Domain Adaptation of Visual Policies with a Single Demonstration

0

Sign in to get full access
Overview
- The paper explores a method for adapting visual policies to new domains using a single demonstration.
- The approach leverages contrastive learning to fine-tune a pre-trained policy network on a single example from the target domain.
- The technique aims to enable efficient transfer of skills from one environment to another with minimal additional training data.
Plain English Explanation
The paper presents a way to take an AI system that has learned how to do a task in one setting and adapt it to work in a different setting using just a single example from the new environment. This is useful because it can be expensive and time-consuming to collect large amounts of training data for AI systems, especially when trying to apply them to new scenarios.
The key idea is to use a technique called contrastive learning to fine-tune the AI system's neural network on the single example from the target domain. This allows the system to learn how the new environment differs from the original one it was trained on, and update its internal representation accordingly. The model can then be used to control a robot or agent in the new domain with the adapted visual policy.
This approach aims to enable efficient transfer of skills from one environment to another, requiring much less additional training data compared to starting from scratch. It could be helpful for applying AI systems to new real-world scenarios where collecting large datasets may not be feasible. The technique is explored in the context of using AI to control agents that interact with the visual world, like robots.
Technical Explanation
The paper proposes a method for domain adaptation of visual policies using only a single demonstration from the target domain. The key components are:
-
Pre-trained Policy Network: The system starts with a pre-trained neural network that has learned to map visual inputs to actions for a given task, such as controlling a robot.
-
Contrastive Fine-Tuning: To adapt this policy to a new domain, the network is fine-tuned using contrastive learning on a single example from the target environment. This allows the model to learn the key differences between the original and new domains.
-
Adapted Visual Policy: The fine-tuned network can then be used to control an agent or robot in the new domain, leveraging the adapted visual policy. This enables efficient transfer of skills without requiring large amounts of additional training data.
The experiments in the paper demonstrate the effectiveness of this approach across various simulated robotic control tasks, showing that the single-shot domain adaptation can match or outperform training from scratch with more data. The technique holds promise for applying AI systems to new real-world scenarios with minimal additional effort.
Critical Analysis
The paper provides a compelling approach for adapting visual policies to new domains using only a single demonstration. However, some potential limitations and areas for further research include:
-
Generalization Ability: The paper focuses on demonstrating the technique in simulated environments. More research is needed to understand how well it generalizes to real-world, unconstrained settings. Extending the approach to adapt to more significant distribution shifts may be an area for future work.
-
Robustness to Noise: The single demonstration used for fine-tuning may be sensitive to noise or slight variations in the target domain. Exploring ways to make the adaptation process more robust would be valuable.
-
Scalability: While the single-shot adaptation is efficient, scaling the technique to more complex tasks and larger policy networks remains an open challenge.
Overall, the paper presents a promising direction for enabling AI systems to adapt to new environments with minimal additional training, which could have significant practical implications. Further research to address the noted limitations could help strengthen the approach and broaden its applicability.
Conclusion
This paper introduces a method for efficiently adapting visual policies to new domains using only a single demonstration from the target environment. By leveraging contrastive learning to fine-tune a pre-trained policy network, the approach enables the transfer of skills with much less additional training data compared to starting from scratch.
The technique holds promise for applying AI systems to a wider range of real-world scenarios, where collecting large training datasets may not be feasible. While the paper demonstrates the effectiveness of the approach in simulated environments, further research is needed to address potential limitations around generalization, robustness, and scalability. Nonetheless, this work represents an important step towards making AI systems more adaptable and accessible for practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Domain Adaptation of Visual Policies with a Single Demonstration
Weiyao Wang, Gregory D. Hager
Deploying machine learning algorithms for robot tasks in real-world applications presents a core challenge: overcoming the domain gap between the training and the deployment environment. This is particularly difficult for visuomotor policies that utilize high-dimensional images as input, particularly when those images are generated via simulation. A common method to tackle this issue is through domain randomization, which aims to broaden the span of the training distribution to cover the test-time distribution. However, this approach is only effective when the domain randomization encompasses the actual shifts in the test-time distribution. We take a different approach, where we make use of a single demonstration (a prompt) to learn policy that adapts to the testing target environment. Our proposed framework, PromptAdapt, leverages the Transformer architecture's capacity to model sequential data to learn demonstration-conditioned visual policies, allowing for in-context adaptation to a target domain that is distinct from training. Our experiments in both simulation and real-world settings show that PromptAdapt is a strong domain-adapting policy that outperforms baseline methods by a large margin under a range of domain shifts, including variations in lighting, color, texture, and camera pose. Videos and more information can be viewed at project webpage: https://sites.google.com/view/promptadapt.
Read more7/25/2024
0
Adapting to Distribution Shift by Visual Domain Prompt Generation
Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
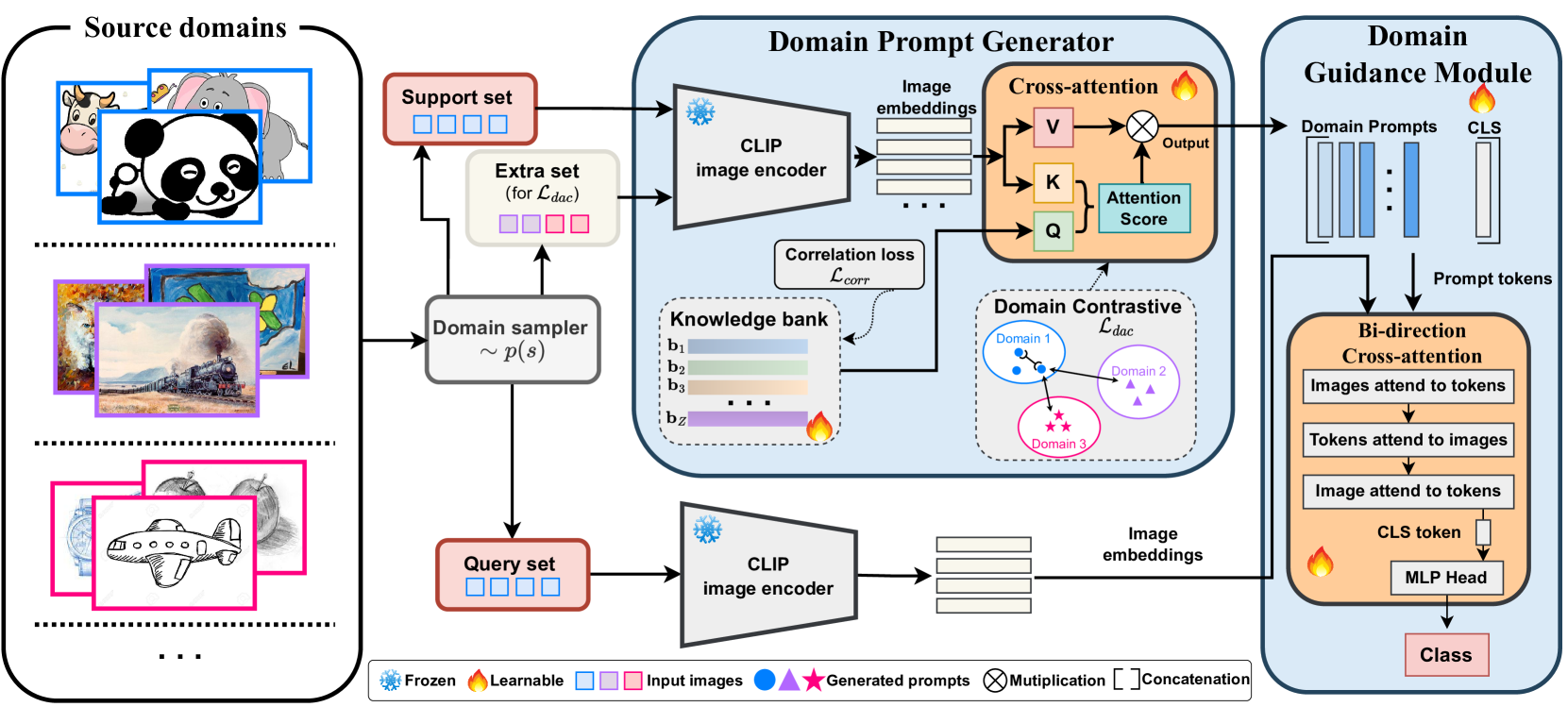
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Read more5/7/2024
0
Prompt-based Visual Alignment for Zero-shot Policy Transfer
Haihan Gao, Rui Zhang, Qi Yi, Hantao Yao, Haochen Li, Jiaming Guo, Shaohui Peng, Yunkai Gao, QiCheng Wang, Xing Hu, Yuanbo Wen, Zihao Zhang, Zidong Du, Ling Li, Qi Guo, Yunji Chen
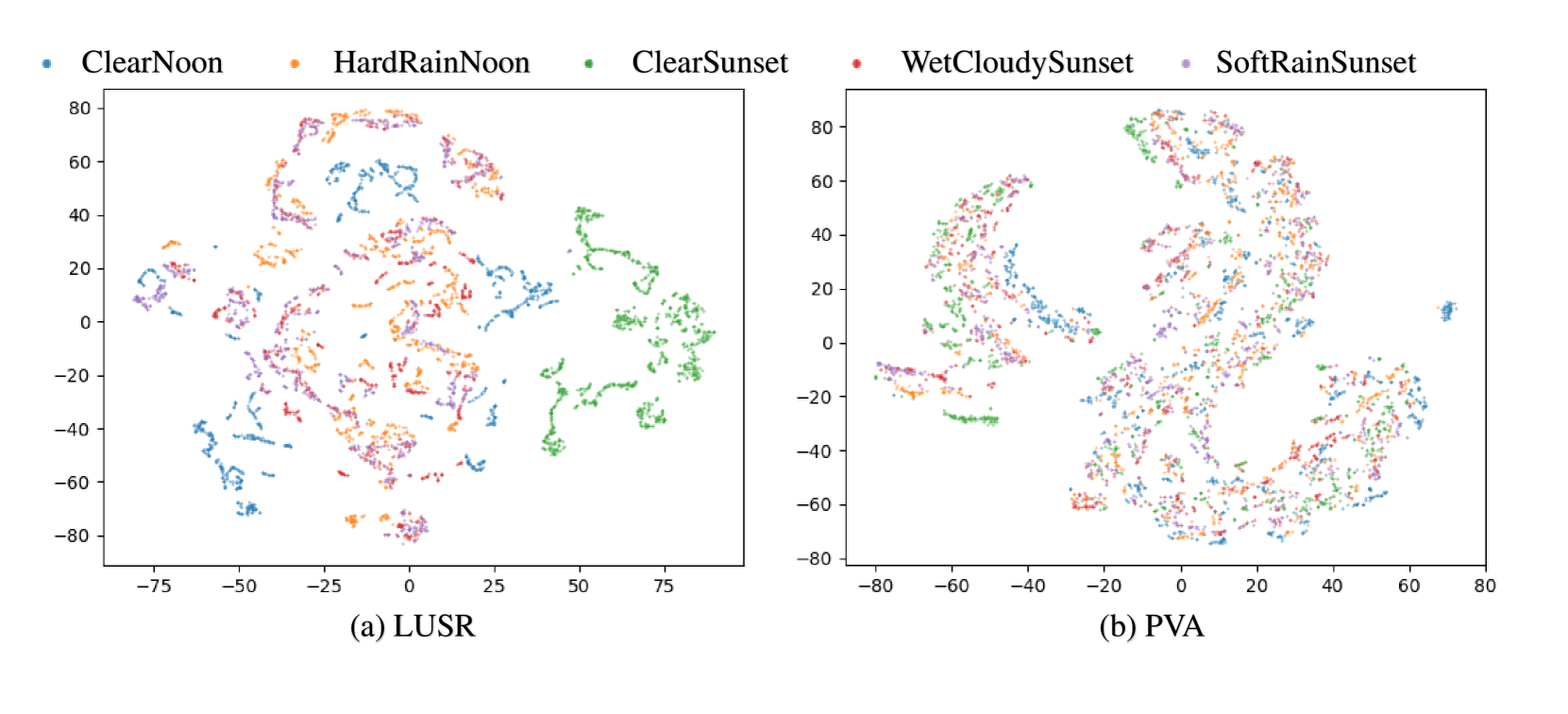
Overfitting in RL has become one of the main obstacles to applications in reinforcement learning(RL). Existing methods do not provide explicit semantic constrain for the feature extractor, hindering the agent from learning a unified cross-domain representation and resulting in performance degradation on unseen domains. Besides, abundant data from multiple domains are needed. To address these issues, in this work, we propose prompt-based visual alignment (PVA), a robust framework to mitigate the detrimental domain bias in the image for zero-shot policy transfer. Inspired that Visual-Language Model (VLM) can serve as a bridge to connect both text space and image space, we leverage the semantic information contained in a text sequence as an explicit constraint to train a visual aligner. Thus, the visual aligner can map images from multiple domains to a unified domain and achieve good generalization performance. To better depict semantic information, prompt tuning is applied to learn a sequence of learnable tokens. With explicit constraints of semantic information, PVA can learn unified cross-domain representation under limited access to cross-domain data and achieves great zero-shot generalization ability in unseen domains. We verify PVA on a vision-based autonomous driving task with CARLA simulator. Experiments show that the agent generalizes well on unseen domains under limited access to multi-domain data.
Read more6/6/2024
🔮
0
Exploring Sparse Visual Prompt for Domain Adaptive Dense Prediction
Senqiao Yang, Jiarui Wu, Jiaming Liu, Xiaoqi Li, Qizhe Zhang, Mingjie Pan, Yulu Gan, Zehui Chen, Shanghang Zhang
The visual prompts have provided an efficient manner in addressing visual cross-domain problems. In previous works, Visual Domain Prompt (VDP) first introduces domain prompts to tackle the classification Test-Time Adaptation (TTA) problem by warping image-level prompts on the input and fine-tuning prompts for each target domain. However, since the image-level prompts mask out continuous spatial details in the prompt-allocated region, it will suffer from inaccurate contextual information and limited domain knowledge extraction, particularly when dealing with dense prediction TTA problems. To overcome these challenges, we propose a novel Sparse Visual Domain Prompts (SVDP) approach, which holds minimal trainable parameters (e.g., 0.1%) in the image-level prompt and reserves more spatial information of the input. To better apply SVDP in extracting domain-specific knowledge, we introduce the Domain Prompt Placement (DPP) method to adaptively allocates trainable parameters of SVDP on the pixels with large distribution shifts. Furthermore, recognizing that each target domain sample exhibits a unique domain shift, we design Domain Prompt Updating (DPU) strategy to optimize prompt parameters differently for each sample, facilitating efficient adaptation to the target domain. Extensive experiments were conducted on widely-used TTA and continual TTA benchmarks, and our proposed method achieves state-of-the-art performance in both semantic segmentation and depth estimation tasks.
Read more4/16/2024