Scalable Amortized GPLVMs for Single Cell Transcriptomics Data

0

Sign in to get full access
Overview
- Presents a scalable and efficient approach for Gaussian Process Latent Variable Models (GPLVMs) to analyze single-cell transcriptomics data
- Introduces an amortized inference scheme that enables fast prediction of latent representations for new data points
- Demonstrates the method's ability to capture complex, nonlinear structure in high-dimensional single-cell datasets
Plain English Explanation
Analyzing single-cell genomic data can provide valuable insights into the diversity and function of individual cells. However, the high-dimensional nature of this data makes it challenging to understand the underlying patterns and structure. Scalable Amortized GPLVMs for Single Cell Transcriptomics Data proposes a new method to address this problem.
The key idea is to use Gaussian Process Latent Variable Models (GPLVMs), a type of machine learning algorithm, to uncover the low-dimensional representations that capture the essential features of the single-cell data. This allows researchers to visualize and interpret the data more effectively. The authors introduce an "amortized" approach, which means the model can quickly make predictions for new data points, making the method scalable and efficient.
By applying this technique to several real-world single-cell datasets, the researchers demonstrate its ability to reveal complex, nonlinear structures that could not be easily detected using other methods. This could lead to a better understanding of cellular diversity and enable more accurate predictions about cell states and functions.
Technical Explanation
Scalable Amortized GPLVMs for Single Cell Transcriptomics Data presents a novel approach for analyzing single-cell transcriptomics data using Gaussian Process Latent Variable Models (GPLVMs). GPLVMs are a powerful tool for discovering low-dimensional representations of high-dimensional data, which can be particularly useful for visualizing and interpreting single-cell genomic datasets.
The main contribution of this work is the introduction of an "amortized" inference scheme for GPLVMs, which enables fast prediction of latent representations for new data points. This is achieved by training a neural network to approximate the posterior distribution of the latent variables, rather than relying on expensive iterative inference methods.
The authors demonstrate the effectiveness of their approach on several single-cell datasets, showing that the amortized GPLVM can capture complex, nonlinear structure that is not easily detected by other dimensionality reduction techniques, such as principal component analysis or t-SNE. Additionally, they show that the amortized inference scheme provides significant computational advantages, allowing the model to scale to large datasets without sacrificing performance.
Critical Analysis
One potential limitation of the amortized GPLVM approach is the reliance on a neural network to approximate the posterior distribution of the latent variables. While this enables fast inference, it introduces additional complexity and potential sources of error. The authors acknowledge this and suggest that further research is needed to understand the robustness and reliability of the amortized inference scheme, especially in the context of noisy or sparse single-cell data.
Additionally, the paper does not provide a thorough comparison of the amortized GPLVM to other state-of-the-art dimensionality reduction techniques for single-cell data, such as Manifold Gaussian Variational Bayes or kernel-based testing for single-cell differential analysis. A more comprehensive benchmarking against these methods would help to better situate the contributions of the amortized GPLVM approach.
Despite these potential limitations, the Scalable Amortized GPLVMs for Single Cell Transcriptomics Data paper presents a promising and innovative approach for analyzing complex single-cell genomic data. The ability to capture nonlinear structure and the computational efficiency of the amortized inference scheme are significant advantages that could make the method a valuable tool for researchers in the field of single-cell biology.
Conclusion
Scalable Amortized GPLVMs for Single Cell Transcriptomics Data introduces a novel approach for analyzing single-cell transcriptomics data using Gaussian Process Latent Variable Models (GPLVMs) with an amortized inference scheme. This allows the model to efficiently capture complex, nonlinear structure in high-dimensional single-cell datasets, providing a powerful tool for visualizing and interpreting cellular diversity.
The key contributions of this work are the development of the amortized GPLVM and its successful application to several real-world single-cell datasets. While the method has some potential limitations, it represents an important step forward in the field of single-cell data analysis and could lead to new insights into cellular function and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scalable Amortized GPLVMs for Single Cell Transcriptomics Data
Sarah Zhao, Aditya Ravuri, Vidhi Lalchand, Neil D. Lawrence
Dimensionality reduction is crucial for analyzing large-scale single-cell RNA-seq data. Gaussian Process Latent Variable Models (GPLVMs) offer an interpretable dimensionality reduction method, but current scalable models lack effectiveness in clustering cell types. We introduce an improved model, the amortized stochastic variational Bayesian GPLVM (BGPLVM), tailored for single-cell RNA-seq with specialized encoder, kernel, and likelihood designs. This model matches the performance of the leading single-cell variational inference (scVI) approach on synthetic and real-world COVID datasets and effectively incorporates cell-cycle and batch information to reveal more interpretable latent structures as we demonstrate on an innate immunity dataset.
Read more5/8/2024
0
Preventing Model Collapse in Gaussian Process Latent Variable Models
Ying Li, Zhidi Lin, Feng Yin, Michael Minyi Zhang
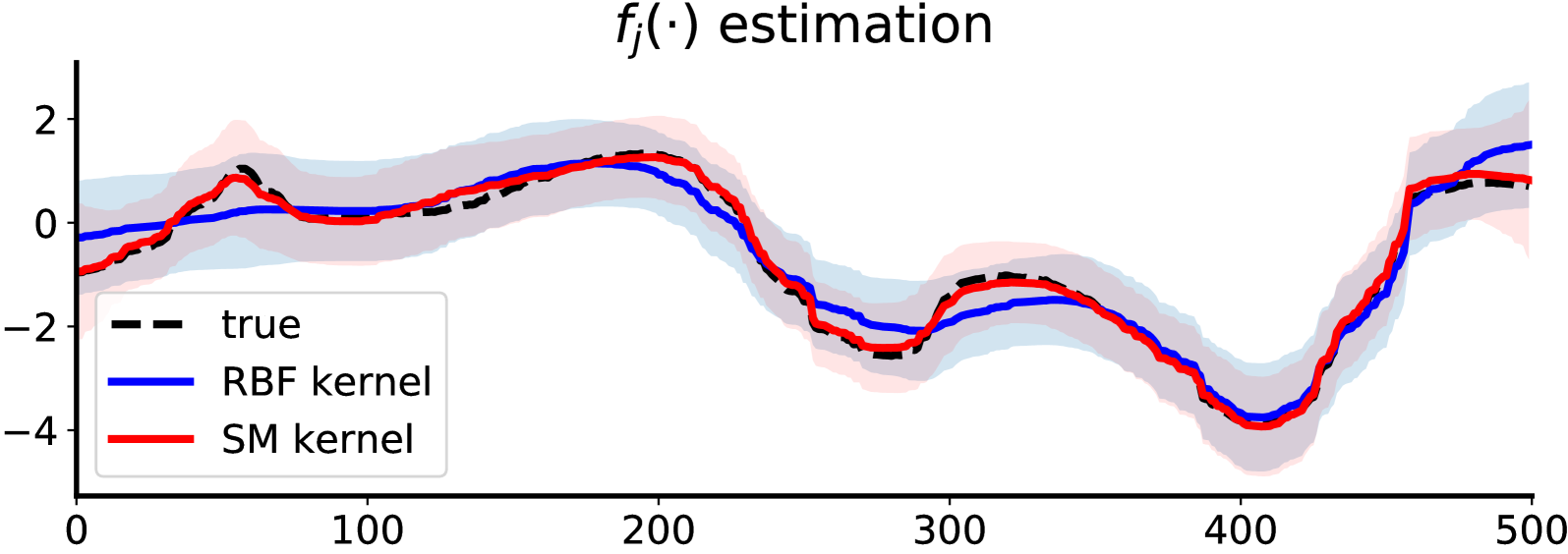
Gaussian process latent variable models (GPLVMs) are a versatile family of unsupervised learning models commonly used for dimensionality reduction. However, common challenges in modeling data with GPLVMs include inadequate kernel flexibility and improper selection of the projection noise, leading to a type of model collapse characterized by vague latent representations that do not reflect the underlying data structure. This paper addresses these issues by, first, theoretically examining the impact of projection variance on model collapse through the lens of a linear GPLVM. Second, we tackle model collapse due to inadequate kernel flexibility by integrating the spectral mixture (SM) kernel and a differentiable random Fourier feature (RFF) kernel approximation, which ensures computational scalability and efficiency through off-the-shelf automatic differentiation tools for learning the kernel hyperparameters, projection variance, and latent representations within the variational inference framework. The proposed GPLVM, named advisedRFLVM, is evaluated across diverse datasets and consistently outperforms various salient competing models, including state-of-the-art variational autoencoders (VAEs) and other GPLVM variants, in terms of informative latent representations and missing data imputation.
Read more6/19/2024

0
Amortized Variational Inference for Deep Gaussian Processes
Qiuxian Meng, Yongyou Zhang
Gaussian processes (GPs) are Bayesian nonparametric models for function approximation with principled predictive uncertainty estimates. Deep Gaussian processes (DGPs) are multilayer generalizations of GPs that can represent complex marginal densities as well as complex mappings. As exact inference is either computationally prohibitive or analytically intractable in GPs and extensions thereof, some existing methods resort to variational inference (VI) techniques for tractable approximations. However, the expressivity of conventional approximate GP models critically relies on independent inducing variables that might not be informative enough for some problems. In this work we introduce amortized variational inference for DGPs, which learns an inference function that maps each observation to variational parameters. The resulting method enjoys a more expressive prior conditioned on fewer input dependent inducing variables and a flexible amortized marginal posterior that is able to model more complicated functions. We show with theoretical reasoning and experimental results that our method performs similarly or better than previous approaches at less computational cost.
Read more9/20/2024

0
Latent mixed-effect models for high-dimensional longitudinal data
Priscilla Ong, Manuel Hau{ss}mann, Otto Lonnroth, Harri Lahdesmaki
Modelling longitudinal data is an important yet challenging task. These datasets can be high-dimensional, contain non-linear effects and time-varying covariates. Gaussian process (GP) prior-based variational autoencoders (VAEs) have emerged as a promising approach due to their ability to model time-series data. However, they are costly to train and struggle to fully exploit the rich covariates characteristic of longitudinal data, making them difficult for practitioners to use effectively. In this work, we leverage linear mixed models (LMMs) and amortized variational inference to provide conditional priors for VAEs, and propose LMM-VAE, a scalable, interpretable and identifiable model. We highlight theoretical connections between it and GP-based techniques, providing a unified framework for this class of methods. Our proposal performs competitively compared to existing approaches across simulated and real-world datasets.
Read more9/18/2024