Probabilistic Regular Tree Priors for Scientific Symbolic Reasoning

0
⚙️
Sign in to get full access
Overview
- This paper introduces a novel approach for scientific symbolic reasoning using probabilistic regular tree priors.
- The authors propose a framework that combines symbolic and probabilistic methods to tackle complex mathematical and scientific tasks.
- The framework aims to leverage the strengths of both symbolic and machine learning techniques to improve the interpretability, generalization, and performance of scientific reasoning systems.
Plain English Explanation
The paper presents a new way to handle complex scientific and mathematical problems using a combination of symbolic reasoning and probabilistic methods. Symbolic reasoning refers to the use of logical rules and representations to solve problems, while probabilistic methods involve using statistical and machine learning techniques.
The key idea is to create a system that can take advantage of the strengths of both approaches. Symbolic reasoning can provide clear, interpretable explanations for how a problem is being solved. However, it can struggle with handling uncertainty and dealing with messy, real-world data. Probabilistic methods, on the other hand, excel at handling uncertainty and learning patterns from data, but the resulting models can be opaque and difficult to interpret.
By combining symbolic and probabilistic techniques, the authors aim to create a system that is both interpretable and capable of handling complex, uncertain data. This could be particularly useful for scientific and mathematical reasoning tasks, where clear explanations are often important, but the underlying problems may involve a lot of uncertainty and noise.
The paper introduces a specific framework that uses "probabilistic regular tree priors" to guide the symbolic reasoning process. This means that the system learns a probabilistic model of the kind of symbolic structures (e.g., mathematical equations, logical expressions) that are likely to be relevant for a given problem, and then uses this model to guide the search for the best symbolic solution.
Overall, this research represents an interesting attempt to bridge the gap between symbolic and machine learning approaches in order to create more powerful and interpretable systems for scientific and mathematical reasoning.
Technical Explanation
The paper presents a novel framework for scientific symbolic reasoning that combines probabilistic and symbolic methods. The key idea is to use "probabilistic regular tree priors" to guide the symbolic reasoning process.
The authors first define a probabilistic model over a space of symbolic trees, which represent the kinds of symbolic structures (e.g., mathematical equations, logical expressions) that are likely to be relevant for a given problem. This probabilistic model is trained on a dataset of relevant symbolic structures.
During the reasoning process, the system uses this probabilistic model to guide the search for the best symbolic solution to a given problem. Rather than exploring the space of all possible symbolic structures, the system focuses its search on the most promising regions of the space, as indicated by the probabilistic model.
The authors demonstrate the effectiveness of this approach through a series of experiments on both synthetic and real-world scientific tasks, such as symbolic regression and mathematical reasoning. The results show that the proposed framework can outperform both purely symbolic and purely probabilistic approaches, particularly in terms of interpretability and generalization.
Critical Analysis
The paper presents a compelling approach to combining symbolic and probabilistic methods for scientific reasoning, and the experimental results are promising. However, there are a few potential limitations and areas for further research:
-
Scalability: The authors focus on relatively small-scale problems in their experiments. It's unclear how well the proposed framework would scale to larger, more complex scientific reasoning tasks, which may require more sophisticated probabilistic models and search techniques.
-
Robustness: The paper does not extensively explore the robustness of the framework to noisy or incomplete data, which is a common challenge in real-world scientific applications. Further research is needed to understand how the framework performs in the face of such challenges.
-
Generalization: While the authors demonstrate improved generalization compared to purely symbolic or probabilistic approaches, the extent of the generalization capabilities is not fully explored. It would be valuable to investigate the framework's ability to handle a wider range of scientific domains and problem types.
-
Interpretability: The authors claim that the proposed framework improves interpretability, but the specific mechanisms by which this is achieved could be explored in more depth. It would be useful to understand how the probabilistic models and symbolic structures interact to provide interpretable explanations.
Despite these potential limitations, the paper represents an important step towards bridging the gap between symbolic and machine learning approaches for scientific reasoning. The probabilistic regular tree priors framework showcases the potential benefits of combining these complementary techniques, and the authors have laid the groundwork for further research in this direction.
Conclusion
This paper introduces a novel framework for scientific symbolic reasoning that combines probabilistic and symbolic methods. The key innovation is the use of "probabilistic regular tree priors" to guide the symbolic reasoning process, allowing the system to leverage the strengths of both approaches.
The experimental results demonstrate the potential of this framework to improve the interpretability, generalization, and performance of scientific reasoning systems, particularly for tasks such as symbolic regression and mathematical reasoning. While the paper identifies some potential limitations, it represents an important step towards developing more powerful and versatile tools for tackling complex scientific and mathematical problems.
Overall, this research highlights the value of integrating symbolic and probabilistic techniques to create more robust and explainable systems for scientific reasoning, with the potential to drive progress in a wide range of scientific and technological domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Probabilistic Regular Tree Priors for Scientific Symbolic Reasoning
Tim Schneider, Amin Totounferoush, Wolfgang Nowak, Steffen Staab
Symbolic Regression (SR) allows for the discovery of scientific equations from data. To limit the large search space of possible equations, prior knowledge has been expressed in terms of formal grammars that characterize subsets of arbitrary strings. However, there is a mismatch between context-free grammars required to express the set of syntactically correct equations, missing closure properties of the former, and a tree structure of the latter. Our contributions are to (i) compactly express experts' prior beliefs about which equations are more likely to be expected by probabilistic Regular Tree Expressions (pRTE), and (ii) adapt Bayesian inference to make such priors efficiently available for symbolic regression encoded as finite state machines. Our scientific case studies show its effectiveness in soil science to find sorption isotherms and for modeling hyper-elastic materials.
Read more6/11/2024

0
Discovering symbolic expressions with parallelized tree search
Kai Ruan, Ze-Feng Gao, Yike Guo, Hao Sun, Ji-Rong Wen, Yang Liu
Symbolic regression plays a crucial role in modern scientific research thanks to its capability of discovering concise and interpretable mathematical expressions from data. A grand challenge lies in the arduous search for parsimonious and generalizable mathematical formulas, in an infinite search space, while intending to fit the training data. Existing algorithms have faced a critical bottleneck of accuracy and efficiency over a decade when handling problems of complexity, which essentially hinders the pace of applying symbolic regression for scientific exploration across interdisciplinary domains. To this end, we introduce a parallelized tree search (PTS) model to efficiently distill generic mathematical expressions from limited data. Through a series of extensive experiments, we demonstrate the superior accuracy and efficiency of PTS for equation discovery, which greatly outperforms the state-of-the-art baseline models on over 80 synthetic and experimental datasets (e.g., lifting its performance by up to 99% accuracy improvement and one-order of magnitude speed up). PTS represents a key advance in accurate and efficient data-driven discovery of symbolic, interpretable models (e.g., underlying physical laws) and marks a pivotal transition towards scalable symbolic learning.
Read more7/8/2024
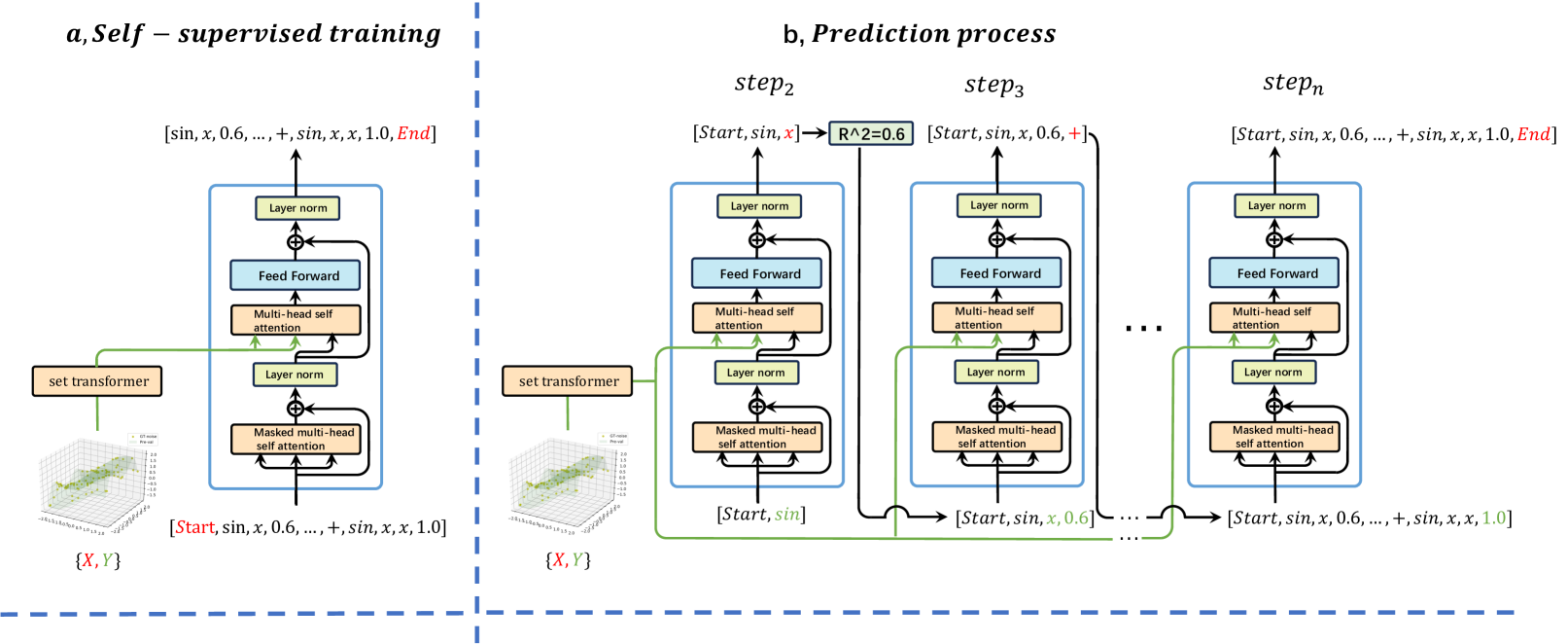
0
Generative Pre-Trained Transformer for Symbolic Regression Base In-Context Reinforcement Learning
Yanjie Li, Weijun Li, Lina Yu, Min Wu, Jingyi Liu, Wenqiang Li, Meilan Hao, Shu Wei, Yusong Deng
The mathematical formula is the human language to describe nature and is the essence of scientific research. Finding mathematical formulas from observational data is a major demand of scientific research and a major challenge of artificial intelligence. This area is called symbolic regression. Originally symbolic regression was often formulated as a combinatorial optimization problem and solved using GP or reinforcement learning algorithms. These two kinds of algorithms have strong noise robustness ability and good Versatility. However, inference time usually takes a long time, so the search efficiency is relatively low. Later, based on large-scale pre-training data proposed, such methods use a large number of synthetic data points and expression pairs to train a Generative Pre-Trained Transformer(GPT). Then this GPT can only need to perform one forward propagation to obtain the results, the advantage is that the inference speed is very fast. However, its performance is very dependent on the training data and performs poorly on data outside the training set, which leads to poor noise robustness and Versatility of such methods. So, can we combine the advantages of the above two categories of SR algorithms? In this paper, we propose textbf{FormulaGPT}, which trains a GPT using massive sparse reward learning histories of reinforcement learning-based SR algorithms as training data. After training, the SR algorithm based on reinforcement learning is distilled into a Transformer. When new test data comes, FormulaGPT can directly generate a reinforcement learning process and automatically update the learning policy in context. Tested on more than ten datasets including SRBench, formulaGPT achieves the state-of-the-art performance in fitting ability compared with four baselines. In addition, it achieves satisfactory results in noise robustness, versatility, and inference efficiency.
Read more4/10/2024
↗️
0
Ensembles of Probabilistic Regression Trees
Alexandre Seiller (APTIKAL), 'Eric Gaussier (APTIKAL), Emilie Devijver (APTIKAL), Marianne Clausel (IECL), Sami Alkhoury
Tree-based ensemble methods such as random forests, gradient-boosted trees, and Bayesianadditive regression trees have been successfully used for regression problems in many applicationsand research studies. In this paper, we study ensemble versions of probabilisticregression trees that provide smooth approximations of the objective function by assigningeach observation to each region with respect to a probability distribution. We prove thatthe ensemble versions of probabilistic regression trees considered are consistent, and experimentallystudy their bias-variance trade-off and compare them with the state-of-the-art interms of performance prediction.
Read more6/21/2024