PRISM: Patient Records Interpretation for Semantic Clinical Trial Matching using Large Language Models

0
💬
Sign in to get full access
Overview
- The paper explores the use of Large Language Models (LLMs) to automate the process of matching patients to appropriate clinical trials.
- Typically, this task is labor-intensive and requires manual review of patient electronic health records (EHRs) against the eligibility criteria of clinical trials.
- The authors present the first large-scale empirical evaluation of clinical trial matching using real-world EHRs, showcasing the capability of LLMs to accurately match patients with appropriate trials.
- The study compares the performance of proprietary LLMs, including GPT-4 and GPT-3.5, as well as a custom fine-tuned model called OncoLLM.
Plain English Explanation
Matching patients to the right clinical trials is an important but challenging task. Traditionally, this has involved manually reviewing each patient's medical records to see if they meet the specific requirements for a particular clinical trial. This process is time-consuming and difficult to scale up, meaning many patients may miss out on potential treatment options.
Recent advancements in Large Language Models (LLMs) have shown that it's possible to automate this patient-trial matching process. LLMs are powerful AI systems that can understand and generate human-like text. By using LLMs, the researchers in this study were able to accurately match patients to appropriate clinical trials, without having to manually review each patient's records.
The researchers tested different LLM models, including GPT-4 and GPT-3.5, as well as a custom model they developed called OncoLLM. Surprisingly, the smaller OncoLLM model was able to match the performance of qualified medical doctors, even outperforming the larger GPT-3.5 model. This suggests that with the right training, even relatively small LLM models can be highly effective at automating clinical trial matching.
The study's use of real-world medical data, rather than synthetic data, is a particular strength, as it demonstrates the potential of LLMs to handle the complexities and nuances of actual patient records in a clinical setting.
Technical Explanation
The paper presents a large-scale empirical evaluation of using Large Language Models (LLMs) to automate the process of matching patients to appropriate clinical trials. This task is typically labor-intensive and requires manual review of patient electronic health records (EHRs) against the stringent inclusion and exclusion criteria of clinical trials.
The authors conducted experiments using proprietary LLMs, including GPT-4 and GPT-3.5, as well as a custom fine-tuned model called OncoLLM. Unlike previous studies that used constrained, often synthetic datasets, this research leveraged real-world EHRs that included clinical notes and available clinical trials from a single cancer center in the United States.
The results show that LLMs, including the smaller OncoLLM model, are capable of accurately matching patients to appropriate clinical trials, with OncoLLM outperforming the larger GPT-3.5 model and matching the performance of qualified medical doctors. This suggests that with the right training, even relatively small LLM models can be highly effective at automating patient-trial matching.
The use of real-world EHR data is a key strength of this study, as it demonstrates the ability of LLMs to handle the complexities and nuances of actual patient records in a clinical setting, rather than relying on simplified, synthetic datasets. This represents an important step towards the practical application of LLMs in biomedicine.
Critical Analysis
The study presents a promising approach to automating the patient-trial matching process, which could significantly improve patient access to potentially beneficial clinical trials. However, the authors acknowledge several limitations and areas for further research.
One limitation is the use of data from a single cancer center, which may limit the generalizability of the findings. Validating the models' performance across multiple healthcare systems and disease areas would be an important next step.
Additionally, the study does not address the ethical considerations of using LLMs in this sensitive medical context, such as potential biases in the training data or the need for robust safeguards to ensure patient privacy and informed consent.
Further research could also explore the integration of LLM-based patient-trial matching into clinical workflows, as well as the long-term impact on trial recruitment and patient outcomes.
Conclusion
This study demonstrates the remarkable potential of Large Language Models to automate the challenging task of matching patients to appropriate clinical trials. By leveraging real-world electronic health records, the researchers have shown that LLMs, including a custom fine-tuned model called OncoLLM, can accurately identify eligible patients, potentially improving access to experimental therapies.
The findings suggest that with the right training, even relatively small LLM models can perform at a level that matches qualified medical professionals. This represents an important step towards the practical application of LLMs in biomedicine and could have significant implications for the efficiency and scalability of clinical trial recruitment.
While further research is needed to address the limitations and ethical considerations, this study provides a compelling proof-of-concept for the use of advanced language models in the complex and critical domain of clinical trial matching.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
PRISM: Patient Records Interpretation for Semantic Clinical Trial Matching using Large Language Models
Shashi Kant Gupta, Aditya Basu, Mauro Nievas, Jerrin Thomas, Nathan Wolfrath, Adhitya Ramamurthi, Bradley Taylor, Anai N. Kothari, Regina Schwind, Therica M. Miller, Sorena Nadaf-Rahrov, Yanshan Wang, Hrituraj Singh
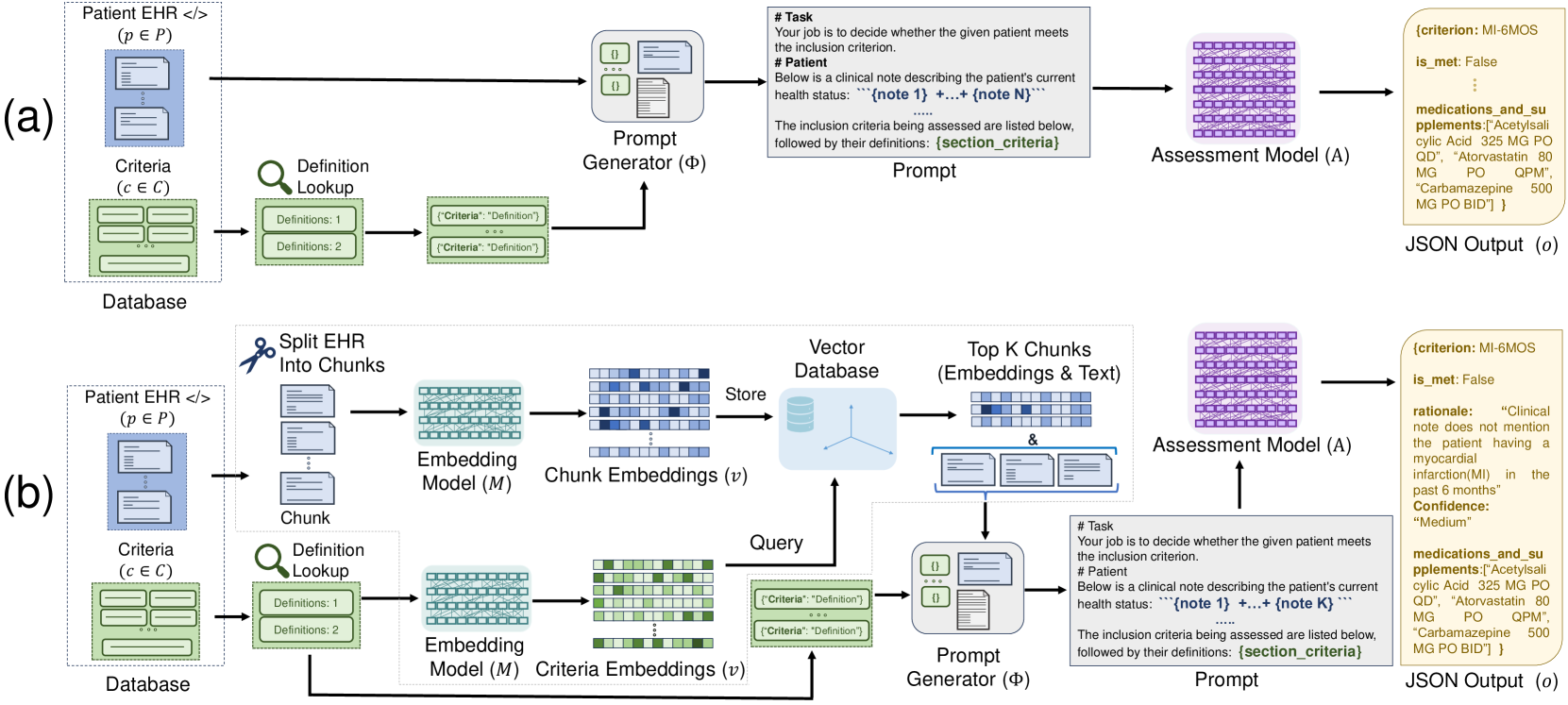
Clinical trial matching is the task of identifying trials for which patients may be potentially eligible. Typically, this task is labor-intensive and requires detailed verification of patient electronic health records (EHRs) against the stringent inclusion and exclusion criteria of clinical trials. This process is manual, time-intensive, and challenging to scale up, resulting in many patients missing out on potential therapeutic options. Recent advancements in Large Language Models (LLMs) have made automating patient-trial matching possible, as shown in multiple concurrent research studies. However, the current approaches are confined to constrained, often synthetic datasets that do not adequately mirror the complexities encountered in real-world medical data. In this study, we present the first, end-to-end large-scale empirical evaluation of clinical trial matching using real-world EHRs. Our study showcases the capability of LLMs to accurately match patients with appropriate clinical trials. We perform experiments with proprietary LLMs, including GPT-4 and GPT-3.5, as well as our custom fine-tuned model called OncoLLM and show that OncoLLM, despite its significantly smaller size, not only outperforms GPT-3.5 but also matches the performance of qualified medical doctors. All experiments were carried out on real-world EHRs that include clinical notes and available clinical trials from a single cancer center in the United States.
Read more4/30/2024

0
End-To-End Clinical Trial Matching with Large Language Models
Dyke Ferber, Lars Hilgers, Isabella C. Wiest, Marie-Elisabeth Le{ss}mann, Jan Clusmann, Peter Neidlinger, Jiefu Zhu, Georg Wolflein, Jacqueline Lammert, Maximilian Tschochohei, Heiko Bohme, Dirk Jager, Mihaela Aldea, Daniel Truhn, Christiane Hoper, Jakob Nikolas Kather
Matching cancer patients to clinical trials is essential for advancing treatment and patient care. However, the inconsistent format of medical free text documents and complex trial eligibility criteria make this process extremely challenging and time-consuming for physicians. We investigated whether the entire trial matching process - from identifying relevant trials among 105,600 oncology-related clinical trials on clinicaltrials.gov to generating criterion-level eligibility matches - could be automated using Large Language Models (LLMs). Using GPT-4o and a set of 51 synthetic Electronic Health Records (EHRs), we demonstrate that our approach identifies relevant candidate trials in 93.3% of cases and achieves a preliminary accuracy of 88.0% when matching patient-level information at the criterion level against a baseline defined by human experts. Utilizing LLM feedback reveals that 39.3% criteria that were initially considered incorrect are either ambiguous or inaccurately annotated, leading to a total model accuracy of 92.7% after refining our human baseline. In summary, we present an end-to-end pipeline for clinical trial matching using LLMs, demonstrating high precision in screening and matching trials to individual patients, even outperforming the performance of qualified medical doctors. Our fully end-to-end pipeline can operate autonomously or with human supervision and is not restricted to oncology, offering a scalable solution for enhancing patient-trial matching in real-world settings.
Read more7/19/2024
💬
0
Matching Patients to Clinical Trials with Large Language Models
Qiao Jin, Zifeng Wang, Charalampos S. Floudas, Fangyuan Chen, Changlin Gong, Dara Bracken-Clarke, Elisabetta Xue, Yifan Yang, Jimeng Sun, Zhiyong Lu
Clinical trials are often hindered by the challenge of patient recruitment. In this work, we introduce TrialGPT, a first-of-its-kind large language model (LLM) framework to assist patient-to-trial matching. Given a patient note, TrialGPT predicts the patient's eligibility on a criterion-by-criterion basis and then consolidates these predictions to assess the patient's eligibility for the target trial. We evaluate the trial-level prediction performance of TrialGPT on three publicly available cohorts of 184 patients with over 18,000 trial annotations. We also engaged three physicians to label over 1,000 patient-criterion pairs to assess its criterion-level prediction accuracy. Experimental results show that TrialGPT achieves a criterion-level accuracy of 87.3% with faithful explanations, close to the expert performance (88.7%-90.0%). The aggregated TrialGPT scores are highly correlated with human eligibility judgments, and they outperform the best-competing models by 32.6% to 57.2% in ranking and excluding clinical trials. Furthermore, our user study reveals that TrialGPT can significantly reduce the screening time (by 42.6%) in a real-life clinical trial matching task. These results and analyses have demonstrated promising opportunities for clinical trial matching with LLMs such as TrialGPT.
Read more4/30/2024
0
Zero-Shot Clinical Trial Patient Matching with LLMs
Michael Wornow, Alejandro Lozano, Dev Dash, Jenelle Jindal, Kenneth W. Mahaffey, Nigam H. Shah
Matching patients to clinical trials is a key unsolved challenge in bringing new drugs to market. Today, identifying patients who meet a trial's eligibility criteria is highly manual, taking up to 1 hour per patient. Automated screening is challenging, however, as it requires understanding unstructured clinical text. Large language models (LLMs) offer a promising solution. In this work, we explore their application to trial matching. First, we design an LLM-based system which, given a patient's medical history as unstructured clinical text, evaluates whether that patient meets a set of inclusion criteria (also specified as free text). Our zero-shot system achieves state-of-the-art scores on the n2c2 2018 cohort selection benchmark. Second, we improve the data and cost efficiency of our method by identifying a prompting strategy which matches patients an order of magnitude faster and more cheaply than the status quo, and develop a two-stage retrieval pipeline that reduces the number of tokens processed by up to a third while retaining high performance. Third, we evaluate the interpretability of our system by having clinicians evaluate the natural language justifications generated by the LLM for each eligibility decision, and show that it can output coherent explanations for 97% of its correct decisions and 75% of its incorrect ones. Our results establish the feasibility of using LLMs to accelerate clinical trial operations.
Read more4/11/2024