Unlocking the Global Synergies in Low-Rank Adapters
2406.14956
0
0

Abstract
Low-rank Adaption (LoRA) has been the de-facto parameter-efficient fine-tuning technique for large language models. We present HeteroLoRA, a light-weight search algorithm that leverages zero-cost proxies to allocate the limited LoRA trainable parameters across the model for better fine-tuned performance. In addition to the allocation for the standard LoRA-adapted models, we also demonstrate the efficacy of HeteroLoRA by performing the allocation in a more challenging search space that includes LoRA modules and LoRA-adapted shortcut connections. Experiments show that HeteroLoRA enables improvements in model performance given the same parameter budge. For example, on MRPC, we see an improvement of 1.6% in accuracy with similar training parameter budget. We will open-source our algorithm once the paper is accepted.
Create account to get full access
Overview
- This paper proposes a new technique called HeteroLoRA, which aims to unlock global synergies in low-rank adapters (LoRA) for more efficient fine-tuning of large language models.
- LoRA is a popular method for fine-tuning language models by adding small, task-specific parameter updates rather than updating all model parameters, which can be computationally expensive.
- HeteroLoRA extends LoRA by enabling the use of different low-rank matrices for different layers of the model, allowing for more flexibility and better performance.
Plain English Explanation
HeteroLoRA: Unlocking the Global Synergies in Low-Rank Adapters is a new technique that builds on the idea of Low-Rank Adaptation (LoRA). LoRA is a way to fine-tune large language models without having to update all of the model's parameters, which can be very computationally expensive. Instead, LoRA only updates a small number of parameters, making the fine-tuning process much more efficient.
The key insight of HeteroLoRA is that different layers of a language model might benefit from different types of low-rank updates. So instead of using the same low-rank matrices across all layers, HeteroLoRA allows for different low-rank matrices to be used for different layers. This added flexibility can lead to better performance and more efficient fine-tuning.
Imagine you have a large language model that you want to fine-tune for a specific task, like summarizing scientific papers. With traditional fine-tuning, you'd have to update all of the model's millions of parameters, which would be very slow and computationally intensive. LoRA provides a more efficient solution by only updating a small subset of the parameters.
HeteroLoRA takes this one step further by allowing the low-rank updates to be customized for different parts of the model. So the low-rank updates for the earlier layers might be different from the updates for the later layers, which can help the model learn the task more effectively. This added flexibility is the key innovation of HeteroLoRA.
Technical Explanation
HeteroLoRA extends the Low-Rank Adaptation (LoRA) technique by allowing for the use of different low-rank matrices for different layers of a language model during fine-tuning.
The basic idea behind LoRA is to fine-tune a pre-trained language model by only updating a small number of parameters, rather than updating all of the model's parameters. This is achieved by introducing low-rank update matrices that are added to the original weight matrices of the model. These low-rank updates can be learned efficiently during fine-tuning, leading to significant improvements in performance while requiring much less computational resources compared to full fine-tuning.
HeteroLoRA builds on this by allowing the use of different low-rank matrices for different layers of the model. This added flexibility can lead to better performance, as different layers of the model may benefit from different types of low-rank updates. The paper presents a formulation of HeteroLoRA and shows its advantages over standard LoRA through extensive experiments on a variety of language modeling tasks.
The Tied LoRA and ProLoRA techniques are also discussed in the context of improving the parameter efficiency of LoRA-based fine-tuning. The paper also compares HeteroLoRA to the LoRA-XS method, which aims to further reduce the number of parameters required for fine-tuning.
Critical Analysis
The HeteroLoRA paper presents a compelling approach to improving the efficiency and effectiveness of fine-tuning large language models. By allowing for the use of different low-rank matrices in different layers of the model, the technique provides more flexibility and can lead to better performance compared to standard LoRA.
However, the paper does not address some potential limitations of the HeteroLoRA approach. For example, the increased flexibility may come at the cost of additional hyperparameters that need to be tuned, which could make the fine-tuning process more complex. Additionally, the paper does not explore the trade-offs between the performance gains of HeteroLoRA and the increased computational and memory requirements compared to simpler LoRA-based methods.
Further research could also investigate the generalization of HeteroLoRA to different model architectures and fine-tuning scenarios beyond language modeling. Exploring the interpretability of the learned low-rank matrices and their connection to the underlying structure of the language model could also be an interesting direction for future work.
Overall, the HeteroLoRA paper makes a valuable contribution to the field of efficient fine-tuning of large language models, and the proposed technique shows promising results. However, as with any new research, there are still opportunities to explore the limitations and potential extensions of the approach.
Conclusion
HeteroLoRA is a novel technique that builds on the successful Low-Rank Adaptation (LoRA) method for efficiently fine-tuning large language models. By allowing the use of different low-rank matrices for different layers of the model, HeteroLoRA provides more flexibility and can lead to better performance compared to standard LoRA.
The paper's key innovation is the insight that different parts of a language model may benefit from different types of low-rank updates during fine-tuning. This added flexibility, enabled by the HeteroLoRA approach, can help language models learn task-specific information more effectively while still requiring significantly fewer parameters to be updated compared to full fine-tuning.
The technical details and experimental results presented in the paper suggest that HeteroLoRA is a promising direction for improving the efficiency and effectiveness of fine-tuning large language models, with potential applications in a wide range of natural language processing tasks. As the field of large language models continues to evolve, techniques like HeteroLoRA will likely play an important role in making these powerful models more accessible and practically useful.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
A Note on LoRA
Vlad Fomenko, Han Yu, Jongho Lee, Stanley Hsieh, Weizhu Chen
0
0
LoRA (Low-Rank Adaptation) has emerged as a preferred method for efficiently adapting Large Language Models (LLMs) with remarkable simplicity and efficacy. This note extends the original LoRA paper by offering new perspectives that were not initially discussed and presents a series of insights for deploying LoRA at scale. Without introducing new experiments, we aim to improve the understanding and application of LoRA.
4/9/2024
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
0
0
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
4/16/2024
🌀
Tied-Lora: Enhancing parameter efficiency of LoRA with weight tying
Adithya Renduchintala, Tugrul Konuk, Oleksii Kuchaiev
0
0
We introduce Tied-LoRA, a novel paradigm leveraging weight tying and selective training to enhance the parameter efficiency of Low-rank Adaptation (LoRA). Our exploration encompasses different plausible combinations of parameter training and freezing, coupled with weight tying, aimed at identifying the optimal trade-off between performance and the count of trainable parameters. Across $5$ diverse tasks and two foundational language models with different parameter counts, our experiments provide comprehensive insights into the inherent trade-offs between efficiency and performance. Our findings reveal a specific Tied-LoRA configuration that distinguishes itself by showcasing comparable performance to LoRA across multiple tasks while utilizing only a fraction of the parameters employed by the standard LoRA method, particularly at elevated ranks. This underscores the efficacy of Tied-LoRA in achieving impressive results with significantly reduced model complexity.
4/16/2024
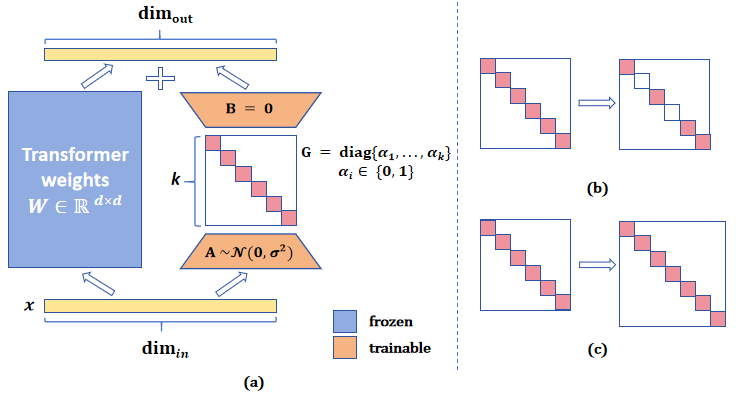
PRoLoRA: Partial Rotation Empowers More Parameter-Efficient LoRA
Sheng Wang, Boyang Xue, Jiacheng Ye, Jiyue Jiang, Liheng Chen, Lingpeng Kong, Chuan Wu
0
0
With the rapid scaling of large language models (LLMs), serving numerous low-rank adaptations (LoRAs) concurrently has become increasingly impractical, leading to unaffordable costs and necessitating more parameter-efficient finetuning methods. In this work, we introduce Partially Rotation-enhanced Low-Rank Adaptation (PRoLoRA), an intra-layer sharing mechanism comprising four essential components: broadcast reduction, rotation enhancement, partially-sharing refinement, and rectified initialization strategy. As a superset of LoRA, PRoLoRA retains its advantages, and effectively circumvent the drawbacks of peer parameter-sharing methods with superior model capacity, practical feasibility, and broad applicability. Empirical experiments demonstrate the remarkably higher parameter efficiency of PRoLoRA in both specific parameter budget and performance target scenarios, and its scalability to larger LLMs. Notably, with one time less trainable parameters, PRoLoRA still outperforms LoRA on multiple instruction tuning datasets. Subsequently, an ablation study is conducted to validate the necessity of individual components and highlight the superiority of PRoLoRA over three potential variants. Hopefully, the conspicuously higher parameter efficiency can establish PRoLoRA as a resource-friendly alternative to LoRA.
5/28/2024