ProbTalk3D: Non-Deterministic Emotion Controllable Speech-Driven 3D Facial Animation Synthesis Using VQ-VAE

0

Sign in to get full access
Overview
- ProbTalk3D is a deep learning model for synthesizing non-deterministic, emotion-controllable 3D facial animations from speech input.
- It uses a Variational Quantized Variational Autoencoder (VQ-VAE) architecture to generate diverse facial animation sequences.
- The model allows for controlling the emotional expression of the generated animations through conditional inputs.
Plain English Explanation
ProbTalk3D is a system that can create 3D animations of a person's face based on their speech, and it can control the emotional expression of the animations. This allows for generating a variety of facial animations from a single speech input, rather than just a single, predetermined animation.
The key innovation is using a Variational Quantized Variational Autoencoder (VQ-VAE) architecture. This allows the model to learn a compressed representation of facial animations, which it can then use to generate new and diverse animations. The VQ-VAE approach helps the model create more realistic and natural-looking facial animations.
Additionally, the model can control the emotional expression of the generated animations. This is done by providing the model with information about the desired emotional state, which it then uses to modify the facial animations accordingly. This makes the animations more expressive and engaging.
Overall, ProbTalk3D represents an advancement in the field of speech-driven 3D facial animation synthesis, allowing for the creation of more realistic and emotion-controlled virtual characters. This could have applications in areas like interactive virtual assistants, animated films, and video games.
Technical Explanation
ProbTalk3D uses a Variational Quantized Variational Autoencoder (VQ-VAE) architecture to generate non-deterministic, emotion-controllable 3D facial animations from speech input. The VQ-VAE model consists of an encoder, a vector quantization module, and a decoder.
The encoder takes the 3D facial animation sequences as input and learns a compressed representation of the data. The vector quantization module then discretizes this representation into a set of learned codebook vectors, which are used to reconstruct the facial animations.
The decoder takes the quantized representation and the conditional emotion inputs, and generates the final 3D facial animation sequences. By using this architecture, the model is able to capture the inherent diversity of facial animations and generate multiple, plausible outputs for a given speech input.
The authors trained and evaluated the ProbTalk3D model on a dataset of 3D facial animation sequences synchronized with speech recordings. The results show that the model is able to generate diverse, emotion-controlled facial animations that are perceptually engaging and realistic.
Critical Analysis
The paper provides a thorough technical explanation of the ProbTalk3D model and its capabilities, but it also acknowledges several limitations and areas for further research.
One key limitation is that the model was trained and evaluated on a relatively small dataset of 3D facial animation sequences. Expanding the dataset size and diversity could help the model better generalize to a wider range of speech inputs and emotional expressions.
Additionally, the paper does not fully address the potential ethical concerns around the use of such technology, such as the potential for misuse or the impact on human-computer interaction. Further research is needed to understand the societal implications of emotion-controlled virtual characters.
Overall, ProbTalk3D represents an interesting and promising approach to speech-driven 3D facial animation synthesis, but more work is needed to address its limitations and potential drawbacks.
Conclusion
ProbTalk3D is a novel deep learning model that can generate non-deterministic, emotion-controllable 3D facial animations from speech input. By using a VQ-VAE architecture, the model is able to capture the inherent diversity of facial animations and generate multiple, plausible outputs for a given speech input.
The ability to control the emotional expression of the generated animations is a key innovation, as it allows for the creation of more engaging and expressive virtual characters. This technology could have a range of applications, from interactive virtual assistants to animated films and video games.
However, the paper also highlights the need for further research to address the model's limitations and potential ethical concerns. Expanding the dataset, improving generalization, and carefully considering the societal implications of such technology will be important next steps in the development of ProbTalk3D and similar systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ProbTalk3D: Non-Deterministic Emotion Controllable Speech-Driven 3D Facial Animation Synthesis Using VQ-VAE
Sichun Wu, Kazi Injamamul Haque, Zerrin Yumak
Audio-driven 3D facial animation synthesis has been an active field of research with attention from both academia and industry. While there are promising results in this area, recent approaches largely focus on lip-sync and identity control, neglecting the role of emotions and emotion control in the generative process. That is mainly due to the lack of emotionally rich facial animation data and algorithms that can synthesize speech animations with emotional expressions at the same time. In addition, majority of the models are deterministic, meaning given the same audio input, they produce the same output motion. We argue that emotions and non-determinism are crucial to generate diverse and emotionally-rich facial animations. In this paper, we propose ProbTalk3D a non-deterministic neural network approach for emotion controllable speech-driven 3D facial animation synthesis using a two-stage VQ-VAE model and an emotionally rich facial animation dataset 3DMEAD. We provide an extensive comparative analysis of our model against the recent 3D facial animation synthesis approaches, by evaluating the results objectively, qualitatively, and with a perceptual user study. We highlight several objective metrics that are more suitable for evaluating stochastic outputs and use both in-the-wild and ground truth data for subjective evaluation. To our knowledge, that is the first non-deterministic 3D facial animation synthesis method incorporating a rich emotion dataset and emotion control with emotion labels and intensity levels. Our evaluation demonstrates that the proposed model achieves superior performance compared to state-of-the-art emotion-controlled, deterministic and non-deterministic models. We recommend watching the supplementary video for quality judgement. The entire codebase is publicly available (https://github.com/uuembodiedsocialai/ProbTalk3D/).
Read more9/14/2024

0
DEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Jisoo Kim, Jungbin Cho, Joonho Park, Soonmin Hwang, Da Eun Kim, Geon Kim, Youngjae Yu
Speech-driven 3D facial animation has garnered lots of attention thanks to its broad range of applications. Despite recent advancements in achieving realistic lip motion, current methods fail to capture the nuanced emotional undertones conveyed through speech and produce monotonous facial motion. These limitations result in blunt and repetitive facial animations, reducing user engagement and hindering their applicability. To address these challenges, we introduce DEEPTalk, a novel approach that generates diverse and emotionally rich 3D facial expressions directly from speech inputs. To achieve this, we first train DEE (Dynamic Emotion Embedding), which employs probabilistic contrastive learning to forge a joint emotion embedding space for both speech and facial motion. This probabilistic framework captures the uncertainty in interpreting emotions from speech and facial motion, enabling the derivation of emotion vectors from its multifaceted space. Moreover, to generate dynamic facial motion, we design TH-VQVAE (Temporally Hierarchical VQ-VAE) as an expressive and robust motion prior overcoming limitations of VAEs and VQ-VAEs. Utilizing these strong priors, we develop DEEPTalk, A talking head generator that non-autoregressively predicts codebook indices to create dynamic facial motion, incorporating a novel emotion consistency loss. Extensive experiments on various datasets demonstrate the effectiveness of our approach in creating diverse, emotionally expressive talking faces that maintain accurate lip-sync. Source code will be made publicly available soon.
Read more8/13/2024

0
EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head
Qianyun He, Xinya Ji, Yicheng Gong, Yuanxun Lu, Zhengyu Diao, Linjia Huang, Yao Yao, Siyu Zhu, Zhan Ma, Songcen Xu, Xiaofei Wu, Zixiao Zhang, Xun Cao, Hao Zhu
We present a novel approach for synthesizing 3D talking heads with controllable emotion, featuring enhanced lip synchronization and rendering quality. Despite significant progress in the field, prior methods still suffer from multi-view consistency and a lack of emotional expressiveness. To address these issues, we collect EmoTalk3D dataset with calibrated multi-view videos, emotional annotations, and per-frame 3D geometry. By training on the EmoTalk3D dataset, we propose a textit{`Speech-to-Geometry-to-Appearance'} mapping framework that first predicts faithful 3D geometry sequence from the audio features, then the appearance of a 3D talking head represented by 4D Gaussians is synthesized from the predicted geometry. The appearance is further disentangled into canonical and dynamic Gaussians, learned from multi-view videos, and fused to render free-view talking head animation. Moreover, our model enables controllable emotion in the generated talking heads and can be rendered in wide-range views. Our method exhibits improved rendering quality and stability in lip motion generation while capturing dynamic facial details such as wrinkles and subtle expressions. Experiments demonstrate the effectiveness of our approach in generating high-fidelity and emotion-controllable 3D talking heads. The code and EmoTalk3D dataset are released at https://nju-3dv.github.io/projects/EmoTalk3D.
Read more8/2/2024
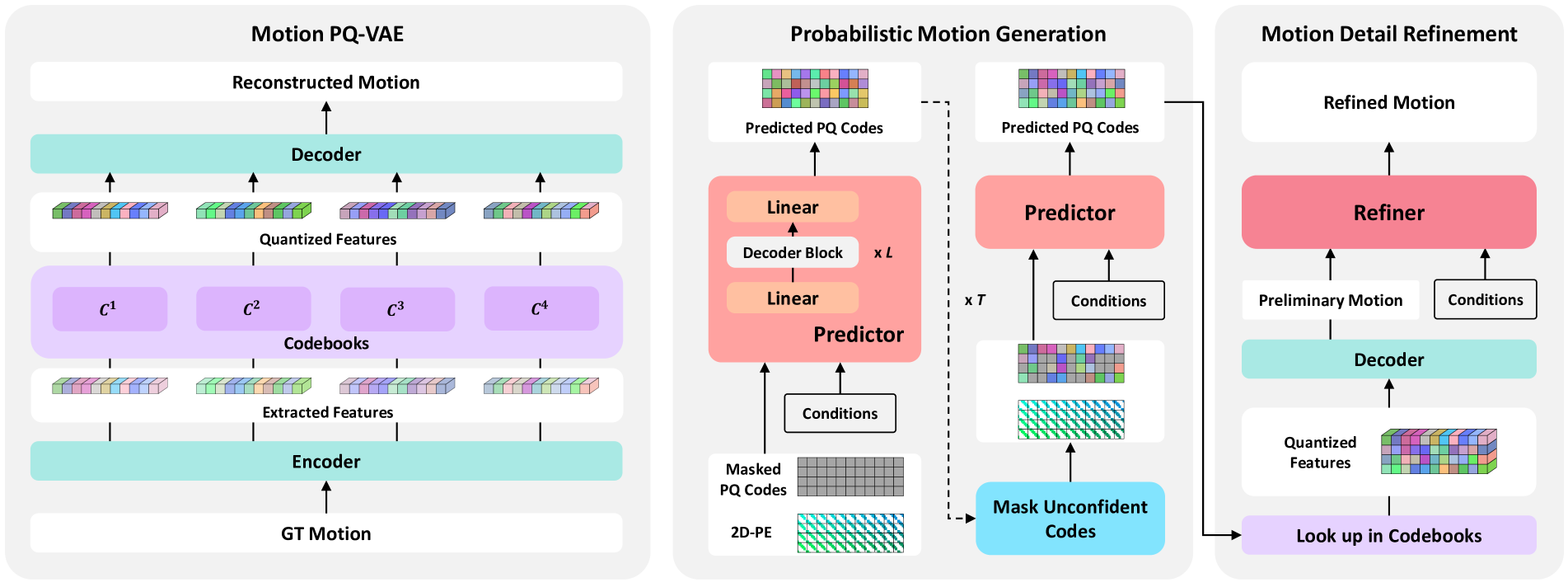
0
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, Changxing Ding
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
Read more4/16/2024