fundamental structures and patterns of the PDE without the added complexity of the full high-dimensional problem.
-
Fine-tuning on the high-dimensional PDE: After pretraining, the neural operator is fine-tuned on the original, high-dimensional PDE problem. The pretraining provides a good starting point, allowing the model to converge to a better solution more efficiently compared to training from scratch.
The researchers evaluate this pretraining approach on several benchmark PDE problems, including the Darcy flow and the Allen-Cahn equation. They show that the pretrained neural operator outperforms models trained directly on the high-dimensional PDEs, both in terms of accuracy and computational efficiency.
The key technical insight is that the lower-dimensional pretraining helps the neural operator build a more robust and generalizable representation of the underlying PDE structure. This representation can then be leveraged when tackling the full high-dimensional problem, leading to better performance.
Critical Analysis
The pretraining approach proposed in this paper is a promising strategy for improving the performance of neural operators on high-dimensional PDE problems. The researchers provide a clear and well-designed set of experiments to demonstrate the benefits of their approach.
One potential limitation is that the success of the pretraining may depend on the specific characteristics of the PDE problem and the choice of the lower-dimensional pretraining task. The researchers acknowledge this and suggest that further research is needed to understand the optimal pretraining strategies for different types of PDEs.
Additionally, the paper does not explore the limitations of this pretraining approach or discuss potential pitfalls. For example, it is unclear how the method would scale to extremely high-dimensional PDE problems or how sensitive the performance is to the choice of the lower-dimensional pretraining task.
Despite these caveats, the research presented in this paper is a valuable contribution to the field of neural operators and PDE modeling. The pretraining strategy offers a promising direction for improving the data efficiency and generalization of these powerful machine learning models.
Conclusion
This paper introduces a novel pretraining approach for neural operators to improve their performance on high-dimensional PDE problems. By first training the model on a simpler, lower-dimensional version of the target PDE, the researchers demonstrate that the neural operator can learn a more robust and generalizable representation of the underlying PDE structure.
The proposed pretraining strategy has the potential to significantly improve the efficiency and effectiveness of neural operators in a wide range of PDE-related applications, from fluid dynamics to materials science. As the field of neural operators continues to evolve, this work represents an important step towards making these models more practical and impactful in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pretraining a Neural Operator in Lower Dimensions
AmirPouya Hemmasian, Amir Barati Farimani
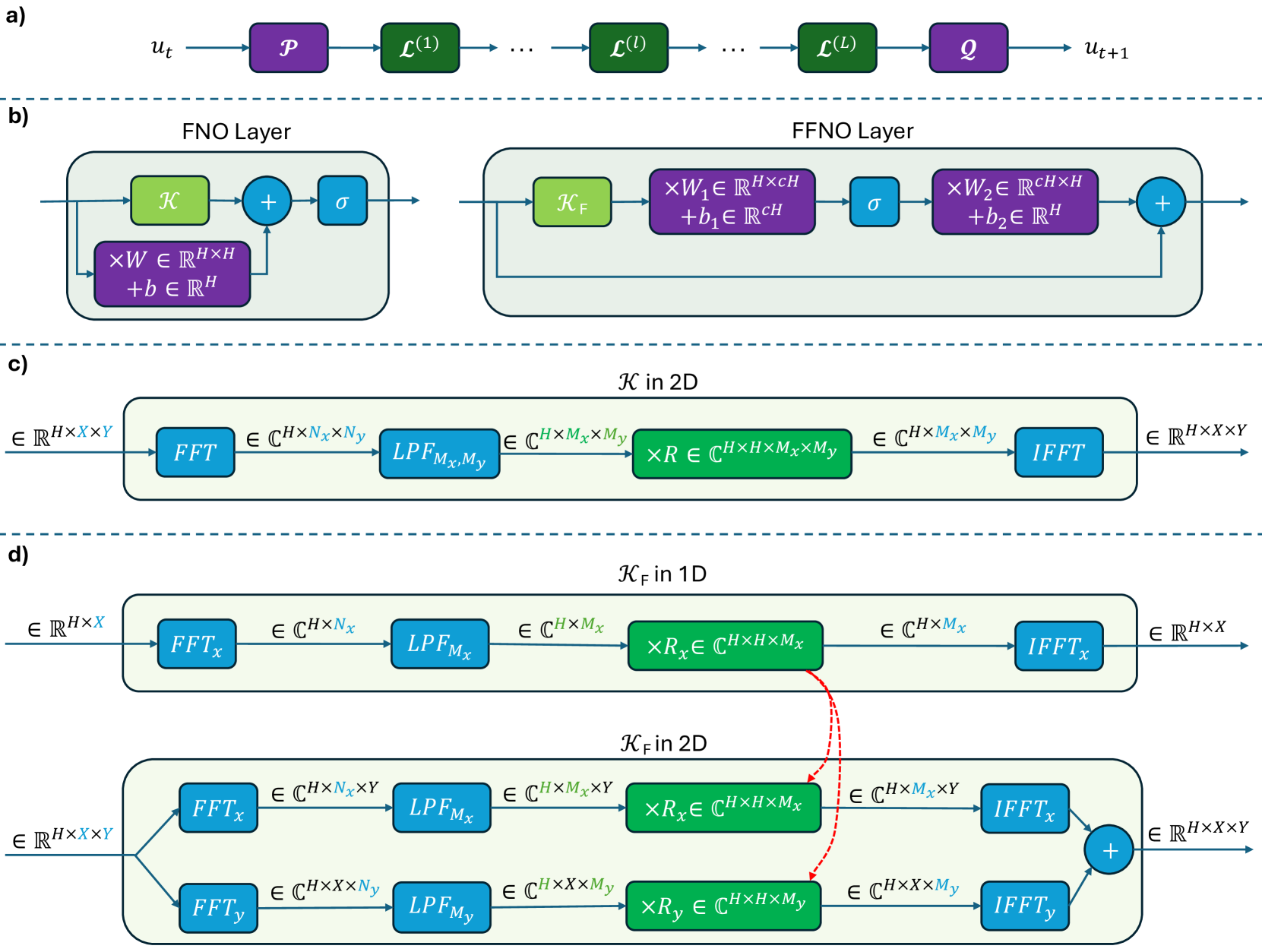
There has recently been increasing attention towards developing foundational neural Partial Differential Equation (PDE) solvers and neural operators through large-scale pretraining. However, unlike vision and language models that make use of abundant and inexpensive (unlabeled) data for pretraining, these neural solvers usually rely on simulated PDE data, which can be costly to obtain, especially for high-dimensional PDEs. In this work, we aim to Pretrain neural PDE solvers on Lower Dimensional PDEs (PreLowD) where data collection is the least expensive. We evaluated the effectiveness of this pretraining strategy in similar PDEs in higher dimensions. We use the Factorized Fourier Neural Operator (FFNO) due to having the necessary flexibility to be applied to PDE data of arbitrary spatial dimensions and reuse trained parameters in lower dimensions. In addition, our work sheds light on the effect of the fine-tuning configuration to make the most of this pretraining strategy.
Read more7/26/2024

0
Self-supervised Pretraining for Partial Differential Equations
Varun Madhavan, Amal S Sebastian, Bharath Ramsundar, Venkatasubramanian Viswanathan
In this work, we describe a novel approach to building a neural PDE solver leveraging recent advances in transformer based neural network architectures. Our model can provide solutions for different values of PDE parameters without any need for retraining the network. The training is carried out in a self-supervised manner, similar to pretraining approaches applied in language and vision tasks. We hypothesize that the model is in effect learning a family of operators (for multiple parameters) mapping the initial condition to the solution of the PDE at any future time step t. We compare this approach with the Fourier Neural Operator (FNO), and demonstrate that it can generalize over the space of PDE parameters, despite having a higher prediction error for individual parameter values compared to the FNO. We show that performance on a specific parameter can be improved by finetuning the model with very small amounts of data. We also demonstrate that the model scales with data as well as model size.
Read more7/10/2024

0
Strategies for Pretraining Neural Operators
Anthony Zhou, Cooper Lorsung, AmirPouya Hemmasian, Amir Barati Farimani
Pretraining for partial differential equation (PDE) modeling has recently shown promise in scaling neural operators across datasets to improve generalizability and performance. Despite these advances, our understanding of how pretraining affects neural operators is still limited; studies generally propose tailored architectures and datasets that make it challenging to compare or examine different pretraining frameworks. To address this, we compare various pretraining methods without optimizing architecture choices to characterize pretraining dynamics on different models and datasets as well as to understand its scaling and generalization behavior. We find that pretraining is highly dependent on model and dataset choices, but in general transfer learning or physics-based pretraining strategies work best. In addition, pretraining performance can be further improved by using data augmentations. Lastly, pretraining is additionally beneficial when fine-tuning in scarce data regimes or when generalizing to downstream data similar to the pretraining distribution. Through providing insights into pretraining neural operators for physics prediction, we hope to motivate future work in developing and evaluating pretraining methods for PDEs.
Read more6/13/2024
0
Data-Efficient Operator Learning via Unsupervised Pretraining and In-Context Learning
Wuyang Chen, Jialin Song, Pu Ren, Shashank Subramanian, Dmitriy Morozov, Michael W. Mahoney
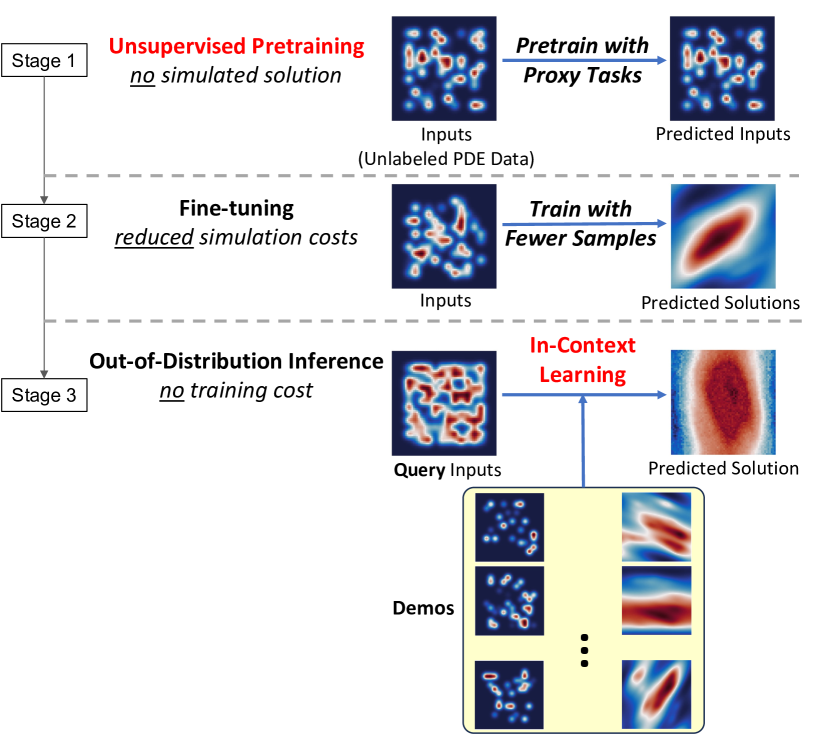
Recent years have witnessed the promise of coupling machine learning methods and physical domainspecific insights for solving scientific problems based on partial differential equations (PDEs). However, being data-intensive, these methods still require a large amount of PDE data. This reintroduces the need for expensive numerical PDE solutions, partially undermining the original goal of avoiding these expensive simulations. In this work, seeking data efficiency, we design unsupervised pretraining for PDE operator learning. To reduce the need for training data with heavy simulation costs, we mine unlabeled PDE data without simulated solutions, and pretrain neural operators with physics-inspired reconstruction-based proxy tasks. To improve out-of-distribution performance, we further assist neural operators in flexibly leveraging in-context learning methods, without incurring extra training costs or designs. Extensive empirical evaluations on a diverse set of PDEs demonstrate that our method is highly data-efficient, more generalizable, and even outperforms conventional vision-pretrained models.
Read more6/14/2024