Towards Efficient Patient Recruitment for Clinical Trials: Application of a Prompt-Based Learning Model
2404.16198
0
0
📈
Abstract
Objective: Clinical trials are essential for advancing pharmaceutical interventions, but they face a bottleneck in selecting eligible participants. Although leveraging electronic health records (EHR) for recruitment has gained popularity, the complex nature of unstructured medical texts presents challenges in efficiently identifying participants. Natural Language Processing (NLP) techniques have emerged as a solution with a recent focus on transformer models. In this study, we aimed to evaluate the performance of a prompt-based large language model for the cohort selection task from unstructured medical notes collected in the EHR. Methods: To process the medical records, we selected the most related sentences of the records to the eligibility criteria needed for the trial. The SNOMED CT concepts related to each eligibility criterion were collected. Medical records were also annotated with MedCAT based on the SNOMED CT ontology. Annotated sentences including concepts matched with the criteria-relevant terms were extracted. A prompt-based large language model (Generative Pre-trained Transformer (GPT) in this study) was then used with the extracted sentences as the training set. To assess its effectiveness, we evaluated the model's performance using the dataset from the 2018 n2c2 challenge, which aimed to classify medical records of 311 patients based on 13 eligibility criteria through NLP techniques. Results: Our proposed model showed the overall micro and macro F measures of 0.9061 and 0.8060 which were among the highest scores achieved by the experiments performed with this dataset. Conclusion: The application of a prompt-based large language model in this study to classify patients based on eligibility criteria received promising scores. Besides, we proposed a method of extractive summarization with the aid of SNOMED CT ontology that can be also applied to other medical texts.
Create account to get full access
Overview
- Evaluating the use of a large language model for patient selection in clinical trials
- Leveraging electronic health records (EHR) and natural language processing (NLP) techniques to identify eligible participants
- Proposing a method of extractive summarization using the SNOMED CT ontology
Plain English Explanation
Conducting clinical trials is crucial for developing new medical treatments, but finding the right patients to participate can be challenging. Researchers are exploring ways to use electronic health records (EHRs) to help identify eligible participants, as these records contain a wealth of medical information. However, the complex and unstructured nature of the text in EHRs makes it difficult to efficiently match patients to clinical trial requirements.
This study investigates the use of a large language model - a type of artificial intelligence that can understand and generate human-like text - to help with the patient selection process. The researchers used a prompt-based approach, where the model was given specific instructions (or "prompts") to classify patients based on their eligibility criteria.
To prepare the data, the researchers identified the most relevant sentences from the EHR records and annotated them using the SNOMED CT medical terminology. This allowed them to match the patient information to the specific criteria needed for the clinical trial.
The researchers then trained the large language model on this annotated data and evaluated its performance on a dataset from a previous study. The results showed that the model was able to accurately classify patients based on the eligibility criteria, achieving high scores on various evaluation metrics.
This approach demonstrates the potential of using large language models to streamline the patient selection process for clinical trials, which could ultimately help accelerate the development of new medical treatments. The method of extractive summarization using the SNOMED CT ontology could also be applied to other types of medical text analysis tasks.
Technical Explanation
The researchers aimed to evaluate the performance of a prompt-based large language model for the task of cohort selection from unstructured medical notes collected in electronic health records (EHRs). To process the medical records, they selected the most relevant sentences based on the eligibility criteria for a clinical trial. They then collected the SNOMED CT concepts related to each eligibility criterion and used the MedCAT tool to annotate the medical records accordingly.
The annotated sentences containing concepts matched with the criteria-relevant terms were extracted and used as the training set for a prompt-based large language model. In this study, the researchers used the Generative Pre-trained Transformer (GPT) model.
To assess the effectiveness of the model, the researchers evaluated its performance using a dataset from the 2018 n2c2 challenge, which aimed to classify medical records of 311 patients based on 13 eligibility criteria through NLP techniques. The proposed model achieved an overall micro F-measure of 0.9061 and a macro F-measure of 0.8060, which were among the highest scores reported for this dataset.
The researchers also proposed a method of extractive summarization using the SNOMED CT ontology, which they suggest can be applied to other types of medical text analysis tasks.
Critical Analysis
The researchers have presented a promising approach for leveraging large language models to improve the patient selection process for clinical trials. The use of a prompt-based model and the integration of the SNOMED CT ontology appear to be effective strategies for extracting relevant information from unstructured medical text.
However, the study does have some limitations. The evaluation was conducted on a relatively small dataset, and the researchers acknowledge that further testing on larger and more diverse datasets would be necessary to fully validate the model's performance. Additionally, the study does not address potential biases or ethical considerations that may arise from using AI-based systems for patient selection, which is an important area for further exploration.
It would also be interesting to see how the model's performance compares to other bespoke large language models that have been developed specifically for biomedical applications. Exploring the generalizability of the approach to other clinical trial domains or healthcare tasks could also be a fruitful avenue for future research.
Conclusion
This study demonstrates the potential of using a prompt-based large language model to streamline the patient selection process for clinical trials. By leveraging the SNOMED CT ontology and natural language processing techniques, the researchers were able to develop an effective method for extracting relevant information from unstructured medical records.
The promising results suggest that this approach could help accelerate the development of new medical interventions by improving the efficiency and accuracy of participant recruitment. However, further research is needed to address the limitations of the study and explore the broader implications of using AI-based systems in healthcare decision-making.
Overall, this work contributes to the growing body of research on the application of large language models in biomedicine and highlights the ongoing efforts to harness the power of artificial intelligence to enhance clinical research and patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Matching Patients to Clinical Trials with Large Language Models
Qiao Jin, Zifeng Wang, Charalampos S. Floudas, Fangyuan Chen, Changlin Gong, Dara Bracken-Clarke, Elisabetta Xue, Yifan Yang, Jimeng Sun, Zhiyong Lu
0
0
Clinical trials are often hindered by the challenge of patient recruitment. In this work, we introduce TrialGPT, a first-of-its-kind large language model (LLM) framework to assist patient-to-trial matching. Given a patient note, TrialGPT predicts the patient's eligibility on a criterion-by-criterion basis and then consolidates these predictions to assess the patient's eligibility for the target trial. We evaluate the trial-level prediction performance of TrialGPT on three publicly available cohorts of 184 patients with over 18,000 trial annotations. We also engaged three physicians to label over 1,000 patient-criterion pairs to assess its criterion-level prediction accuracy. Experimental results show that TrialGPT achieves a criterion-level accuracy of 87.3% with faithful explanations, close to the expert performance (88.7%-90.0%). The aggregated TrialGPT scores are highly correlated with human eligibility judgments, and they outperform the best-competing models by 32.6% to 57.2% in ranking and excluding clinical trials. Furthermore, our user study reveals that TrialGPT can significantly reduce the screening time (by 42.6%) in a real-life clinical trial matching task. These results and analyses have demonstrated promising opportunities for clinical trial matching with LLMs such as TrialGPT.
4/30/2024
💬
PRISM: Patient Records Interpretation for Semantic Clinical Trial Matching using Large Language Models
Shashi Kant Gupta, Aditya Basu, Mauro Nievas, Jerrin Thomas, Nathan Wolfrath, Adhitya Ramamurthi, Bradley Taylor, Anai N. Kothari, Regina Schwind, Therica M. Miller, Sorena Nadaf-Rahrov, Yanshan Wang, Hrituraj Singh
0
0
Clinical trial matching is the task of identifying trials for which patients may be potentially eligible. Typically, this task is labor-intensive and requires detailed verification of patient electronic health records (EHRs) against the stringent inclusion and exclusion criteria of clinical trials. This process is manual, time-intensive, and challenging to scale up, resulting in many patients missing out on potential therapeutic options. Recent advancements in Large Language Models (LLMs) have made automating patient-trial matching possible, as shown in multiple concurrent research studies. However, the current approaches are confined to constrained, often synthetic datasets that do not adequately mirror the complexities encountered in real-world medical data. In this study, we present the first, end-to-end large-scale empirical evaluation of clinical trial matching using real-world EHRs. Our study showcases the capability of LLMs to accurately match patients with appropriate clinical trials. We perform experiments with proprietary LLMs, including GPT-4 and GPT-3.5, as well as our custom fine-tuned model called OncoLLM and show that OncoLLM, despite its significantly smaller size, not only outperforms GPT-3.5 but also matches the performance of qualified medical doctors. All experiments were carried out on real-world EHRs that include clinical notes and available clinical trials from a single cancer center in the United States.
4/30/2024

Edinburgh Clinical NLP at MEDIQA-CORR 2024: Guiding Large Language Models with Hints
Aryo Pradipta Gema, Chaeeun Lee, Pasquale Minervini, Luke Daines, T. Ian Simpson, Beatrice Alex
0
0
The MEDIQA-CORR 2024 shared task aims to assess the ability of Large Language Models (LLMs) to identify and correct medical errors in clinical notes. In this study, we evaluate the capability of general LLMs, specifically GPT-3.5 and GPT-4, to identify and correct medical errors with multiple prompting strategies. Recognising the limitation of LLMs in generating accurate corrections only via prompting strategies, we propose incorporating error-span predictions from a smaller, fine-tuned model in two ways: 1) by presenting it as a hint in the prompt and 2) by framing it as multiple-choice questions from which the LLM can choose the best correction. We found that our proposed prompting strategies significantly improve the LLM's ability to generate corrections. Our best-performing solution with 8-shot + CoT + hints ranked sixth in the shared task leaderboard. Additionally, our comprehensive analyses show the impact of the location of the error sentence, the prompted role, and the position of the multiple-choice option on the accuracy of the LLM. This prompts further questions about the readiness of LLM to be implemented in real-world clinical settings.
5/29/2024
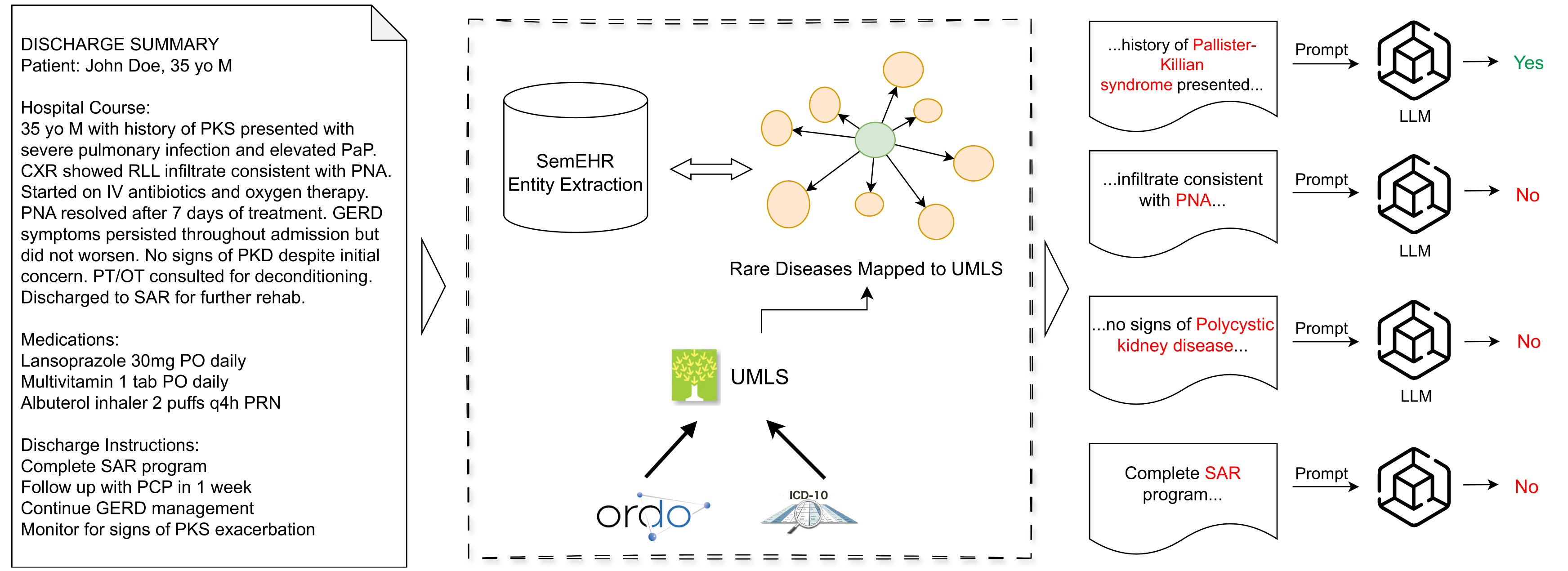
Retrieving and Refining: A Hybrid Framework with Large Language Models for Rare Disease Identification
Jinge Wu, Hang Dong, Zexi Li, Arijit Patra, Honghan Wu
0
0
The infrequency and heterogeneity of clinical presentations in rare diseases often lead to underdiagnosis and their exclusion from structured datasets. This necessitates the utilization of unstructured text data for comprehensive analysis. However, the manual identification from clinical reports is an arduous and intrinsically subjective task. This study proposes a novel hybrid approach that synergistically combines a traditional dictionary-based natural language processing (NLP) tool with the powerful capabilities of large language models (LLMs) to enhance the identification of rare diseases from unstructured clinical notes. We comprehensively evaluate various prompting strategies on six large language models (LLMs) of varying sizes and domains (general and medical). This evaluation encompasses zero-shot, few-shot, and retrieval-augmented generation (RAG) techniques to enhance the LLMs' ability to reason about and understand contextual information in patient reports. The results demonstrate effectiveness in rare disease identification, highlighting the potential for identifying underdiagnosed patients from clinical notes.
5/20/2024