Adversarial Prompt Tuning for Vision-Language Models

0
🌿
Sign in to get full access
Overview
- The rapid advancement of multimodal learning has led to the development of powerful Vision-Language Models (VLMs) like CLIP.
- These models can effectively bridge the gap between visual and language modalities.
- However, VLMs remain vulnerable to adversarial attacks, particularly in the image modality, posing security risks.
- This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs.
Plain English Explanation
The paper discusses a new way to make vision-language models more secure against adversarial attacks. Vision-language models are AI systems that can understand both images and text, bridging the gap between these two types of information.
While these models are powerful, they can be tricked by small, imperceptible changes to images (called "adversarial attacks"). This can be a security issue, as it means the models could be fooled into making mistakes.
The researchers introduce a technique called "Adversarial Prompt Tuning" (AdvPT) to address this problem. AdvPT uses learnable text prompts to align the model's understanding of images with adversarial examples. This helps make the model more resistant to these types of attacks without needing to significantly change the model itself.
The key idea is to modify the text input to the model in a way that counteracts the effect of the adversarial image. This is a novel approach that doesn't require extensive retraining of the model, making it an efficient way to improve security.
Technical Explanation
The paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in Vision-Language Models (VLMs).
AdvPT leverages learnable text prompts and aligns them with adversarial image embeddings to address the vulnerabilities inherent in VLMs. This approach does not require extensive parameter training or modification of the model architecture.
The key elements of AdvPT are:
- Adversarial Image Embeddings: The model generates adversarial image embeddings using gradient-based optimization techniques.
- Learnable Text Prompts: The model learns text prompts that can be combined with the adversarial image embeddings to produce robust representations.
- Prompt Alignment: The text prompts are aligned with the adversarial image embeddings to counteract the effects of the adversarial perturbations.
The researchers demonstrate that AdvPT improves resistance against both white-box and black-box adversarial attacks. Furthermore, AdvPT exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting the defensive capabilities.
Comprehensive experimental analyses provide insights into the adversarial prompt tuning paradigm, paving the way for future robust multimodal learning research.
Critical Analysis
The paper presents a novel and promising approach to improving the adversarial robustness of Vision-Language Models (VLMs). The key strength of AdvPT is that it can enhance security without requiring significant changes to the model architecture or extensive retraining.
However, the paper does not explore the limitations of AdvPT in depth. It would be valuable to understand the extent to which AdvPT can be applied to different VLM architectures and to investigate any potential trade-offs, such as the impact on model performance or computational efficiency.
Additionally, the paper focuses on improving robustness to image-based adversarial attacks, but it does not address potential vulnerabilities in the text modality. Future research could explore extending AdvPT to enhance the overall security of VLMs, including both visual and textual inputs.
Conclusion
This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to improve the adversarial robustness of Vision-Language Models (VLMs). AdvPT leverages learnable text prompts to align with adversarial image embeddings, enhancing the model's resistance to adversarial attacks without the need for extensive model modifications.
The findings of this research open up new possibilities for improving the security of VLMs, which are increasingly important as these models become more widespread in various applications. The adversarial prompt tuning approach introduced in this paper lays the groundwork for future advancements in robust multimodal learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
Adversarial Prompt Tuning for Vision-Language Models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, Jitao Sang
With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities. However, these models remain vulnerable to adversarial attacks, particularly in the image modality, presenting considerable security risks. This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs. AdvPT innovatively leverages learnable text prompts and aligns them with adversarial image embeddings, to address the vulnerabilities inherent in VLMs without the need for extensive parameter training or modification of the model architecture. We demonstrate that AdvPT improves resistance against white-box and black-box adversarial attacks and exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting defensive capabilities. Comprehensive experimental analyses provide insights into adversarial prompt tuning, a novel paradigm devoted to improving resistance to adversarial images through textual input modifications, paving the way for future robust multimodal learning research. These findings open up new possibilities for enhancing the security of VLMs. Our code is available at https://github.com/jiamingzhang94/Adversarial-Prompt-Tuning.
Read more8/20/2024

0
Revisiting the Robust Generalization of Adversarial Prompt Tuning
Fan Yang, Mingxuan Xia, Sangzhou Xia, Chicheng Ma, Hui Hui
Understanding the vulnerability of large-scale pre-trained vision-language models like CLIP against adversarial attacks is key to ensuring zero-shot generalization capacity on various downstream tasks. State-of-the-art defense mechanisms generally adopt prompt learning strategies for adversarial fine-tuning to improve the adversarial robustness of the pre-trained model while keeping the efficiency of adapting to downstream tasks. Such a setup leads to the problem of over-fitting which impedes further improvement of the model's generalization capacity on both clean and adversarial examples. In this work, we propose an adaptive Consistency-guided Adversarial Prompt Tuning (i.e., CAPT) framework that utilizes multi-modal prompt learning to enhance the alignment of image and text features for adversarial examples and leverage the strong generalization of pre-trained CLIP to guide the model-enhancing its robust generalization on adversarial examples while maintaining its accuracy on clean ones. We also design a novel adaptive consistency objective function to balance the consistency of adversarial inputs and clean inputs between the fine-tuning model and the pre-trained model. We conduct extensive experiments across 14 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show the superiority of CAPT over other state-of-the-art adaption methods. CAPT demonstrated excellent performance in terms of the in-distribution performance and the generalization under input distribution shift and across datasets.
Read more5/21/2024
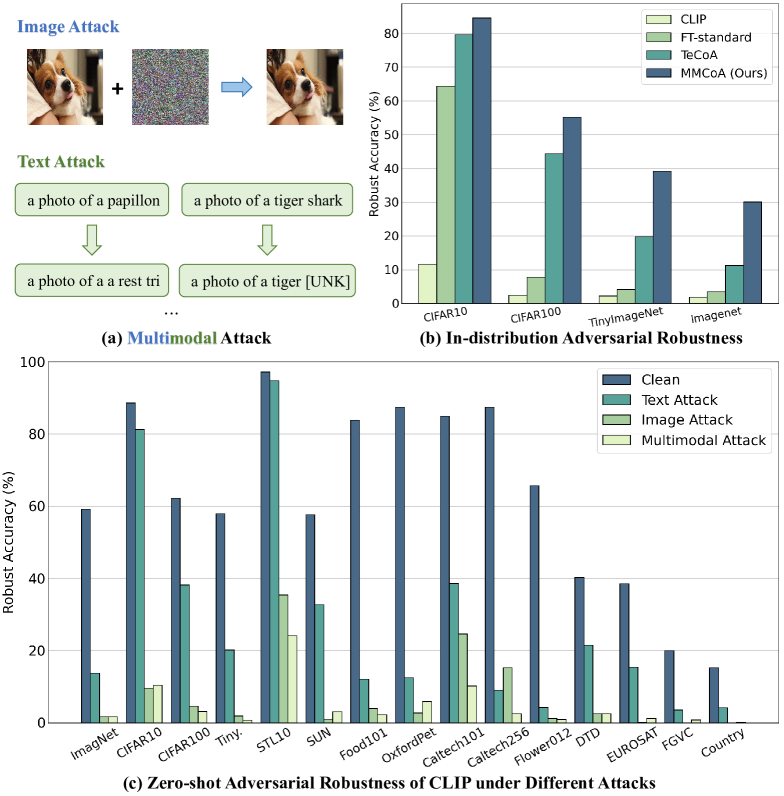
0
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
Read more7/18/2024

0
Towards Adversarially Robust Vision-Language Models: Insights from Design Choices and Prompt Formatting Techniques
Rishika Bhagwatkar, Shravan Nayak, Reza Bayat, Alexis Roger, Daniel Z Kaplan, Pouya Bashivan, Irina Rish
Vision-Language Models (VLMs) have witnessed a surge in both research and real-world applications. However, as they are becoming increasingly prevalent, ensuring their robustness against adversarial attacks is paramount. This work systematically investigates the impact of model design choices on the adversarial robustness of VLMs against image-based attacks. Additionally, we introduce novel, cost-effective approaches to enhance robustness through prompt formatting. By rephrasing questions and suggesting potential adversarial perturbations, we demonstrate substantial improvements in model robustness against strong image-based attacks such as Auto-PGD. Our findings provide important guidelines for developing more robust VLMs, particularly for deployment in safety-critical environments.
Read more7/17/2024