A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
2406.16085
0
0

Abstract
Zero-shot classification capabilities naturally arise in models trained within a vision-language contrastive framework. Despite their classification prowess, these models struggle in dense tasks like zero-shot open-vocabulary segmentation. This deficiency is often attributed to the absence of localization cues in captions and the intertwined nature of the learning process, which encompasses both image representation learning and cross-modality alignment. To tackle these issues, we propose SimZSS, a Simple framework for open-vocabulary Zero-Shot Segmentation. The method is founded on two key principles: i) leveraging frozen vision-only models that exhibit spatial awareness while exclusively aligning the text encoder and ii) exploiting the discrete nature of text and linguistic knowledge to pinpoint local concepts within captions. By capitalizing on the quality of the visual representations, our method requires only image-caption pairs datasets and adapts to both small curated and large-scale noisy datasets. When trained on COCO Captions across 8 GPUs, SimZSS achieves state-of-the-art results on 7 out of 8 benchmark datasets in less than 15 minutes.
Create account to get full access
Overview
- This paper proposes a simple framework for open-vocabulary zero-shot segmentation, which allows segmentation of objects without requiring any labeled training data for those objects.
- The approach uses Cascade-CLIP to align visual and textual representations, enabling the model to segment objects based on natural language descriptions.
- The paper also introduces a new dataset, LVIS-Textual, for benchmarking zero-shot segmentation.
Plain English Explanation
The paper describes a new way to perform object segmentation, which is the process of identifying and outlining specific objects in an image. Typical segmentation models require a lot of labeled training data - for example, many images of cars, with the car regions manually marked. This paper presents a simpler approach that doesn't need any labeled training data for the objects you want to segment.
Instead, the model is trained to understand the relationship between visual information (the images) and textual information (descriptions of objects). Once trained, you can simply provide a text description of an object, and the model will be able to find and outline that object in a new image, even if it's never seen that specific object before.
This "zero-shot" capability is enabled by using a technique called Cascade-CLIP, which aligns the visual and textual representations in a smart way. The paper also introduces a new dataset called LVIS-Textual that can be used to evaluate this kind of zero-shot segmentation approach.
Technical Explanation
The paper proposes a simple framework for open-vocabulary zero-shot segmentation. The core idea is to leverage Cascade-CLIP, a method for aligning visual and textual representations, to enable segmentation of objects without requiring any labeled training data for those objects.
The framework consists of three main components:
- A Cascade-CLIP model, which is used to obtain aligned visual and textual embeddings.
- A segmentation head, which takes the visual embeddings and predicts a segmentation mask.
- A text-to-segment module, which uses the textual embeddings to select relevant object classes and their corresponding segmentation masks.
During inference, the user provides a natural language description of the object they want to segment. The text-to-segment module maps this description to the relevant object classes, and the segmentation head then generates a segmentation mask for that object.
The paper also introduces a new dataset called LVIS-Textual, which extends the existing LVIS dataset with textual descriptions for each object category. This dataset can be used to benchmark zero-shot segmentation approaches.
Critical Analysis
The paper presents a promising approach for open-vocabulary zero-shot segmentation, which could have significant practical applications in areas like robotics, image editing, and autonomous driving. However, the authors acknowledge some limitations:
- The performance of the zero-shot segmentation is still lower than that of traditional supervised segmentation models, especially for rare or complex objects.
- The LVIS-Textual dataset, while a valuable contribution, may not fully capture the diversity of real-world object descriptions.
- The paper does not explore the potential for retrieval-enhanced zero-shot video captioning or paying attention to your neighbours in the zero-shot segmentation context.
Further research could investigate ways to improve the zero-shot segmentation performance, expand the diversity of the benchmark dataset, and explore synergies with other zero-shot and few-shot learning techniques.
Conclusion
This paper presents a simple yet effective framework for open-vocabulary zero-shot segmentation, leveraging Cascade-CLIP to align visual and textual representations. The approach enables segmentation of objects without requiring any labeled training data, which could have significant practical applications. The introduction of the LVIS-Textual dataset also provides a valuable benchmark for evaluating zero-shot segmentation models. While the current performance is still lower than supervised methods, this work represents an important step towards more flexible and accessible object segmentation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
0
0
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
6/7/2024
👁️
Retrieval Enhanced Zero-Shot Video Captioning
Yunchuan Ma, Laiyun Qing, Guorong Li, Yuankai Qi, Quan Z. Sheng, Qingming Huang
0
0
Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
5/14/2024

Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity
Zhenlin Xu, Yi Zhu, Tiffany Deng, Abhay Mittal, Yanbei Chen, Manchen Wang, Paolo Favaro, Joseph Tighe, Davide Modolo
0
0
This paper presents novel benchmarks for evaluating vision-language models (VLMs) in zero-shot recognition, focusing on granularity and specificity. Although VLMs excel in tasks like image captioning, they face challenges in open-world settings. Our benchmarks test VLMs' consistency in understanding concepts across semantic granularity levels and their response to varying text specificity. Findings show that VLMs favor moderately fine-grained concepts and struggle with specificity, often misjudging texts that differ from their training data. Extensive evaluations reveal limitations in current VLMs, particularly in distinguishing between correct and subtly incorrect descriptions. While fine-tuning offers some improvements, it doesn't fully address these issues, highlighting the need for VLMs with enhanced generalization capabilities for real-world applications. This study provides insights into VLM limitations and suggests directions for developing more robust models.
6/19/2024
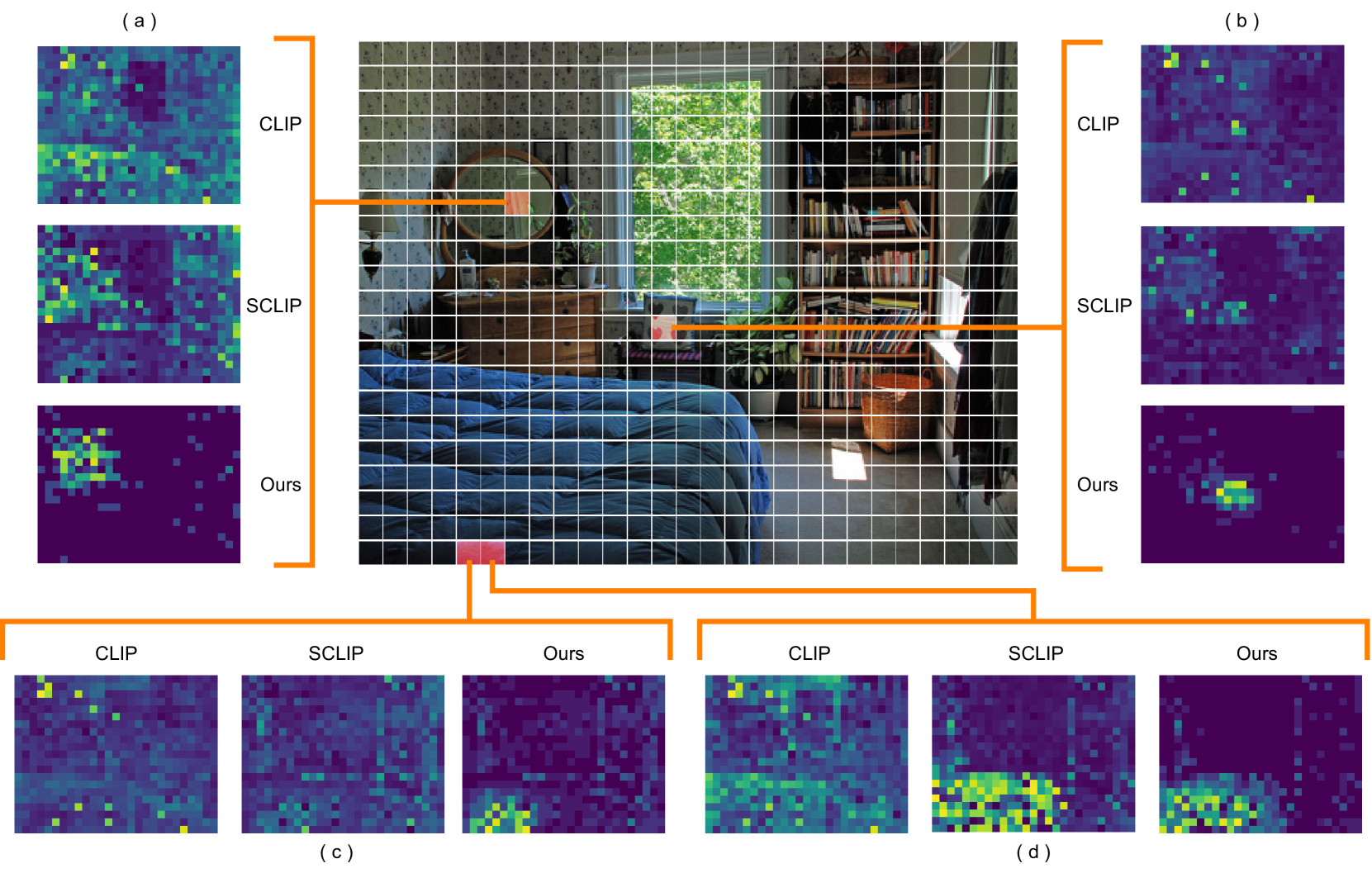
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Sina Hajimiri, Ismail Ben Ayed, Jose Dolz
0
0
Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
4/15/2024