Procedural Fairness Through Decoupling Objectionable Data Generating Components

0
📊
Sign in to get full access
Overview
- The paper discusses the important yet overlooked issue of "disguised procedural unfairness" in automated decision-making systems.
- Disguised procedural unfairness refers to inadvertent alterations in the behavior of neutral (not problematic) aspects of the data generating process, or the lack of procedural assurance of the greatest benefit for the least advantaged individuals.
- The authors view automated decision-making as a microcosm of social institutions and consider how the data generating process itself can satisfy the requirements of procedural fairness, inspired by John Rawls's advocacy for pure procedural justice.
- The proposed framework aims to decouple the objectionable data generating components from the neutral ones by utilizing reference points and the associated value instantiation rule.
Plain English Explanation
The paper focuses on an important but often overlooked problem in automated decision-making systems – the issue of "disguised procedural unfairness." This refers to accidentally changing the behavior of neutral (not problematic) parts of the data generation process, or failing to ensure the greatest benefit for the least advantaged individuals.
The authors see automated decision-making as a small-scale version of larger social institutions. They want to explore how the data generation process itself can be designed to be fair, based on the ideas of philosopher John Rawls and his concept of "pure procedural justice."
To address this, the researchers propose a framework that separates the problematic parts of the data generation from the neutral parts. They use "reference points" and a related "value instantiation rule" to help achieve this separation.
The key takeaway is the need to prevent this hidden unfairness, by focusing not just on the problematic parts we're trying to fix, but also on the neutral parts that we want to keep unchanged.
Technical Explanation
The paper presents a framework to address the challenge of "disguised procedural unfairness" in automated decision-making systems. Disguised procedural unfairness refers to inadvertent changes to the behavior of neutral (non-problematic) aspects of the data generation process, or the lack of procedural assurance of the greatest benefit for the least advantaged individuals.
Building on John Rawls' concept of pure procedural justice, the authors view automated decision-making as a microcosm of social institutions. They explore how the data generation process itself can be designed to satisfy the requirements of procedural fairness.
The proposed framework decouples the objectionable data generating components from the neutral ones by utilizing reference points and an associated value instantiation rule. This allows for the preservation of neutral components while mitigating the problematic ones.
The key insights highlight the necessity of preventing disguised procedural unfairness. This draws attention not only to the objectionable data generating components, but also to the neutral components that should remain unaffected.
Critical Analysis
The paper makes a valuable contribution by highlighting the issue of "disguised procedural unfairness," which is often overlooked in discussions of fairness in machine learning. The proposed framework offers a promising approach to address this challenge by decoupling problematic and neutral components of the data generation process.
However, the paper does not provide detailed implementation guidance or empirical validation of the framework. Additional research would be needed to assess the practical feasibility and effectiveness of the proposed approach.
Another potential limitation is the reliance on the concept of "neutral" components, which may be difficult to define or identify in complex, real-world data generation processes. Further research could explore more nuanced approaches to handling different types of components and their interdependencies.
Overall, the paper offers a thoughtful perspective on an important but under-explored aspect of fairness in machine learning. Encouraging critical engagement with these issues is valuable for advancing the field and ensuring the responsible development of automated decision-making systems.
Conclusion
This paper brings attention to the crucial but often overlooked issue of "disguised procedural unfairness" in automated decision-making systems. By viewing these systems as a microcosm of social institutions, the authors propose a framework to decouple problematic and neutral components of the data generation process, inspired by John Rawls' concept of pure procedural justice.
The key insights highlight the need to prevent this hidden unfairness, focusing not just on the objectionable data generating components, but also on the neutral components that should remain unaffected. This underscores the importance of holistic approaches to achieving fairness in machine learning, going beyond simply mitigating known sources of bias.
While further research is needed to refine and validate the proposed framework, this paper represents an important step in addressing a critical but often overlooked aspect of fairness in automated decision-making. Continued exploration of these issues can help ensure the responsible development and deployment of these systems in ways that uphold the principles of procedural fairness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Procedural Fairness Through Decoupling Objectionable Data Generating Components
Zeyu Tang, Jialu Wang, Yang Liu, Peter Spirtes, Kun Zhang
We reveal and address the frequently overlooked yet important issue of disguised procedural unfairness, namely, the potentially inadvertent alterations on the behavior of neutral (i.e., not problematic) aspects of data generating process, and/or the lack of procedural assurance of the greatest benefit of the least advantaged individuals. Inspired by John Rawls's advocacy for pure procedural justice, we view automated decision-making as a microcosm of social institutions, and consider how the data generating process itself can satisfy the requirements of procedural fairness. We propose a framework that decouples the objectionable data generating components from the neutral ones by utilizing reference points and the associated value instantiation rule. Our findings highlight the necessity of preventing disguised procedural unfairness, drawing attention not only to the objectionable data generating components that we aim to mitigate, but also more importantly, to the neutral components that we intend to keep unaffected.
Read more5/13/2024
0
Procedural Fairness in Machine Learning
Ziming Wang, Changwu Huang, Xin Yao
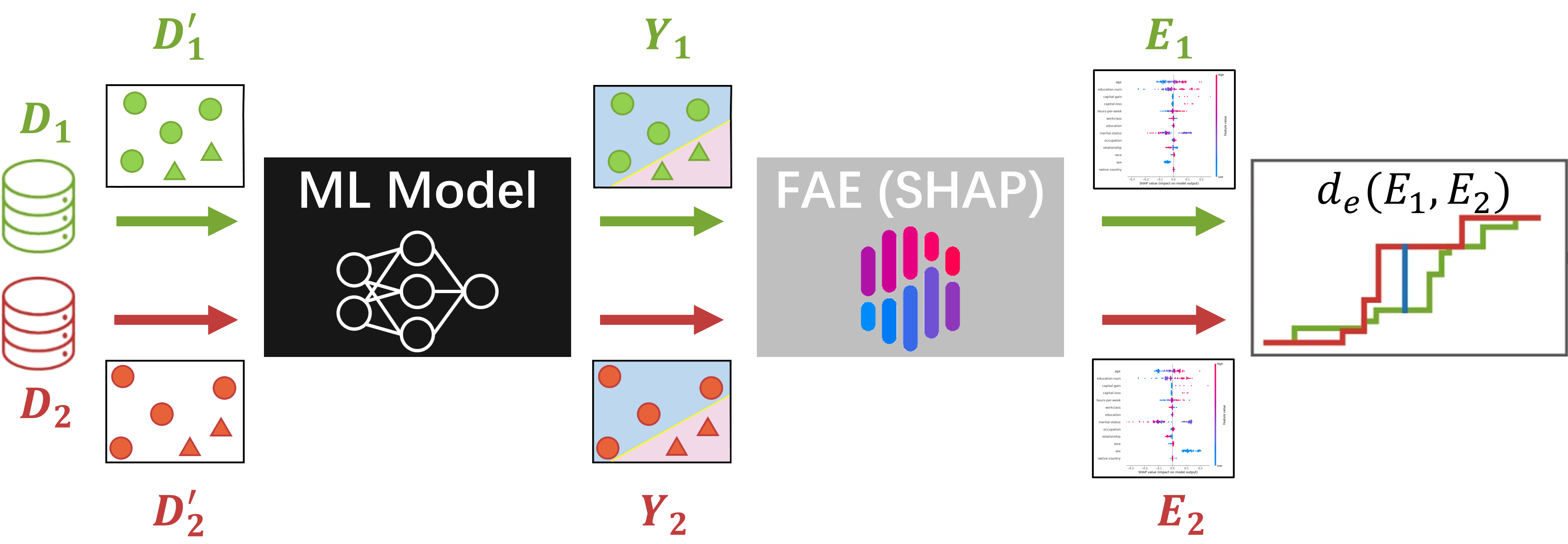
Fairness in machine learning (ML) has received much attention. However, existing studies have mainly focused on the distributive fairness of ML models. The other dimension of fairness, i.e., procedural fairness, has been neglected. In this paper, we first define the procedural fairness of ML models, and then give formal definitions of individual and group procedural fairness. We propose a novel metric to evaluate the group procedural fairness of ML models, called $GPF_{FAE}$, which utilizes a widely used explainable artificial intelligence technique, namely feature attribution explanation (FAE), to capture the decision process of the ML models. We validate the effectiveness of $GPF_{FAE}$ on a synthetic dataset and eight real-world datasets. Our experiments reveal the relationship between procedural and distributive fairness of the ML model. Based on our analysis, we propose a method for identifying the features that lead to the procedural unfairness of the model and propose two methods to improve procedural fairness after identifying unfair features. Our experimental results demonstrate that we can accurately identify the features that lead to procedural unfairness in the ML model, and both of our proposed methods can significantly improve procedural fairness with a slight impact on model performance, while also improving distributive fairness.
Read more4/3/2024

0
Fairness Issues and Mitigations in (Differentially Private) Socio-demographic Data Processes
Joonhyuk Ko, Juba Ziani, Saswat Das, Matt Williams, Ferdinando Fioretto
Statistical agencies rely on sampling techniques to collect socio-demographic data crucial for policy-making and resource allocation. This paper shows that surveys of important societal relevance introduce sampling errors that unevenly impact group-level estimates, thereby compromising fairness in downstream decisions. To address these issues, this paper introduces an optimization approach modeled on real-world survey design processes, ensuring sampling costs are optimized while maintaining error margins within prescribed tolerances. Additionally, privacy-preserving methods used to determine sampling rates can further impact these fairness issues. The paper explores the impact of differential privacy on the statistics informing the sampling process, revealing a surprising effect: not only the expected negative effect from the addition of noise for differential privacy is negligible, but also this privacy noise can in fact reduce unfairness as it positively biases smaller counts. These findings are validated over an extensive analysis using datasets commonly applied in census statistics.
Read more8/19/2024
❗
0
Fair Enough? A map of the current limitations of the requirements to have fair algorithms
Daniele Regoli, Alessandro Castelnovo, Nicole Inverardi, Gabriele Nanino, Ilaria Penco
In recent years, the increase in the usage and efficiency of Artificial Intelligence and, more in general, of Automated Decision-Making systems has brought with it an increasing and welcome awareness of the risks associated with such systems. One of such risks is that of perpetuating or even amplifying bias and unjust disparities present in the data from which many of these systems learn to adjust and optimise their decisions. This awareness has on the one hand encouraged several scientific communities to come up with more and more appropriate ways and methods to assess, quantify, and possibly mitigate such biases and disparities. On the other hand, it has prompted more and more layers of society, including policy makers, to call for fair algorithms. We believe that while many excellent and multidisciplinary research is currently being conducted, what is still fundamentally missing is the awareness that having fair algorithms is per se a nearly meaningless requirement that needs to be complemented with many additional social choices to become actionable. Namely, there is a hiatus between what the society is demanding from Automated Decision-Making systems, and what this demand actually means in real-world scenarios. In this work, we outline the key features of such a hiatus and pinpoint a set of crucial open points that we as a society must address in order to give a concrete meaning to the increasing demand of fairness in Automated Decision-Making systems.
Read more9/24/2024