Privacy-Preserving Split Learning with Vision Transformers using Patch-Wise Random and Noisy CutMix

0
Sign in to get full access
Overview
- Privacy-preserving split learning with vision transformers
- Patch-wise random and noisy CutMix techniques to enhance privacy
- Experiments on image classification tasks
Plain English Explanation
In this paper, the researchers explore a privacy-preserving approach to machine learning called split learning. Split learning is a technique where the machine learning model is divided between two parties - one party holds the input data, while the other party holds the model parameters. This allows training to happen without fully sharing the data, preserving privacy.
The researchers use vision transformers, a type of machine learning model well-suited for image classification tasks. To further enhance privacy, they introduce two new techniques:
- Patch-wise random: Randomly shuffling the image patches before sending them to the model, making it harder to reconstruct the original image.
- Noisy CutMix: Combining random image patches with noise, again obfuscating the original image data.
By using these privacy-preserving techniques in a split learning setup, the researchers aim to train effective image classification models while protecting the privacy of the input data.
Technical Explanation
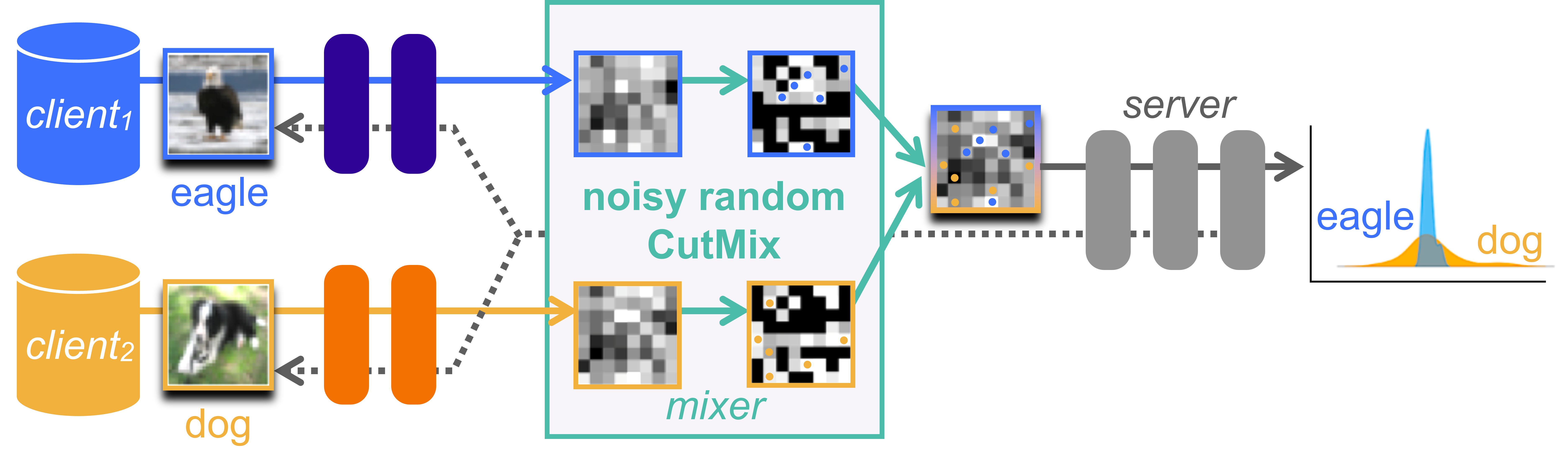
The paper presents a privacy-preserving split learning framework using vision transformers. In this setup, the input image is first divided into small patches, which are then randomly shuffled and combined with noise (using the CutMix technique) before being sent to the vision transformer model.
The model itself is split between two parties - the client (who holds the input data) and the server (who holds the model parameters). During training, the client sends the obfuscated image patches to the server, which then performs the forward pass of the vision transformer. The server returns intermediate representations back to the client, who can then compute the loss and perform backpropagation to update the model parameters.
This approach allows for effective image classification while preserving the privacy of the input data, as the original images are never fully revealed to the server. The researchers evaluate their method on standard image classification benchmarks and show that it achieves competitive performance compared to a centralized training setup.
Critical Analysis
The paper presents a novel and promising approach to privacy-preserving machine learning using split learning and vision transformers. The proposed patch-wise random and noisy CutMix techniques effectively obfuscate the input data, making it harder for the server to reconstruct the original images.
However, the paper does not provide a thorough analysis of the privacy guarantees of this approach. While the techniques seem to be effective at protecting the input data, the authors do not quantify the level of privacy preservation or discuss potential attacks that could be used to recover the original images. Additionally, the paper does not address the potential impact of the server's knowledge of the model architecture and the intermediate representations on the privacy of the system.
Further research is needed to fully understand the privacy implications of this approach and to explore additional techniques for enhancing the privacy guarantees, such as differential privacy or secure multi-party computation.
Conclusion
This paper presents a privacy-preserving split learning framework using vision transformers and introduces two novel techniques, patch-wise random and noisy CutMix, to enhance the privacy of the input data. The proposed approach shows promising results for image classification tasks, while preserving the privacy of the input data. Further research is needed to better understand the privacy guarantees of this approach and to explore additional techniques for strengthening the privacy protections.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Privacy-Preserving Split Learning with Vision Transformers using Patch-Wise Random and Noisy CutMix
Seungeun Oh, Sihun Baek, Jihong Park, Hyelin Nam, Praneeth Vepakomma, Ramesh Raskar, Mehdi Bennis, Seong-Lyun Kim
In computer vision, the vision transformer (ViT) has increasingly superseded the convolutional neural network (CNN) for improved accuracy and robustness. However, ViT's large model sizes and high sample complexity make it difficult to train on resource-constrained edge devices. Split learning (SL) emerges as a viable solution, leveraging server-side resources to train ViTs while utilizing private data from distributed devices. However, SL requires additional information exchange for weight updates between the device and the server, which can be exposed to various attacks on private training data. To mitigate the risk of data breaches in classification tasks, inspired from the CutMix regularization, we propose a novel privacy-preserving SL framework that injects Gaussian noise into smashed data and mixes randomly chosen patches of smashed data across clients, coined DP-CutMixSL. Our analysis demonstrates that DP-CutMixSL is a differentially private (DP) mechanism that strengthens privacy protection against membership inference attacks during forward propagation. Through simulations, we show that DP-CutMixSL improves privacy protection against membership inference attacks, reconstruction attacks, and label inference attacks, while also improving accuracy compared to DP-SL and DP-MixSL.
Read more8/6/2024

0
New!Enhancing Privacy in ControlNet and Stable Diffusion via Split Learning
Dixi Yao
With the emerging trend of large generative models, ControlNet is introduced to enable users to fine-tune pre-trained models with their own data for various use cases. A natural question arises: how can we train ControlNet models while ensuring users' data privacy across distributed devices? Exploring different distributed training schemes, we find conventional federated learning and split learning unsuitable. Instead, we propose a new distributed learning structure that eliminates the need for the server to send gradients back. Through a comprehensive evaluation of existing threats, we discover that in the context of training ControlNet with split learning, most existing attacks are ineffective, except for two mentioned in previous literature. To counter these threats, we leverage the properties of diffusion models and design a new timestep sampling policy during forward processes. We further propose a privacy-preserving activation function and a method to prevent private text prompts from leaving clients, tailored for image generation with diffusion models. Our experimental results demonstrate that our algorithms and systems greatly enhance the efficiency of distributed training for ControlNet while ensuring users' data privacy without compromising image generation quality.
Read more9/16/2024

0
PriPHiT: Privacy-Preserving Hierarchical Training of Deep Neural Networks
Yamin Sepehri, Pedram Pad, Pascal Frossard, L. Andrea Dunbar
The training phase of deep neural networks requires substantial resources and as such is often performed on cloud servers. However, this raises privacy concerns when the training dataset contains sensitive content, e.g., face images. In this work, we propose a method to perform the training phase of a deep learning model on both an edge device and a cloud server that prevents sensitive content being transmitted to the cloud while retaining the desired information. The proposed privacy-preserving method uses adversarial early exits to suppress the sensitive content at the edge and transmits the task-relevant information to the cloud. This approach incorporates noise addition during the training phase to provide a differential privacy guarantee. We extensively test our method on different facial datasets with diverse face attributes using various deep learning architectures, showcasing its outstanding performance. We also demonstrate the effectiveness of privacy preservation through successful defenses against different white-box and deep reconstruction attacks.
Read more8/12/2024
👀
0
Make Split, not Hijack: Preventing Feature-Space Hijacking Attacks in Split Learning
Tanveer Khan, Mindaugas Budzys, Antonis Michalas
The popularity of Machine Learning (ML) makes the privacy of sensitive data more imperative than ever. Collaborative learning techniques like Split Learning (SL) aim to protect client data while enhancing ML processes. Though promising, SL has been proved to be vulnerable to a plethora of attacks, thus raising concerns about its effectiveness on data privacy. In this work, we introduce a hybrid approach combining SL and Function Secret Sharing (FSS) to ensure client data privacy. The client adds a random mask to the activation map before sending it to the servers. The servers cannot access the original function but instead work with shares generated using FSS. Consequently, during both forward and backward propagation, the servers cannot reconstruct the client's raw data from the activation map. Furthermore, through visual invertibility, we demonstrate that the server is incapable of reconstructing the raw image data from the activation map when using FSS. It enhances privacy by reducing privacy leakage compared to other SL-based approaches where the server can access client input information. Our approach also ensures security against feature space hijacking attack, protecting sensitive information from potential manipulation. Our protocols yield promising results, reducing communication overhead by over 2x and training time by over 7x compared to the same model with FSS, without any SL. Also, we show that our approach achieves >96% accuracy and remains equivalent to the plaintext models.
Read more4/16/2024