Procedural Fairness in Machine Learning
2404.01877
0
0
Abstract
Fairness in machine learning (ML) has received much attention. However, existing studies have mainly focused on the distributive fairness of ML models. The other dimension of fairness, i.e., procedural fairness, has been neglected. In this paper, we first define the procedural fairness of ML models, and then give formal definitions of individual and group procedural fairness. We propose a novel metric to evaluate the group procedural fairness of ML models, called $GPF_{FAE}$, which utilizes a widely used explainable artificial intelligence technique, namely feature attribution explanation (FAE), to capture the decision process of the ML models. We validate the effectiveness of $GPF_{FAE}$ on a synthetic dataset and eight real-world datasets. Our experiments reveal the relationship between procedural and distributive fairness of the ML model. Based on our analysis, we propose a method for identifying the features that lead to the procedural unfairness of the model and propose two methods to improve procedural fairness after identifying unfair features. Our experimental results demonstrate that we can accurately identify the features that lead to procedural unfairness in the ML model, and both of our proposed methods can significantly improve procedural fairness with a slight impact on model performance, while also improving distributive fairness.
Create account to get full access
Overview
- This paper proposes a novel approach to ensuring procedural fairness in machine learning models.
- The authors introduce a fairness metric and an explainable AI technique to improve the transparency and accountability of model decision-making.
- The research aims to address concerns about the "black box" nature of complex machine learning models and ensure they make decisions in a fair and justifiable manner.
Plain English Explanation
The paper focuses on the idea of "procedural fairness" in machine learning. This means ensuring that the process by which a machine learning model arrives at a decision is fair and transparent, not just that the final outcome is fair.
The authors recognize that as machine learning models become more complex, it can be difficult to understand how they are making decisions. This "black box" problem can lead to concerns about the fairness and accountability of these models, especially when they are used for high-stakes decisions like loan approvals or criminal sentencing.
To address this, the researchers propose a new fairness metric that evaluates not just the outcomes of a model, but the reasoning and justifications behind its decisions. They also develop an explainable AI technique that can provide detailed explanations of how a model is arriving at its predictions.
The key idea is to make machine learning more transparent and accountable, so that we can verify that the decision-making process is fair, even if we don't fully understand the underlying mathematical details of the model. This could help build trust in these powerful AI systems and ensure they are being used in an equitable way.
Technical Explanation
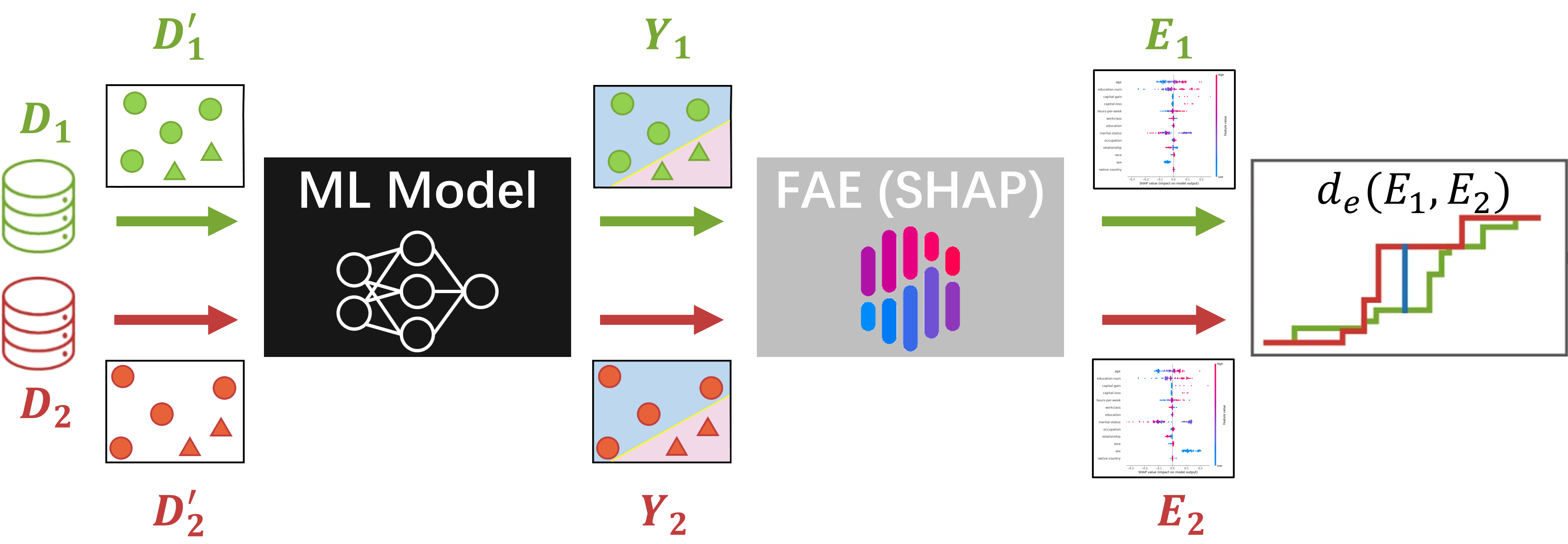
The paper introduces a new fairness metric called "procedural fairness," which evaluates not just the outcomes of a machine learning model, but the reasoning and justifications behind its decisions. This metric assesses things like whether the model is considering all relevant features, whether it is over-relying on certain attributes, and whether it is providing meaningful explanations for its predictions.
To implement this, the authors develop an explainable AI technique called "feature attribution explanation." This allows the model to generate detailed insights into which input features were most influential in driving a particular prediction. By surfacing this information, the model becomes more transparent and the decision-making process more accountable.
The researchers evaluate their approach on several real-world datasets, showing that the procedural fairness metric can identify issues that traditional outcome-focused fairness metrics miss. They also demonstrate that the feature attribution explanations provide useful insights that can help improve model fairness and interpretability.
Critical Analysis
The paper makes a compelling case for the importance of procedural fairness in machine learning, going beyond just optimizing for fair outcomes. The proposed fairness metric and explainable AI techniques seem promising for increasing the transparency and accountability of complex models.
However, the paper does not fully address the challenges of implementing these approaches in practice. Generating meaningful feature attributions can be computationally expensive, and there may be tradeoffs between explanation quality and model performance. The authors also don't discuss how to resolve conflicts when the procedural fairness metric identifies issues that conflict with other business objectives.
Additionally, the evaluation is limited to relatively simple datasets and models. More research would be needed to understand how well these techniques scale to the large, high-stakes machine learning systems commonly deployed in the real world.
Overall, this is an important contribution to the growing field of responsible AI development. The ideas presented here could help build greater trust in machine learning systems and ensure they are making decisions in a fair and justified manner. But further work is needed to address the practical challenges of deploying these methods at scale.
Conclusion
This paper introduces a novel approach to ensuring procedural fairness in machine learning models. By proposing a fairness metric that evaluates the decision-making process, and developing an explainable AI technique to provide detailed feature attributions, the researchers aim to make complex models more transparent and accountable.
This work represents an important step towards building responsible and trustworthy AI systems, especially for high-stakes applications. By focusing on the "how" behind model predictions, rather than just the "what," the authors hope to address concerns about the "black box" nature of machine learning and ensure these powerful technologies are being used in an equitable way.
While challenges remain around practical implementation, this research contributes valuable insights and techniques that could have significant implications for the development of fair and explainable AI in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluating AI Group Fairness: a Fuzzy Logic Perspective
Emmanouil Krasanakis, Symeon Papadopoulos
0
0
Artificial intelligence systems often address fairness concerns by evaluating and mitigating measures of group discrimination, for example that indicate biases against certain genders or races. However, what constitutes group fairness depends on who is asked and the social context, whereas definitions are often relaxed to accept small deviations from the statistical constraints they set out to impose. Here we decouple definitions of group fairness both from the context and from relaxation-related uncertainty by expressing them in the axiomatic system of Basic fuzzy Logic (BL) with loosely understood predicates, like encountering group members. We then evaluate the definitions in subclasses of BL, such as Product or Lukasiewicz logics. Evaluation produces continuous instead of binary truth values by choosing the logic subclass and truth values for predicates that reflect uncertain context-specific beliefs, such as stakeholder opinions gathered through questionnaires. Internally, it follows logic-specific rules to compute the truth values of definitions. We show that commonly held propositions standardize the resulting mathematical formulas and we transcribe logic and truth value choices to layperson terms, so that anyone can answer them. We also use our framework to study several literature definitions of algorithmic fairness, for which we rationalize previous expedient practices that are non-probabilistic and show how to re-interpret their formulas and parameters in new contexts.
6/28/2024
🛸
What Is Fairness? On the Role of Protected Attributes and Fictitious Worlds
Ludwig Bothmann, Kristina Peters, Bernd Bischl
0
0
A growing body of literature in fairness-aware machine learning (fairML) aims to mitigate machine learning (ML)-related unfairness in automated decision-making (ADM) by defining metrics that measure fairness of an ML model and by proposing methods to ensure that trained ML models achieve low scores on these metrics. However, the underlying concept of fairness, i.e., the question of what fairness is, is rarely discussed, leaving a significant gap between centuries of philosophical discussion and the recent adoption of the concept in the ML community. In this work, we try to bridge this gap by formalizing a consistent concept of fairness and by translating the philosophical considerations into a formal framework for the training and evaluation of ML models in ADM systems. We argue that fairness problems can arise even without the presence of protected attributes (PAs), and point out that fairness and predictive performance are not irreconcilable opposites, but that the latter is necessary to achieve the former. Furthermore, we argue why and how causal considerations are necessary when assessing fairness in the presence of PAs by proposing a fictitious, normatively desired (FiND) world in which PAs have no causal effects. In practice, this FiND world must be approximated by a warped world in which the causal effects of the PAs are removed from the real-world data. Finally, we achieve greater linguistic clarity in the discussion of fairML. We outline algorithms for practical applications and present illustrative experiments on COMPAS data.
6/4/2024
❗
Causal Fair Machine Learning via Rank-Preserving Interventional Distributions
Ludwig Bothmann, Susanne Dandl, Michael Schomaker
0
0
A decision can be defined as fair if equal individuals are treated equally and unequals unequally. Adopting this definition, the task of designing machine learning (ML) models that mitigate unfairness in automated decision-making systems must include causal thinking when introducing protected attributes: Following a recent proposal, we define individuals as being normatively equal if they are equal in a fictitious, normatively desired (FiND) world, where the protected attributes have no (direct or indirect) causal effect on the target. We propose rank-preserving interventional distributions to define a specific FiND world in which this holds and a warping method for estimation. Evaluation criteria for both the method and the resulting ML model are presented and validated through simulations. Experiments on empirical data showcase the practical application of our method and compare results with fairadapt (Plev{c}ko and Meinshausen, 2020), a different approach for mitigating unfairness by causally preprocessing data that uses quantile regression forests. With this, we show that our warping approach effectively identifies the most discriminated individuals and mitigates unfairness.
6/26/2024
📊
Procedural Fairness Through Decoupling Objectionable Data Generating Components
Zeyu Tang, Jialu Wang, Yang Liu, Peter Spirtes, Kun Zhang
0
0
We reveal and address the frequently overlooked yet important issue of disguised procedural unfairness, namely, the potentially inadvertent alterations on the behavior of neutral (i.e., not problematic) aspects of data generating process, and/or the lack of procedural assurance of the greatest benefit of the least advantaged individuals. Inspired by John Rawls's advocacy for pure procedural justice, we view automated decision-making as a microcosm of social institutions, and consider how the data generating process itself can satisfy the requirements of procedural fairness. We propose a framework that decouples the objectionable data generating components from the neutral ones by utilizing reference points and the associated value instantiation rule. Our findings highlight the necessity of preventing disguised procedural unfairness, drawing attention not only to the objectionable data generating components that we aim to mitigate, but also more importantly, to the neutral components that we intend to keep unaffected.
5/13/2024