ProcessTBench: An LLM Plan Generation Dataset for Process Mining

0
Sign in to get full access
Overview
- Introduces a new dataset called ProcessTBench for evaluating language models on process mining tasks
- Focuses on an LLM's ability to generate plans for process mining activities
- Provides a benchmark to assess the capabilities of large language models in the context of process mining
Plain English Explanation
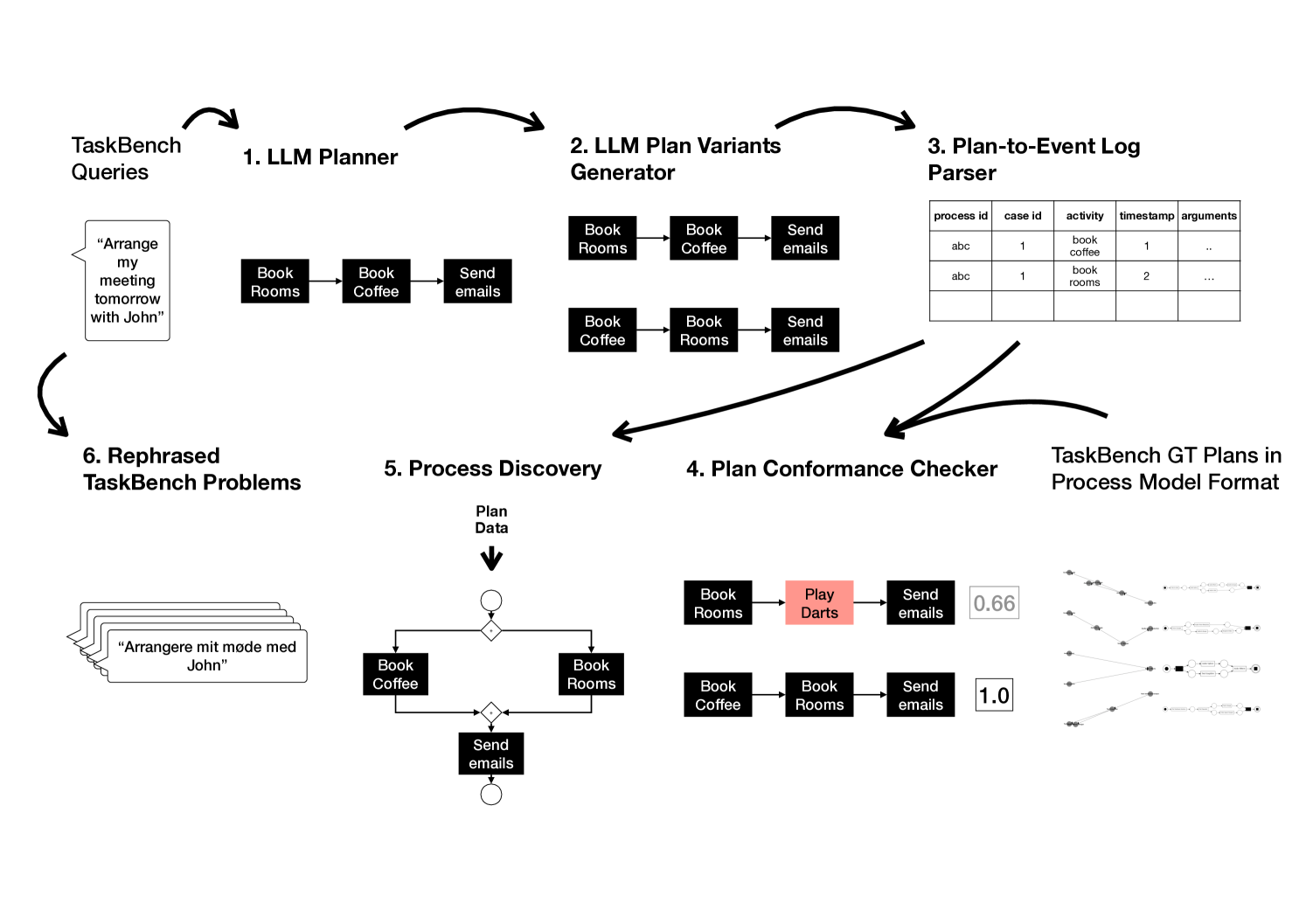
The paper introduces a new dataset called ProcessTBench that is designed to evaluate the performance of large language models (LLMs) on process mining tasks. Process mining is the analysis of event logs to discover, monitor, and improve business processes.
The key idea behind ProcessTBench is to assess an LLM's ability to generate plans for process mining activities. The dataset contains a variety of prompts that describe process mining scenarios, and the LLM is asked to generate a step-by-step plan for addressing the given task. This allows researchers to better understand the strengths and limitations of LLMs in the context of process mining, which is an important area of business analytics.
By providing a standardized benchmark, ProcessTBench aims to spur further research and development in the application of LLMs to process mining problems. This could lead to more effective and efficient process mining tools, which could in turn help organizations optimize their business operations.
Technical Explanation
The paper describes the process of generating the ProcessTBench dataset. The authors first collected a set of process mining scenarios from various sources, including academic papers, industry case studies, and online forums. These scenarios cover a wide range of process mining tasks, such as discovering process models, detecting anomalies, and enhancing process performance.
For each scenario, the authors then generated a prompt that describes the task and the relevant context. The LLM is then asked to generate a plan for addressing the task, which is evaluated by human annotators. The dataset includes a variety of metrics, such as the coherence, feasibility, and completeness of the generated plans, as well as the overall quality of the response.
The authors also provide baseline results using several state-of-the-art LLMs, including GPT-3 and T5. These results demonstrate that while LLMs can generate relevant plans for process mining tasks, there is still room for improvement in terms of the quality and consistency of the responses.
Critical Analysis
The ProcessTBench dataset represents an important step towards benchmarking the capabilities of LLMs in the context of process mining. By focusing on the ability to generate plans, the dataset addresses a crucial aspect of process mining that goes beyond simple task completion or question answering.
However, the paper does acknowledge some limitations of the dataset. For example, the scenarios may not fully capture the complexity and nuance of real-world process mining challenges, and the evaluation metrics may not fully capture the broader impact of the generated plans on business outcomes.
Additionally, the paper does not address the potential biases or limitations of the LLMs used in the baseline experiments. It would be valuable to understand how the performance of these models might be affected by factors such as the training data, model architecture, or fine-tuning approaches.
Overall, the ProcessTBench dataset represents a valuable contribution to the field of process mining and the application of LLMs to real-world business problems. By providing a standardized benchmark, the dataset can help drive further research and development in this important area.
Conclusion
The ProcessTBench dataset introduces a new benchmark for evaluating the capabilities of large language models in the context of process mining. By focusing on the ability to generate plans for process mining tasks, the dataset provides a more nuanced and holistic assessment of LLM performance compared to traditional question-answering or task completion benchmarks.
The results presented in the paper suggest that while LLMs can generate relevant plans for process mining tasks, there is still room for improvement in terms of the quality and consistency of the responses. This highlights the need for continued research and development in the application of LLMs to real-world business problems, such as those encountered in the field of process mining.
Overall, the ProcessTBench dataset represents an important contribution to the field of process mining and the broader challenge of leveraging large language models for complex, task-oriented applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ProcessTBench: An LLM Plan Generation Dataset for Process Mining
Andrei Cosmin Redis, Mohammadreza Fani Sani, Bahram Zarrin, Andrea Burattin
Large Language Models (LLMs) have shown significant promise in plan generation. Yet, existing datasets often lack the complexity needed for advanced tool use scenarios - such as handling paraphrased query statements, supporting multiple languages, and managing actions that can be done in parallel. These scenarios are crucial for evaluating the evolving capabilities of LLMs in real-world applications. Moreover, current datasets don't enable the study of LLMs from a process perspective, particularly in scenarios where understanding typical behaviors and challenges in executing the same process under different conditions or formulations is crucial. To address these gaps, we present the ProcessTBench synthetic dataset, an extension of the TaskBench dataset specifically designed to evaluate LLMs within a process mining framework.
Read more9/20/2024
💬
0
PM-LLM-Benchmark: Evaluating Large Language Models on Process Mining Tasks
Alessandro Berti, Humam Kourani, Wil M. P. van der Aalst
Large Language Models (LLMs) have the potential to semi-automate some process mining (PM) analyses. While commercial models are already adequate for many analytics tasks, the competitive level of open-source LLMs in PM tasks is unknown. In this paper, we propose PM-LLM-Benchmark, the first comprehensive benchmark for PM focusing on domain knowledge (process-mining-specific and process-specific) and on different implementation strategies. We focus also on the challenges in creating such a benchmark, related to the public availability of the data and on evaluation biases by the LLMs. Overall, we observe that most of the considered LLMs can perform some process mining tasks at a satisfactory level, but tiny models that would run on edge devices are still inadequate. We also conclude that while the proposed benchmark is useful for identifying LLMs that are adequate for process mining tasks, further research is needed to overcome the evaluation biases and perform a more thorough ranking of the competitive LLMs.
Read more7/19/2024

0
Evaluating Large Language Models in Process Mining: Capabilities, Benchmarks, and Evaluation Strategies
Alessandro Berti, Humam Kourani, Hannes Hafke, Chiao-Yun Li, Daniel Schuster
Using Large Language Models (LLMs) for Process Mining (PM) tasks is becoming increasingly essential, and initial approaches yield promising results. However, little attention has been given to developing strategies for evaluating and benchmarking the utility of incorporating LLMs into PM tasks. This paper reviews the current implementations of LLMs in PM and reflects on three different questions. 1) What is the minimal set of capabilities required for PM on LLMs? 2) Which benchmark strategies help choose optimal LLMs for PM? 3) How do we evaluate the output of LLMs on specific PM tasks? The answer to these questions is fundamental to the development of comprehensive process mining benchmarks on LLMs covering different tasks and implementation paradigms.
Read more4/3/2024

0
Re-Thinking Process Mining in the AI-Based Agents Era
Alessandro Berti, Mayssa Maatallah, Urszula Jessen, Michal Sroka, Sonia Ayachi Ghannouchi
Large Language Models (LLMs) have emerged as powerful conversational interfaces, and their application in process mining (PM) tasks has shown promising results. However, state-of-the-art LLMs struggle with complex scenarios that demand advanced reasoning capabilities. In the literature, two primary approaches have been proposed for implementing PM using LLMs: providing textual insights based on a textual abstraction of the process mining artifact, and generating code executable on the original artifact. This paper proposes utilizing the AI-Based Agents Workflow (AgWf) paradigm to enhance the effectiveness of PM on LLMs. This approach allows for: i) the decomposition of complex tasks into simpler workflows, and ii) the integration of deterministic tools with the domain knowledge of LLMs. We examine various implementations of AgWf and the types of AI-based tasks involved. Additionally, we discuss the CrewAI implementation framework and present examples related to process mining.
Read more8/16/2024