Progressive Multi-modal Conditional Prompt Tuning

0
Sign in to get full access
Overview
- Proposes a new approach called Progressive Multi-modal Conditional Prompt Tuning (PMCPT) for fine-tuning pre-trained vision-language models
- Aims to improve few-shot learning performance on image classification tasks
- Uses a progressive multi-modal prompt tuning strategy that learns to generate optimized prompts for different modalities
Plain English Explanation
Multi-modal Prompt Tuning
The paper introduces a new technique called Progressive Multi-modal Conditional Prompt Tuning (PMCPT) to fine-tune pre-trained vision-language models for image classification tasks. The key idea is to learn prompts that can effectively guide the model to extract relevant information from different modalities (e.g. text and images) to improve its few-shot learning performance.
Traditional fine-tuning approaches often require a large amount of labeled data, which can be costly and time-consuming to obtain. PMCPT aims to address this by leveraging the inherent multi-modal understanding of pre-trained models and learning prompts that can capture salient features from both text and image inputs, even with limited training data.
Progressive Prompt Tuning
The "progressive" aspect of PMCPT refers to the way the prompts are learned. Instead of directly optimizing the full prompt, the model learns the prompts in a step-by-step fashion, starting from a simple initial prompt and gradually making it more complex and informative. This progressive approach helps the model converge to better prompts more efficiently, leading to improved few-shot learning performance.
Conditional Prompts
The "conditional" aspect of PMCPT means that the prompts are generated based on the specific input images, rather than using a fixed prompt for all examples. By conditioning the prompts on the input, the model can tailor the prompt to best suit the characteristics of each image, potentially leading to better feature extraction and classification results.
Overall, the PMCPT approach aims to leverage the power of pre-trained vision-language models and prompt-based learning to achieve strong few-shot learning performance on image classification tasks, without requiring large amounts of labeled data.
Technical Explanation
Architecture
The PMCPT model consists of several key components:
- Feature Extractor: A pre-trained vision-language model, such as CLIP, that serves as the backbone for extracting visual and textual features.
- Prompt Generator: A neural network module that generates the conditional prompts based on the input image.
- Prompt Encoder: An encoder that maps the generated prompts into a format compatible with the feature extractor.
- Classifier: A simple linear layer that takes the extracted features and produces the final classification output.
The model is trained in a progressive manner, where the prompt generator starts with a simple initial prompt and gradually increases its complexity over the training iterations. This allows the model to converge to more informative prompts more efficiently.
Training and Evaluation
The authors evaluate the PMCPT approach on several few-shot image classification benchmarks, including miniImageNet, tieredImageNet, and CIFAR-FS. They compare the performance of PMCPT against various baselines, including standard fine-tuning and other prompt-based approaches.
The experiments show that PMCPT consistently outperforms the baselines, demonstrating the effectiveness of the progressive multi-modal conditional prompt tuning strategy for improving few-shot learning performance.
Critical Analysis
The PMCPT approach represents an interesting and promising direction for leveraging pre-trained vision-language models in few-shot learning scenarios. The use of conditional prompts and the progressive prompt tuning strategy are well-designed components that contribute to the model's strong performance.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the PMCPT approach. For example, it would be useful to understand the computational and memory requirements of the model, as the prompt generator and encoder add additional complexity to the system.
Additionally, the paper could have explored the interpretability of the learned prompts and how they contribute to the model's decision-making process. Understanding the underlying mechanisms and the types of features the prompts are capturing could lead to further insights and improvements.
Furthermore, the authors could have considered evaluating the PMCPT approach on a wider range of datasets and tasks, such as fine-grained image classification or multi-label classification, to better assess the generalizability of the method.
Conclusion
The PMCPT approach presented in this paper represents a significant advancement in the field of few-shot learning for image classification. By combining the power of pre-trained vision-language models with a progressive multi-modal prompt tuning strategy, the authors have demonstrated the potential to achieve strong performance on few-shot tasks without the need for large amounts of labeled data.
The key insights and techniques introduced in this work could inspire further research and development in the area of prompt-based learning, potentially leading to even more efficient and effective solutions for various computer vision and multi-modal learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Progressive Multi-modal Conditional Prompt Tuning
Xiaoyu Qiu, Hao Feng, Yuechen Wang, Wengang Zhou, Houqiang Li
Pre-trained vision-language models (VLMs) have shown remarkable generalization capabilities via prompting, which leverages VLMs as knowledge bases to extract information beneficial for downstream tasks. However, existing methods primarily employ uni-modal prompting, which only engages a uni-modal branch, failing to simultaneously adjust vision-language (V-L) features. Additionally, the one-pass forward pipeline in VLM encoding struggles to align V-L features that have a huge gap. Confronting these challenges, we propose a novel method, Progressive Multi-modal conditional Prompt Tuning (ProMPT). ProMPT exploits a recurrent structure, optimizing and aligning V-L features by iteratively utilizing image and current encoding information. It comprises an initialization and a multi-modal iterative evolution (MIE) module. Initialization is responsible for encoding image and text using a VLM, followed by a feature filter that selects text features similar to image. MIE then facilitates multi-modal prompting through class-conditional vision prompting, instance-conditional text prompting, and feature filtering. In each MIE iteration, vision prompts are obtained from the filtered text features via a vision generator, promoting image features to focus more on target object during vision prompting. The encoded image features are fed into a text generator to produce text prompts that are more robust to class shift. Thus, V-L features are progressively aligned, enabling advance from coarse to exact classifications. Extensive experiments are conducted in three settings to evaluate the efficacy of ProMPT. The results indicate that ProMPT outperforms existing methods on average across all settings, demonstrating its superior generalization.
Read more4/19/2024
0
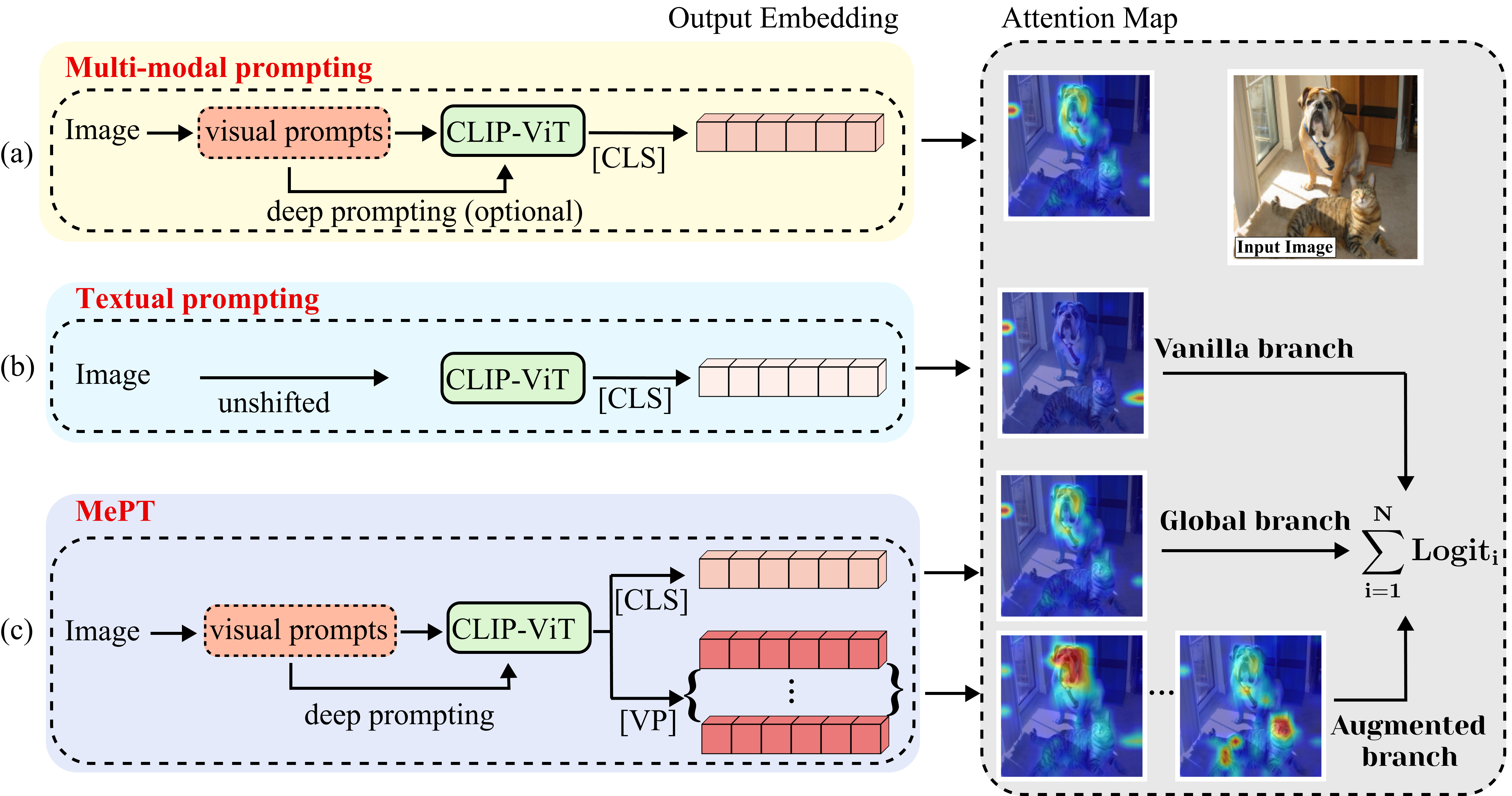
MePT: Multi-Representation Guided Prompt Tuning for Vision-Language Model
Xinyang Wang, Yi Yang, Minfeng Zhu, Kecheng Zheng, Shi Liu, Wei Chen
Recent advancements in pre-trained Vision-Language Models (VLMs) have highlighted the significant potential of prompt tuning for adapting these models to a wide range of downstream tasks. However, existing prompt tuning methods typically map an image to a single representation, limiting the model's ability to capture the diverse ways an image can be described. To address this limitation, we investigate the impact of visual prompts on the model's generalization capability and introduce a novel method termed Multi-Representation Guided Prompt Tuning (MePT). Specifically, MePT employs a three-branch framework that focuses on diverse salient regions, uncovering the inherent knowledge within images which is crucial for robust generalization. Further, we employ efficient self-ensemble techniques to integrate these versatile image representations, allowing MePT to learn all conditional, marginal, and fine-grained distributions effectively. We validate the effectiveness of MePT through extensive experiments, demonstrating significant improvements on both base-to-novel class prediction and domain generalization tasks.
Read more8/20/2024
🌿
0
Adversarial Prompt Tuning for Vision-Language Models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, Jitao Sang
With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities. However, these models remain vulnerable to adversarial attacks, particularly in the image modality, presenting considerable security risks. This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs. AdvPT innovatively leverages learnable text prompts and aligns them with adversarial image embeddings, to address the vulnerabilities inherent in VLMs without the need for extensive parameter training or modification of the model architecture. We demonstrate that AdvPT improves resistance against white-box and black-box adversarial attacks and exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting defensive capabilities. Comprehensive experimental analyses provide insights into adversarial prompt tuning, a novel paradigm devoted to improving resistance to adversarial images through textual input modifications, paving the way for future robust multimodal learning research. These findings open up new possibilities for enhancing the security of VLMs. Our code is available at https://github.com/jiamingzhang94/Adversarial-Prompt-Tuning.
Read more8/20/2024
📉
0
Can Better Text Semantics in Prompt Tuning Improve VLM Generalization?
Hari Chandana Kuchibhotla, Sai Srinivas Kancheti, Abbavaram Gowtham Reddy, Vineeth N Balasubramanian
Going beyond mere fine-tuning of vision-language models (VLMs), learnable prompt tuning has emerged as a promising, resource-efficient alternative. Despite their potential, effectively learning prompts faces the following challenges: (i) training in a low-shot scenario results in overfitting, limiting adaptability, and yielding weaker performance on newer classes or datasets; (ii) prompt-tuning's efficacy heavily relies on the label space, with decreased performance in large class spaces, signaling potential gaps in bridging image and class concepts. In this work, we investigate whether better text semantics can help address these concerns. In particular, we introduce a prompt-tuning method that leverages class descriptions obtained from Large Language Models (LLMs). These class descriptions are used to bridge image and text modalities. Our approach constructs part-level description-guided image and text features, which are subsequently aligned to learn more generalizable prompts. Our comprehensive experiments conducted across 11 benchmark datasets show that our method outperforms established methods, demonstrating substantial improvements.
Read more6/21/2024