Self-supervised visual learning in the low-data regime: a comparative evaluation

0

Sign in to get full access
Self-supervised Visual Learning in the Low-Data Regime: A Comparative Evaluation
Overview
- This paper evaluates different self-supervised learning approaches for visual tasks with limited training data.
- The authors compare the performance of several self-supervised pretext tasks on classification, detection, and segmentation benchmarks.
- The results provide insights into which self-supervised techniques work best when labeled data is scarce.
Plain English Explanation
Self-supervised learning is a way for AI models to learn useful features from data without needing labeled examples. The models are trained to solve "pretext tasks" that don't require manual labeling, like predicting the rotation of an image or the relative positioning of image patches. These pretext tasks help the model learn representations that can then be applied to real-world tasks like image classification or object detection.
This paper looks at how well different self-supervised pretext tasks perform when only a small amount of labeled data is available. The authors train self-supervised models on large unlabeled datasets, then fine-tune them on classification, detection, and segmentation benchmarks with limited labeled data. They compare the performance of models trained with different self-supervised pretext tasks to understand which approaches work best in low-data regimes.
The results provide guidance on which self-supervised techniques are most effective when labeled data is scarce, which is important for applying AI to real-world problems where labeled data is often limited. The findings could help inform the development of more robust and data-efficient AI systems for a wide range of applications.
Technical Explanation
The paper evaluates several self-supervised pretext tasks, including image rotation prediction, relative patch prediction, and contrastive learning approaches like SimCLR and BYOL. The authors train models on the ImageNet dataset using these pretext tasks, then fine-tune the models on classification, detection, and segmentation benchmarks using varying amounts of labeled data (ranging from 1% to 100% of the full training set).
The results show that self-supervised models outperform fully supervised baselines when labeled data is scarce, particularly for tasks like object detection and semantic segmentation. Contrastive learning approaches like SimCLR and BYOL generally perform best, although the optimal pretext task varies depending on the target task and amount of labeled data available.
The authors also analyze the representations learned by the different self-supervised models, finding that contrastive approaches capture more semantic and task-relevant features compared to other pretext tasks. This helps explain their superior performance, especially in low-data regimes.
Critical Analysis
The paper provides a comprehensive evaluation of self-supervised learning techniques in the low-data setting, using a diverse set of benchmarks and pretext tasks. The findings offer valuable insights for practitioners looking to apply self-supervised learning in real-world scenarios with limited labeled data.
One limitation of the study is that it focuses on a relatively narrow set of self-supervised approaches, particularly contrastive methods like SimCLR and BYOL. Other promising self-supervised techniques, such as masked image modeling or generative self-supervised learning, are not evaluated. Future research could expand the comparison to include a wider range of self-supervised pretext tasks.
Additionally, the paper does not explore the effects of dataset size or diversity on self-supervised learning performance. Understanding how self-supervised models scale with the quantity and quality of unlabeled pretraining data could provide further insights.
Overall, this work makes an important contribution to the understanding of self-supervised learning in low-resource settings. The findings can help guide the development of more sample-efficient and robust AI systems for a variety of applications.
Conclusion
This paper provides a comparative evaluation of self-supervised learning approaches in the low-data regime, using a range of visual task benchmarks. The results show that self-supervised models can outperform fully supervised baselines when labeled data is scarce, with contrastive learning techniques like SimCLR and BYOL generally performing best.
The insights from this work can inform the design of more data-efficient and broadly applicable AI systems, which is crucial for expanding the reach of machine learning technology to real-world problems where labeled data is often limited. By better understanding the strengths and limitations of different self-supervised approaches, researchers and practitioners can develop more robust and versatile AI solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-supervised visual learning in the low-data regime: a comparative evaluation
Sotirios Konstantakos, Despina Ioanna Chalkiadaki, Ioannis Mademlis, Yuki M. Asano, Efstratios Gavves, Georgios Th. Papadopoulos
Self-Supervised Learning (SSL) is a valuable and robust training methodology for contemporary Deep Neural Networks (DNNs), enabling unsupervised pretraining on a `pretext task' that does not require ground-truth labels/annotation. This allows efficient representation learning from massive amounts of unlabeled training data, which in turn leads to increased accuracy in a `downstream task' by exploiting supervised transfer learning. Despite the relatively straightforward conceptualization and applicability of SSL, it is not always feasible to collect and/or to utilize very large pretraining datasets, especially when it comes to real-world application settings. In particular, in cases of specialized and domain-specific application scenarios, it may not be achievable or practical to assemble a relevant image pretraining dataset in the order of millions of instances or it could be computationally infeasible to pretrain at this scale. This motivates an investigation on the effectiveness of common SSL pretext tasks, when the pretraining dataset is of relatively limited/constrained size. In this context, this work introduces a taxonomy of modern visual SSL methods, accompanied by detailed explanations and insights regarding the main categories of approaches, and, subsequently, conducts a thorough comparative experimental evaluation in the low-data regime, targeting to identify: a) what is learnt via low-data SSL pretraining, and b) how do different SSL categories behave in such training scenarios. Interestingly, for domain-specific downstream tasks, in-domain low-data SSL pretraining outperforms the common approach of large-scale pretraining on general datasets. Grounded on the obtained results, valuable insights are highlighted regarding the performance of each category of SSL methods, which in turn suggest straightforward future research directions in the field.
Read more4/29/2024
0
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Markus Marks, Manuel Knott, Neehar Kondapaneni, Elijah Cole, Thijs Defraeye, Fernando Perez-Cruz, Pietro Perona
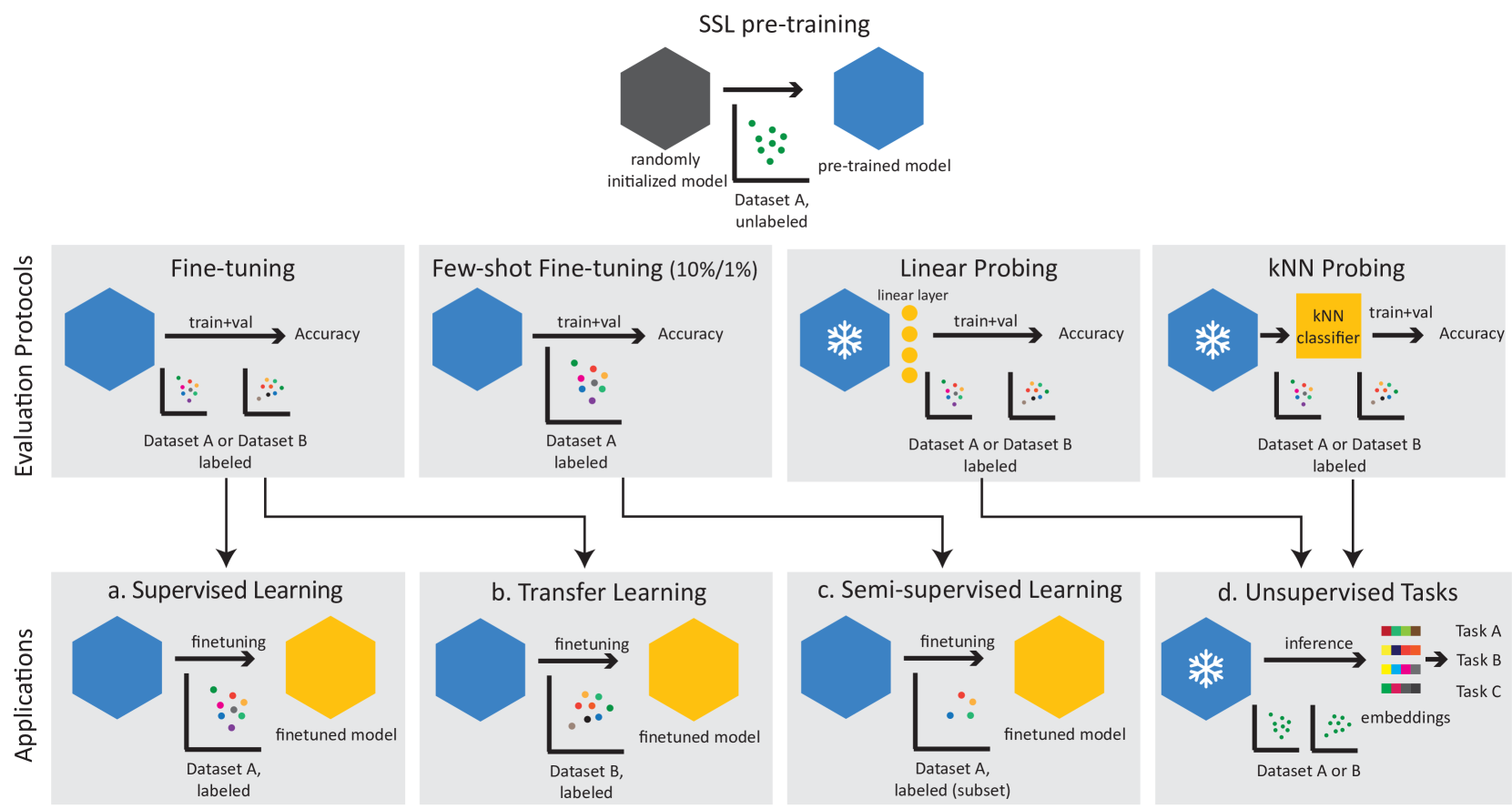
Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Read more7/19/2024

0
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Asifullah Khan, Anabia Sohail, Mustansar Fiaz, Mehdi Hassan, Tariq Habib Afridi, Sibghat Ullah Marwat, Farzeen Munir, Safdar Ali, Hannan Naseem, Muhammad Zaigham Zaheer, Kamran Ali, Tangina Sultana, Ziaurrehman Tanoli, Naeem Akhter
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to utilize this vast amount of unlabeled data available. Thus it is better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is limited labelled data available. In this survey, we develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
Read more9/23/2024
🌀
0
A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, Dacheng Tao
Deep supervised learning algorithms typically require a large volume of labeled data to achieve satisfactory performance. However, the process of collecting and labeling such data can be expensive and time-consuming. Self-supervised learning (SSL), a subset of unsupervised learning, aims to learn discriminative features from unlabeled data without relying on human-annotated labels. SSL has garnered significant attention recently, leading to the development of numerous related algorithms. However, there is a dearth of comprehensive studies that elucidate the connections and evolution of different SSL variants. This paper presents a review of diverse SSL methods, encompassing algorithmic aspects, application domains, three key trends, and open research questions. Firstly, we provide a detailed introduction to the motivations behind most SSL algorithms and compare their commonalities and differences. Secondly, we explore representative applications of SSL in domains such as image processing, computer vision, and natural language processing. Lastly, we discuss the three primary trends observed in SSL research and highlight the open questions that remain. A curated collection of valuable resources can be accessed at https://github.com/guijiejie/SSL.
Read more7/16/2024