Prompt-based Visual Alignment for Zero-shot Policy Transfer

0
Sign in to get full access
Overview
- This paper introduces a method called "Prompt-based Visual Alignment" for zero-shot policy transfer, which allows an AI agent to learn how to perform a task in one environment and then apply that knowledge to a new, visually different environment without any additional training.
- The key idea is to use language prompts to align the agent's understanding of the task with the visual representation of the new environment, enabling it to apply its existing policy effectively.
- The authors demonstrate the effectiveness of their approach on several challenging robotic manipulation tasks, showing that it can outperform previous methods for zero-shot policy transfer.
Plain English Explanation
Imagine you've trained a robot to perform a specific task, like picking up a ball and putting it in a box. Now, you want that robot to do the same thing in a completely different environment, like a messy workshop with lots of clutter. [https://aimodels.fyi/papers/arxiv/vision-language-models-provide-promptable-representations-reinforcement] The challenge is that the robot's existing skills were trained on the original environment, so it may not know how to apply them to the new one.
The researchers in this paper developed a way to help the robot bridge that gap. They use language prompts - short descriptions of the task - to "align" the robot's understanding of what it's supposed to do with the visual features of the new environment. [https://aimodels.fyi/papers/arxiv/instructing-prompt-to-prompt-generation-zero-shot] This allows the robot to take its existing skills and apply them effectively, even though the new environment looks very different.
For example, the robot might be given a prompt like "Pick up the red ball and place it in the blue box." It can then use that prompt to recognize the relevant objects in the new environment and apply its existing ball-picking-up and box-placing abilities, without needing any additional training.
The researchers tested this approach on challenging robotic manipulation tasks, and found that it outperformed previous methods for transferring skills to new environments. [https://aimodels.fyi/papers/arxiv/promptsync-bridging-domain-gaps-vision-language-models] This is an important step towards building more flexible and capable robotic systems that can adapt to new situations without having to be retrained from scratch.
Technical Explanation
The key contribution of this paper is a method called "Prompt-based Visual Alignment" (PVA) for enabling zero-shot policy transfer in robotic manipulation tasks. The core idea is to use language prompts to bridge the gap between the agent's learned policy and the visual representation of a new environment.
The authors first train a policy on a source environment using reinforcement learning. They then use a vision-language model to extract visual features from the new target environment that align with the language prompt describing the task. [https://aimodels.fyi/papers/arxiv/exploring-sparse-visual-prompt-domain-adaptive-dense] These aligned visual features are then used to condition the agent's existing policy, allowing it to effectively apply its skills in the new setting without any additional training.
The authors evaluate PVA on a range of challenging robotic manipulation tasks, including block stacking, tool use, and multi-object rearrangement. They show that PVA significantly outperforms previous methods for zero-shot policy transfer, such as domain randomization and visual foresight. [https://aimodels.fyi/papers/arxiv/promoting-ai-equity-science-generalized-domain-prompt] The key advantage of PVA is its ability to leverage the agent's existing policy knowledge while adapting it to the visual features of the new environment through the use of language prompts.
Critical Analysis
One potential limitation of the PVA approach is its reliance on a pre-trained vision-language model to extract the relevant visual features. The performance of PVA may be sensitive to the quality and robustness of this underlying model, which could be a concern in real-world deployment scenarios with diverse and potentially noisy visual inputs.
Additionally, the authors only evaluate PVA on relatively simple robotic manipulation tasks. It remains to be seen how well the approach would scale to more complex, multi-step tasks or environments with higher visual complexity and clutter. Further research would be needed to understand the broader applicability and limitations of the PVA method.
That said, the core idea of using language prompts to bridge the gap between learned policies and new environments is a compelling one, and the strong empirical results presented in the paper suggest that PVA is a promising direction for enabling more flexible and adaptable robotic systems. As the authors note, this work represents an important step toward building AI agents that can transfer their skills to new situations without extensive retraining.
Conclusion
This paper introduces a novel method called "Prompt-based Visual Alignment" that enables zero-shot policy transfer for robotic manipulation tasks. By using language prompts to align the agent's understanding of a task with the visual features of a new environment, the researchers have developed a way to leverage existing policy knowledge without requiring additional training.
The empirical results demonstrate the effectiveness of this approach, showing significant performance gains over previous methods for zero-shot transfer. [https://aimodels.fyi/papers/arxiv/promptsync-bridging-domain-gaps-vision-language-models] While the current implementation has some limitations, the core ideas presented in this work represent an important step forward in building more flexible and capable AI systems that can adapt to novel situations.
As the field of robotics and reinforcement learning continues to advance, techniques like PVA will likely play an increasingly important role in enabling AI agents to fluidly transfer their skills and knowledge to a wide range of real-world environments and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt-based Visual Alignment for Zero-shot Policy Transfer
Haihan Gao, Rui Zhang, Qi Yi, Hantao Yao, Haochen Li, Jiaming Guo, Shaohui Peng, Yunkai Gao, QiCheng Wang, Xing Hu, Yuanbo Wen, Zihao Zhang, Zidong Du, Ling Li, Qi Guo, Yunji Chen
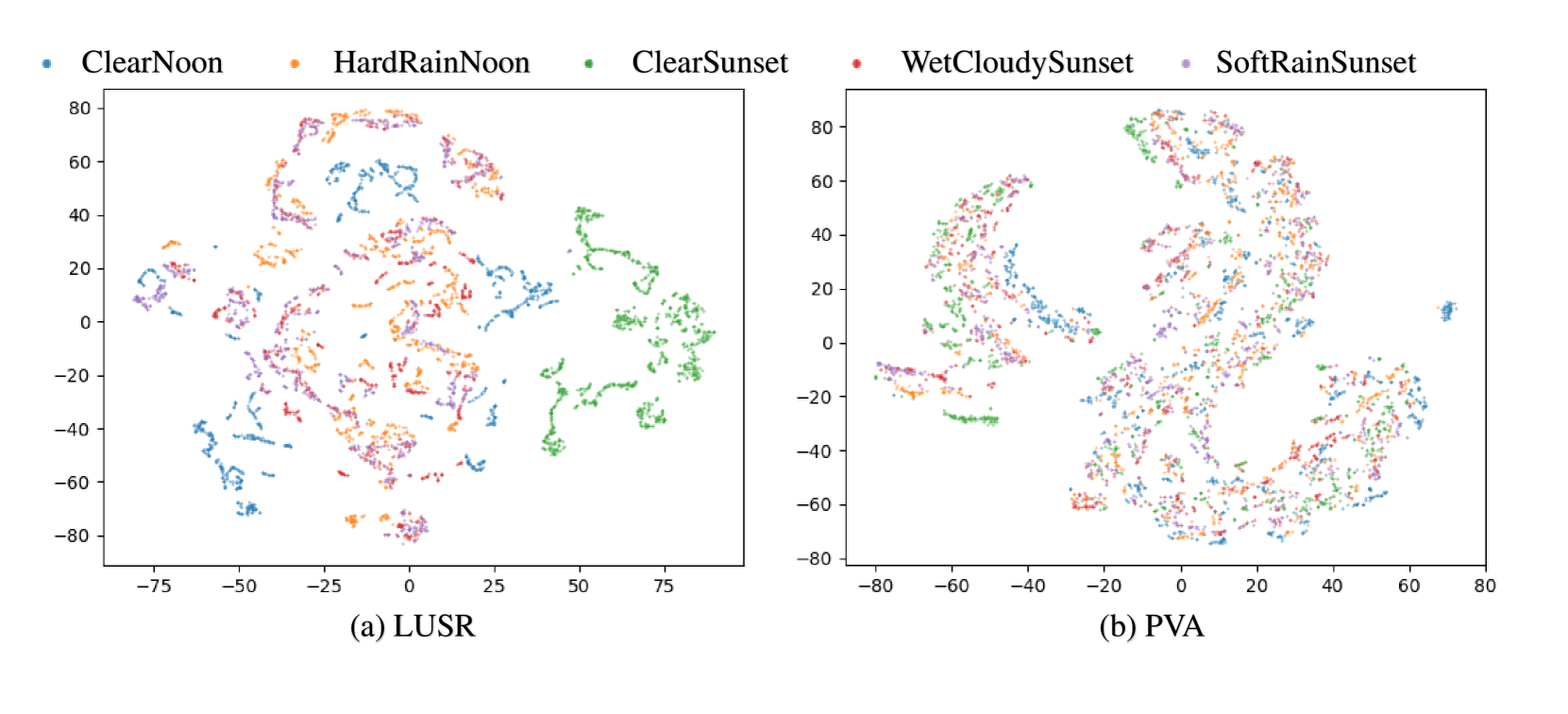
Overfitting in RL has become one of the main obstacles to applications in reinforcement learning(RL). Existing methods do not provide explicit semantic constrain for the feature extractor, hindering the agent from learning a unified cross-domain representation and resulting in performance degradation on unseen domains. Besides, abundant data from multiple domains are needed. To address these issues, in this work, we propose prompt-based visual alignment (PVA), a robust framework to mitigate the detrimental domain bias in the image for zero-shot policy transfer. Inspired that Visual-Language Model (VLM) can serve as a bridge to connect both text space and image space, we leverage the semantic information contained in a text sequence as an explicit constraint to train a visual aligner. Thus, the visual aligner can map images from multiple domains to a unified domain and achieve good generalization performance. To better depict semantic information, prompt tuning is applied to learn a sequence of learnable tokens. With explicit constraints of semantic information, PVA can learn unified cross-domain representation under limited access to cross-domain data and achieves great zero-shot generalization ability in unseen domains. We verify PVA on a vision-based autonomous driving task with CARLA simulator. Experiments show that the agent generalizes well on unseen domains under limited access to multi-domain data.
Read more6/6/2024

0
Domain Adaptation of Visual Policies with a Single Demonstration
Weiyao Wang, Gregory D. Hager
Deploying machine learning algorithms for robot tasks in real-world applications presents a core challenge: overcoming the domain gap between the training and the deployment environment. This is particularly difficult for visuomotor policies that utilize high-dimensional images as input, particularly when those images are generated via simulation. A common method to tackle this issue is through domain randomization, which aims to broaden the span of the training distribution to cover the test-time distribution. However, this approach is only effective when the domain randomization encompasses the actual shifts in the test-time distribution. We take a different approach, where we make use of a single demonstration (a prompt) to learn policy that adapts to the testing target environment. Our proposed framework, PromptAdapt, leverages the Transformer architecture's capacity to model sequential data to learn demonstration-conditioned visual policies, allowing for in-context adaptation to a target domain that is distinct from training. Our experiments in both simulation and real-world settings show that PromptAdapt is a strong domain-adapting policy that outperforms baseline methods by a large margin under a range of domain shifts, including variations in lighting, color, texture, and camera pose. Videos and more information can be viewed at project webpage: https://sites.google.com/view/promptadapt.
Read more7/25/2024
0
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
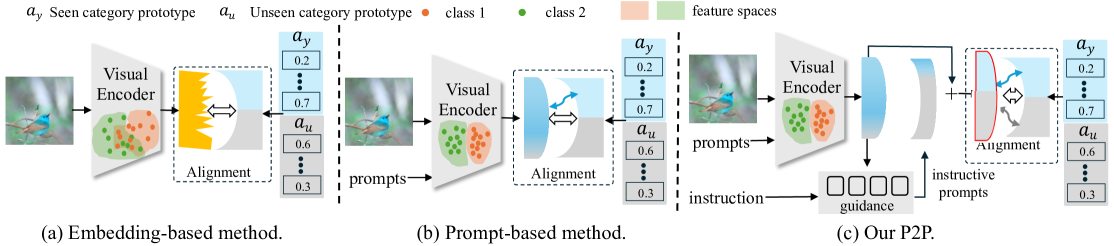
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Read more6/6/2024

0
PromptSync: Bridging Domain Gaps in Vision-Language Models through Class-Aware Prototype Alignment and Discrimination
Anant Khandelwal
The potential for zero-shot generalization in vision-language (V-L) models such as CLIP has spurred their widespread adoption in addressing numerous downstream tasks. Previous methods have employed test-time prompt tuning to adapt the model to unseen domains, but they overlooked the issue of imbalanced class distributions. In this study, we explicitly address this problem by employing class-aware prototype alignment weighted by mean class probabilities obtained for the test sample and filtered augmented views. Additionally, we ensure that the class probabilities are as accurate as possible by performing prototype discrimination using contrastive learning. The combination of alignment and discriminative loss serves as a geometric regularizer, preventing the prompt representation from collapsing onto a single class and effectively bridging the distribution gap between the source and test domains. Our method, named PromptSync, synchronizes the prompts for each test sample on both the text and vision branches of the V-L model. In empirical evaluations on the domain generalization benchmark, our method outperforms previous best methods by 2.33% in overall performance, by 1% in base-to-novel generalization, and by 2.84% in cross-dataset transfer tasks.
Read more4/15/2024