Prompt Compression with Context-Aware Sentence Encoding for Fast and Improved LLM Inference

0

Sign in to get full access
Overview
- The paper presents a method for compressing prompts used in large language models (LLMs) to enable faster and improved inference.
- It introduces a novel context-aware sentence encoding approach to encode prompts in a compact way.
- The proposed method outperforms existing prompt compression techniques in terms of inference speed and model performance.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful, but running them can be slow and resource-intensive. This is because the input "prompts" fed into these models can be quite long, containing a lot of context information. The paper explores a way to compress these prompts without losing important context, which can speed up the inference process and potentially improve model performance.
The key idea is to use a context-aware sentence encoding approach. This means taking the entire prompt and breaking it down into individual sentences, then encoding each sentence in a way that captures the unique context and meaning. This compressed representation can then be fed into the LLM, reducing the overall computation required.
The authors show that their method outperforms existing prompt compression techniques on a variety of benchmarks. By distilling the prompt into a more efficient form, they are able to run the LLM faster while maintaining or even improving the quality of the output.
Technical Explanation
The paper introduces a novel context-aware sentence encoding approach for prompt compression. The method works as follows:
- The input prompt is first split into individual sentences using a pre-trained sentence segmentation model.
- Each sentence is then encoded using a specialized context-aware sentence encoder. This encoder takes into account the broader context of the entire prompt when generating a compact representation for each sentence.
- The compressed sentence representations are concatenated and fed as the input to the target LLM, rather than the original full prompt.
The authors experiment with different architectures for the context-aware sentence encoder, including transformer-based models and specialized prompt compression networks. They demonstrate that this approach outperforms simpler prompt compression techniques, such as directly tokenizing and truncating the prompt.
The key advantage of this method is that it can preserve important contextual information from the prompt, even in a compressed form. This allows the LLM to maintain high performance while running much faster due to the reduced input size.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed prompt compression technique. The authors compare against several baselines and show consistent improvements in both inference speed and model performance across a range of tasks and datasets.
One potential limitation is that the method relies on a pre-trained sentence segmentation model, which could introduce errors or fail to capture contextual dependencies between sentences. The authors acknowledge this and suggest exploring end-to-end models that jointly perform sentence encoding and prompt compression.
Additionally, the paper does not explore the trade-offs between the degree of compression and the resulting model quality. It would be valuable to understand how the compression ratio and other hyperparameters impact the downstream performance, allowing users to make informed choices based on their specific requirements.
Overall, the paper makes a compelling case for the benefits of context-aware prompt compression and opens up interesting avenues for further research in this area.
Conclusion
This paper presents a novel approach for compressing prompts used in large language models, enabling faster and more efficient inference. By leveraging context-aware sentence encoding, the method is able to distill the prompt into a compact representation while preserving important contextual information.
The authors demonstrate significant improvements in both inference speed and model performance compared to existing prompt compression techniques. This work has the potential to unlock new possibilities for deploying powerful language models in resource-constrained environments, such as on mobile devices or at the edge.
Looking ahead, further research could explore end-to-end models for joint sentence segmentation and encoding, as well as techniques to dynamically adjust the compression ratio based on the specific requirements of a given application.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt Compression with Context-Aware Sentence Encoding for Fast and Improved LLM Inference
Barys Liskavets, Maxim Ushakov, Shuvendu Roy, Mark Klibanov, Ali Etemad, Shane Luke
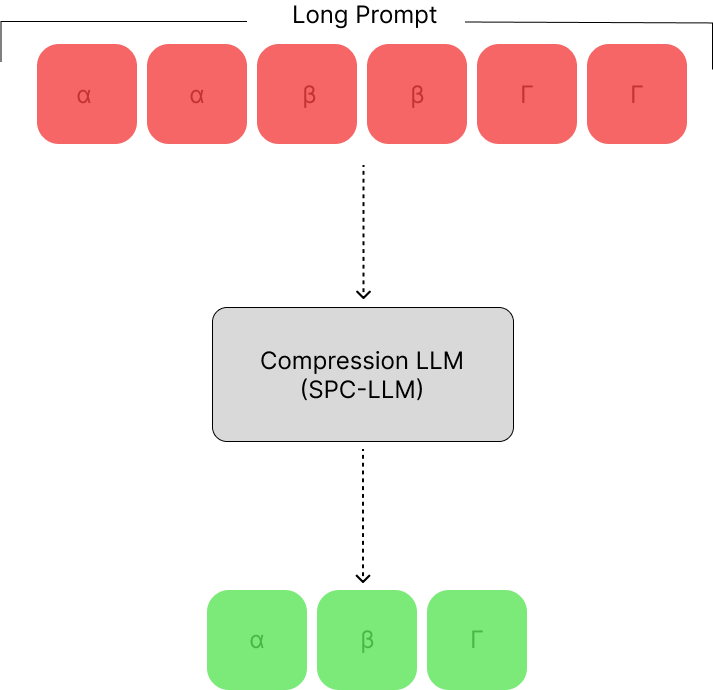
Large language models (LLMs) have triggered a new stream of research focusing on compressing the context length to reduce the computational cost while ensuring the retention of helpful information for LLMs to answer the given question. Token-based removal methods are one of the most prominent approaches in this direction, but risk losing the semantics of the context caused by intermediate token removal, especially under high compression ratios, while also facing challenges in computational efficiency. In this work, we propose context-aware prompt compression (CPC), a sentence-level prompt compression technique where its key innovation is a novel context-aware sentence encoder that provides a relevance score for each sentence for a given question. To train this encoder, we generate a new dataset consisting of questions, positives, and negative pairs where positives are sentences relevant to the question, while negatives are irrelevant context sentences. We train the encoder in a contrastive setup to learn context-aware sentence representations. Our method considerably outperforms prior works on prompt compression on benchmark datasets and is up to 10.93x faster at inference compared to the best token-level compression method. We also find better improvement for shorter length constraints in most benchmarks, showing the effectiveness of our proposed solution in the compression of relevant information in a shorter context. Finally, we release the code and the dataset for quick reproducibility and further development: https://github.com/Workday/cpc.
Read more9/5/2024
0
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Cangqing Wang, Yutian Yang, Ruisi Li, Dan Sun, Ruicong Cai, Yuzhu Zhang, Chengqian Fu, Lillian Floyd
The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
Read more4/22/2024

0
Characterizing Prompt Compression Methods for Long Context Inference
Siddharth Jha, Lutfi Eren Erdogan, Sehoon Kim, Kurt Keutzer, Amir Gholami
Long context inference presents challenges at the system level with increased compute and memory requirements, as well as from an accuracy perspective in being able to reason over long contexts. Recently, several methods have been proposed to compress the prompt to reduce the context length. However, there has been little work on comparing the different proposed methods across different tasks through a standardized analysis. This has led to conflicting results. To address this, here we perform a comprehensive characterization and evaluation of different prompt compression methods. In particular, we analyze extractive compression, summarization-based abstractive compression, and token pruning methods. Surprisingly, we find that extractive compression often outperforms all the other approaches, and enables up to 10x compression with minimal accuracy degradation. Interestingly, we also find that despite several recent claims, token pruning methods often lag behind extractive compression. We only found marginal improvements on summarization tasks.
Read more7/15/2024
0
Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
Haowen Hou, Fei Ma, Binwen Bai, Xinxin Zhu, Fei Yu
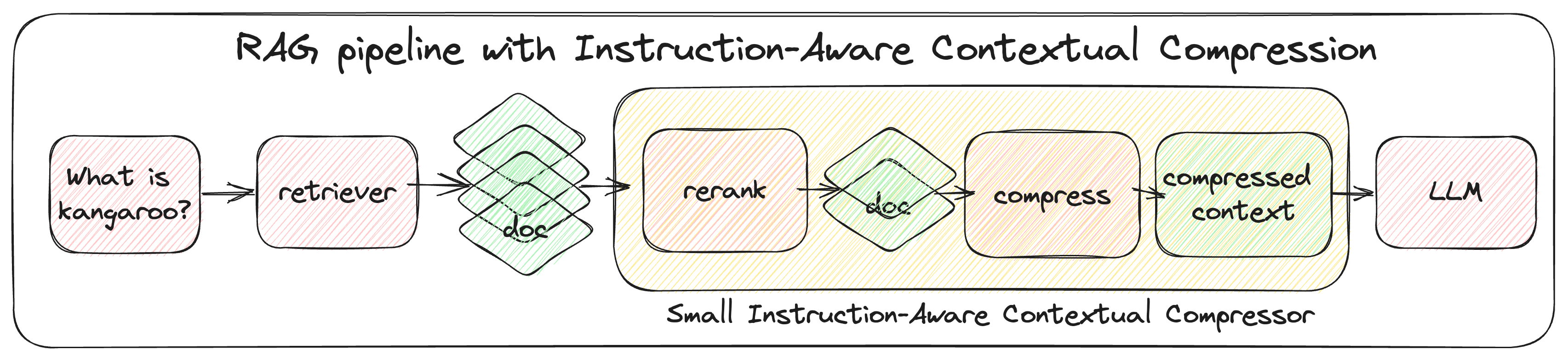
Large Language Models (LLMs) have garnered widespread attention due to their remarkable performance across various tasks. However, to mitigate the issue of hallucinations, LLMs often incorporate retrieval-augmented pipeline to provide them with rich external knowledge and context. Nevertheless, challenges stem from inaccurate and coarse-grained context retrieved from the retriever. Supplying irrelevant context to the LLMs can result in poorer responses, increased inference latency, and higher costs. This paper introduces a method called Instruction-Aware Contextual Compression, which filters out less informative content, thereby accelerating and enhancing the use of LLMs. The experimental results demonstrate that Instruction-Aware Contextual Compression notably reduces memory consumption and minimizes generation latency while maintaining performance levels comparable to those achieved with the use of the full context. Specifically, we achieved a 50% reduction in context-related costs, resulting in a 5% reduction in inference memory usage and a 2.2-fold increase in inference speed, with only a minor drop of 0.047 in Rouge-1. These findings suggest that our method strikes an effective balance between efficiency and performance.
Read more8/29/2024