PRoLoRA: Partial Rotation Empowers More Parameter-Efficient LoRA
2402.16902
0
0
Abstract
With the rapid scaling of large language models (LLMs), serving numerous low-rank adaptations (LoRAs) concurrently has become increasingly impractical, leading to unaffordable costs and necessitating more parameter-efficient finetuning methods. In this work, we introduce Partially Rotation-enhanced Low-Rank Adaptation (PRoLoRA), an intra-layer sharing mechanism comprising four essential components: broadcast reduction, rotation enhancement, partially-sharing refinement, and rectified initialization strategy. As a superset of LoRA, PRoLoRA retains its advantages, and effectively circumvent the drawbacks of peer parameter-sharing methods with superior model capacity, practical feasibility, and broad applicability. Empirical experiments demonstrate the remarkably higher parameter efficiency of PRoLoRA in both specific parameter budget and performance target scenarios, and its scalability to larger LLMs. Notably, with one time less trainable parameters, PRoLoRA still outperforms LoRA on multiple instruction tuning datasets. Subsequently, an ablation study is conducted to validate the necessity of individual components and highlight the superiority of PRoLoRA over three potential variants. Hopefully, the conspicuously higher parameter efficiency can establish PRoLoRA as a resource-friendly alternative to LoRA.
Create account to get full access
Overview
- This paper introduces PRoLoRA, a new technique that improves the parameter efficiency of the popular LoRA (Low-Rank Adaptation) fine-tuning method for large language models.
- LoRA is a technique that allows models to be fine-tuned with far fewer parameters than traditional fine-tuning, but PRoLoRA takes this a step further by using a "partial rotation" approach to reduce the number of parameters even more.
- The paper demonstrates that PRoLoRA can achieve comparable performance to LoRA while requiring only a fraction of the additional parameters, making it a more efficient way to fine-tune large language models for specific tasks.
Plain English Explanation
The paper discusses a new technique called PRoLoRA (Partial Rotation Empowers More Parameter-Efficient LoRA) that builds upon the existing LoRA (Link) fine-tuning method. LoRA is a way to fine-tune large language models like GPT-3 or BERT for specific tasks, but it still requires adding a significant number of additional parameters to the model.
PRoLoRA takes a different approach by only updating a "partial rotation" of the model's weights during fine-tuning. This means that instead of updating all the weights, it only updates a subset of them, which reduces the number of additional parameters needed. The authors show that this partial rotation approach can achieve similar performance to the original LoRA method, but with far fewer extra parameters.
This is important because it makes fine-tuning large language models more efficient and practical. The fewer parameters you need to add, the less computational power and memory is required, which can make fine-tuning feasible for a wider range of applications and devices. The MORA and HydraLoRA techniques also aim to improve the parameter efficiency of LoRA, but PRoLoRA appears to take this even further.
Technical Explanation
The key innovation in PRoLoRA is the "partial rotation" approach to updating the model's weights during fine-tuning. Rather than updating the full set of weights as in traditional fine-tuning or the original LoRA (Link) method, PRoLoRA only updates a subset of the weights.
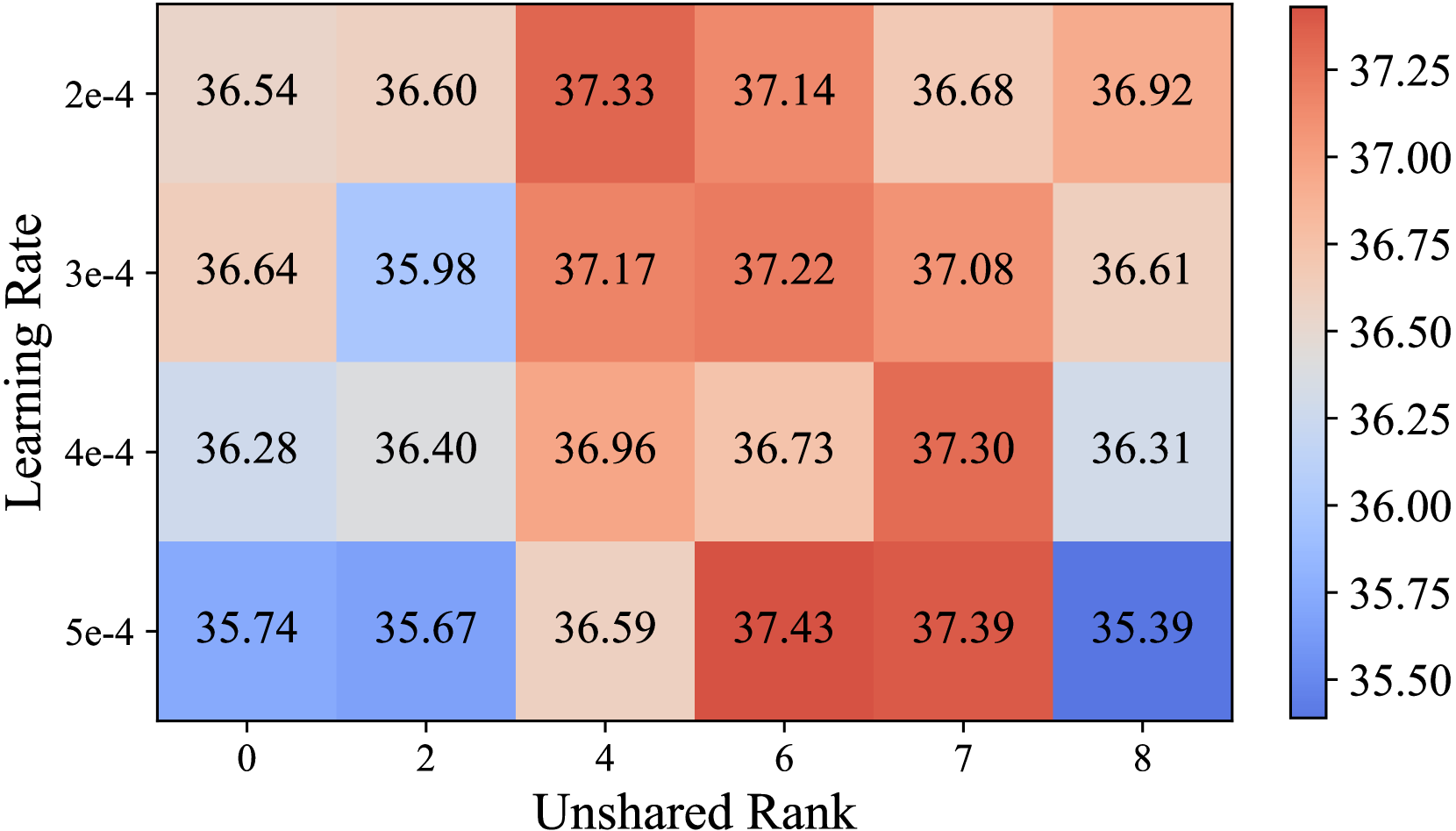
Specifically, PRoLoRA introduces two new matrices, A and B, that are used to update only a portion of the model's weight matrix. The authors show that by carefully selecting the dimensions of these matrices, they can achieve comparable performance to LoRA while drastically reducing the number of additional parameters required.
In their experiments, the authors demonstrate that PRoLoRA can match the performance of LoRA on several language modeling benchmarks, but with only 10-25% of the extra parameters. This suggests that PRoLoRA is a more parameter-efficient way to fine-tune large language models for specific tasks.
The authors also provide an analysis of the trade-offs involved in selecting the dimensions of the A and B matrices, and how this affects the performance and parameter efficiency of the fine-tuned model.
Critical Analysis
The PRoLoRA approach seems promising as a way to improve the parameter efficiency of LoRA fine-tuning, but the paper does not explore some potential limitations or areas for further research:
-
The experiments are focused on language modeling tasks, but it's unclear how well PRoLoRA would perform on other types of tasks, such as question answering or text generation. More extensive evaluation across a broader range of tasks would help establish the generalizability of the technique.
-
The paper does not provide much insight into the underlying reasons why the partial rotation approach is more parameter-efficient than the original LoRA method. A deeper theoretical analysis of the technique could help provide more intuition and guide future improvements.
-
The authors mention that the dimensions of the A and B matrices are important hyperparameters that need to be carefully selected, but they don't provide clear guidelines or heuristics for how to choose these values. More research is needed to understand how to optimize these hyperparameters for different models and tasks.
-
It's unclear how well PRoLoRA would scale to larger language models or more complex fine-tuning scenarios. The MORA and HydraLoRA techniques may offer complementary approaches that could be combined with PRoLoRA for even greater parameter efficiency.
Overall, the PRoLoRA technique seems like a promising step forward in making fine-tuning of large language models more practical and accessible, but there are still opportunities for further research and development to address its limitations and expand its capabilities.
Conclusion
The PRoLoRA paper introduces a new fine-tuning technique that builds on the popular LoRA method to achieve greater parameter efficiency. By only updating a "partial rotation" of the model's weights during fine-tuning, PRoLoRA can match the performance of LoRA while requiring significantly fewer additional parameters.
This is an important advancement because it makes fine-tuning large language models more feasible, especially for applications with limited computational resources. The reduced parameter requirements of PRoLoRA could enable fine-tuning on a wider range of devices and open up new possibilities for deploying these powerful models in real-world scenarios.
While the paper demonstrates the effectiveness of PRoLoRA on language modeling tasks, further research is needed to explore its applicability to other domains and address some of the remaining limitations. Nonetheless, the core idea of partial rotation is a valuable contribution that could inspire additional innovations in parameter-efficient fine-tuning of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ShareLoRA: Parameter Efficient and Robust Large Language Model Fine-tuning via Shared Low-Rank Adaptation
Yurun Song, Junchen Zhao, Ian G. Harris, Sangeetha Abdu Jyothi
0
0
This study introduces an approach to optimize Parameter Efficient Fine Tuning (PEFT) for Pretrained Language Models (PLMs) by implementing a Shared Low Rank Adaptation (ShareLoRA). By strategically deploying ShareLoRA across different layers and adapting it for the Query, Key, and Value components of self-attention layers, we achieve a substantial reduction in the number of training parameters and memory usage. Importantly, ShareLoRA not only maintains model performance but also exhibits robustness in both classification and generation tasks across a variety of models, including RoBERTa, GPT-2, LLaMA and LLaMA2. It demonstrates superior transfer learning capabilities compared to standard LoRA applications and mitigates overfitting by sharing weights across layers. Our findings affirm that ShareLoRA effectively boosts parameter efficiency while ensuring scalable and high-quality performance across different language model architectures.
6/18/2024

OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models
Kerim Buyukakyuz
0
0
The advent of large language models (LLMs) has revolutionized natural language processing, enabling unprecedented capabilities in understanding and generating human-like text. However, the computational cost and convergence times associated with fine-tuning these models remain significant challenges. Low-Rank Adaptation (LoRA) has emerged as a promising method to mitigate these issues by introducing efficient fine-tuning techniques with a reduced number of trainable parameters. In this paper, we present OLoRA, an enhancement to the LoRA method that leverages orthonormal matrix initialization through QR decomposition. OLoRA significantly accelerates the convergence of LLM training while preserving the efficiency benefits of LoRA, such as the number of trainable parameters and GPU memory footprint. Our empirical evaluations demonstrate that OLoRA not only converges faster but also exhibits improved performance compared to standard LoRA across a variety of language modeling tasks. This advancement opens new avenues for more efficient and accessible fine-tuning of LLMs, potentially enabling broader adoption and innovation in natural language applications.
6/5/2024

Unlocking the Global Synergies in Low-Rank Adapters
Zixi Zhang, Cheng Zhang, Xitong Gao, Robert D. Mullins, George A. Constantinides, Yiren Zhao
0
0
Low-rank Adaption (LoRA) has been the de-facto parameter-efficient fine-tuning technique for large language models. We present HeteroLoRA, a light-weight search algorithm that leverages zero-cost proxies to allocate the limited LoRA trainable parameters across the model for better fine-tuned performance. In addition to the allocation for the standard LoRA-adapted models, we also demonstrate the efficacy of HeteroLoRA by performing the allocation in a more challenging search space that includes LoRA modules and LoRA-adapted shortcut connections. Experiments show that HeteroLoRA enables improvements in model performance given the same parameter budge. For example, on MRPC, we see an improvement of 1.6% in accuracy with similar training parameter budget. We will open-source our algorithm once the paper is accepted.
6/24/2024
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
0
0
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
4/16/2024