Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning
2404.14808
0
0
👁️
Abstract
Generative Zero-shot learning (ZSL) learns a generator to synthesize visual samples for unseen classes, which is an effective way to advance ZSL. However, existing generative methods rely on the conditions of Gaussian noise and the predefined semantic prototype, which limit the generator only optimized on specific seen classes rather than characterizing each visual instance, resulting in poor generalizations (textit{e.g.}, overfitting to seen classes). To address this issue, we propose a novel Visual-Augmented Dynamic Semantic prototype method (termed VADS) to boost the generator to learn accurate semantic-visual mapping by fully exploiting the visual-augmented knowledge into semantic conditions. In detail, VADS consists of two modules: (1) Visual-aware Domain Knowledge Learning module (VDKL) learns the local bias and global prior of the visual features (referred to as domain visual knowledge), which replace pure Gaussian noise to provide richer prior noise information; (2) Vision-Oriented Semantic Updation module (VOSU) updates the semantic prototype according to the visual representations of the samples. Ultimately, we concatenate their output as a dynamic semantic prototype, which serves as the condition of the generator. Extensive experiments demonstrate that our VADS achieves superior CZSL and GZSL performances on three prominent datasets and outperforms other state-of-the-art methods with averaging increases by 6.4%, 5.9% and 4.2% on SUN, CUB and AWA2, respectively.
Create account to get full access
Overview
- Generative Zero-Shot Learning (ZSL) uses a generator to create visual samples for unseen classes, advancing ZSL
- Existing generative methods rely on Gaussian noise and predefined semantic prototypes, limiting the generator to specific seen classes and leading to poor generalization
- The proposed Visual-Augmented Dynamic Semantic prototype (VADS) method aims to improve the generator's ability to learn accurate semantic-visual mapping by leveraging visual-augmented knowledge
Plain English Explanation
The paper presents a new approach called VADS (Visual-Augmented Dynamic Semantic prototype) to improve the performance of Generative Zero-Shot Learning (ZSL). Generative ZSL uses a generator to create visual samples for classes that the model hasn't seen before, which helps the model learn better.
However, existing generative methods have some limitations. They rely on Gaussian noise (random numbers) and predefined semantic prototypes (fixed representations of the classes). This means the generator is only optimized for the specific classes it has seen, rather than being able to capture the characteristics of each individual visual example. As a result, the model doesn't generalize well and can overfit to the seen classes.
To address this, VADS has two key components:
-
Visual-aware Domain Knowledge Learning module (VDKL): This module learns the local and global properties of the visual features, replacing the simple Gaussian noise with richer prior information.
-
Vision-Oriented Semantic Updation module (VOSU): This module updates the semantic prototypes based on the visual representations of the samples, making the prototypes more dynamic and aligned with the actual visual data.
By combining these two components, VADS creates a "dynamic semantic prototype" that serves as the condition for the generator. This helps the generator learn a more accurate mapping between the visual and semantic information, leading to better performance on both Conventional ZSL (CZSL) and Generalized ZSL (GZSL) tasks.
Technical Explanation
The VADS method consists of two main modules:
-
Visual-aware Domain Knowledge Learning (VDKL): This module learns the local bias and global prior of the visual features, referred to as the "domain visual knowledge". This replaces the pure Gaussian noise used in previous methods, providing the generator with richer prior information.
-
Vision-Oriented Semantic Updation (VOSU): This module updates the semantic prototype (a fixed representation of each class) based on the visual representations of the samples. This makes the semantic prototype more dynamic and aligned with the actual visual data, rather than being predefined.
The output of these two modules is concatenated to form a "dynamic semantic prototype", which is used as the condition for the generator. This helps the generator learn a more accurate mapping between the visual and semantic information, improving its ability to generate samples for unseen classes.
The authors evaluate VADS on three prominent datasets (SUN, CUB, and AWA2) and show that it outperforms other state-of-the-art methods in both Conventional ZSL (CZSL) and Generalized ZSL (GZSL) settings. On average, VADS achieves increases of 6.4%, 5.9%, and 4.2% on the respective datasets.
Critical Analysis
The VADS method presents a promising approach to address the limitations of existing generative ZSL methods. By incorporating visual-augmented knowledge and dynamic semantic prototypes, the generator is able to learn a more accurate mapping between visual and semantic information, leading to improved performance on unseen classes.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the proposed approach. For example, it would be interesting to understand how VADS performs in scenarios with a large number of unseen classes, or how the method might be affected by noisy or biased visual data.
Additionally, the paper could benefit from a deeper discussion of the tradeoffs and design choices involved in the VDKL and VOSU modules. For instance, how do the specific architectural choices and hyperparameters of these modules impact the overall performance?
Future research could also explore ways to further bridge the projection gap and improve the semantic-visual alignment in generative ZSL, building upon the insights and techniques presented in this paper.
Conclusion
The VADS method proposed in this paper represents a significant advancement in generative Zero-Shot Learning (ZSL). By leveraging visual-augmented knowledge and dynamic semantic prototypes, the generator is able to learn a more accurate mapping between visual and semantic information, leading to improved performance on unseen classes.
The results demonstrate the effectiveness of VADS, with substantial gains over other state-of-the-art methods. This work highlights the importance of incorporating richer visual and semantic representations to enhance the generalization capabilities of ZSL models, and it opens up avenues for further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
Shiming Chen, Wenjin Hou, Salman Khan, Fahad Shahbaz Khan
0
0
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2.
4/12/2024

Less but Better: Enabling Generalized Zero-shot Learning Towards Unseen Domains by Intrinsic Learning from Redundant LLM Semantics
Jiaqi Yue, Jiancheng Zhao, Chunhui Zhao
0
0
Generalized zero-shot learning (GZSL) focuses on recognizing seen and unseen classes against domain shift problem (DSP) where data of unseen classes may be misclassified as seen classes. However, existing GZSL is still limited to seen domains. In the current work, we pioneer cross-domain GZSL (CDGZSL) which addresses GZSL towards unseen domains. Different from existing GZSL methods which alleviate DSP by generating features of unseen classes with semantics, CDGZSL needs to construct a common feature space across domains and acquire the corresponding intrinsic semantics shared among domains to transfer from seen to unseen domains. Considering the information asymmetry problem caused by redundant class semantics annotated with large language models (LLMs), we present Meta Domain Alignment Semantic Refinement (MDASR). Technically, MDASR consists of two parts: Inter-class Similarity Alignment (ISA), which eliminates the non-intrinsic semantics not shared across all domains under the guidance of inter-class feature relationships, and Unseen-class Meta Generation (UMG), which preserves intrinsic semantics to maintain connectivity between seen and unseen classes by simulating feature generation. MDASR effectively aligns the redundant semantic space with the common feature space, mitigating the information asymmetry in CDGZSL. The effectiveness of MDASR is demonstrated on the Office-Home and Mini-DomainNet, and we have shared the LLM-based semantics for these datasets as the benchmark.
5/24/2024
📊
Exploring Data Efficiency in Zero-Shot Learning with Diffusion Models
Zihan Ye, Shreyank N. Gowda, Xiaobo Jin, Xiaowei Huang, Haotian Xu, Yaochu Jin, Kaizhu Huang
0
0
Zero-Shot Learning (ZSL) aims to enable classifiers to identify unseen classes by enhancing data efficiency at the class level. This is achieved by generating image features from pre-defined semantics of unseen classes. However, most current approaches heavily depend on the number of samples from seen classes, i.e. they do not consider instance-level effectiveness. In this paper, we demonstrate that limited seen examples generally result in deteriorated performance of generative models. To overcome these challenges, we propose ZeroDiff, a Diffusion-based Generative ZSL model. This unified framework incorporates diffusion models to improve data efficiency at both the class and instance levels. Specifically, for instance-level effectiveness, ZeroDiff utilizes a forward diffusion chain to transform limited data into an expanded set of noised data. For class-level effectiveness, we design a two-branch generation structure that consists of a Diffusion-based Feature Generator (DFG) and a Diffusion-based Representation Generator (DRG). DFG focuses on learning and sampling the distribution of cross-entropy-based features, whilst DRG learns the supervised contrastive-based representation to boost the zero-shot capabilities of DFG. Additionally, we employ three discriminators to evaluate generated features from various aspects and introduce a Wasserstein-distance-based mutual learning loss to transfer knowledge among discriminators, thereby enhancing guidance for generation. Demonstrated through extensive experiments on three popular ZSL benchmarks, our ZeroDiff not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code will be released upon acceptance.
6/6/2024
OpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
Gonca Yilmaz, Songyou Peng, Francis Engelmann, Marc Pollefeys, Hermann Blum
0
0
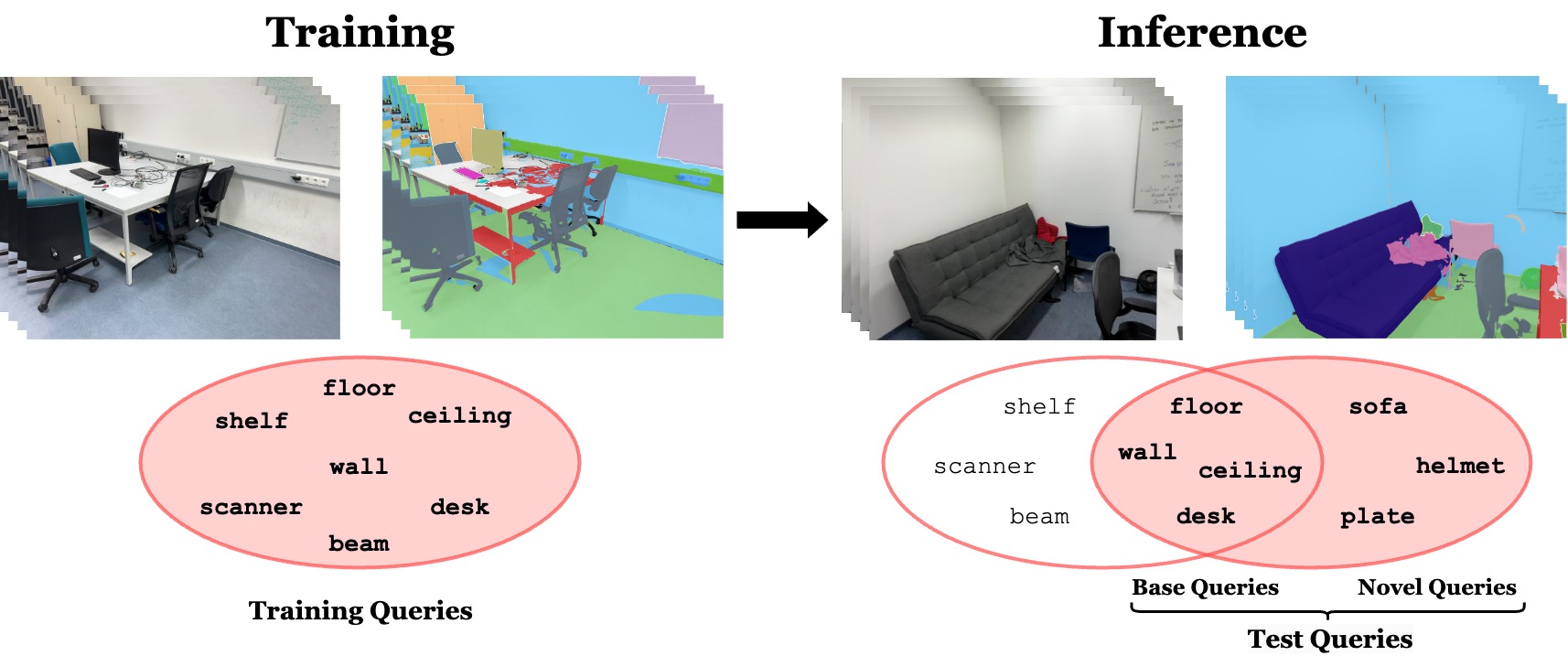
The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.
5/31/2024