Prompt-Guided Image-Adaptive Neural Implicit Lookup Tables for Interpretable Image Enhancement

0
Sign in to get full access
Overview
- The paper proposes a novel image enhancement technique using prompt-guided, image-adaptive neural implicit lookup tables.
- This approach aims to provide interpretable and controllable image enhancement by leveraging language guidance and implicit neural representations.
- The method adaptively learns lookup tables for each image, guided by text prompts, to enable fine-grained control and interpretability of the enhancement process.
Plain English Explanation
The paper introduces a new way to enhance images, or make them look better, using language-based guidance. The key idea is to create a special kind of "lookup table" - a collection of values that can be used to transform the image - that is tailored to each individual image and guided by text prompts.
Traditionally, image enhancement techniques have been hard to control and understand. This new approach tries to address that by letting you guide the enhancement process using language. You provide a text prompt describing the changes you want, like "make the colors more vibrant" or "sharpen the details", and the system learns a custom lookup table for that specific image to achieve the desired effect.
The lookup table is encoded using a neural network, which allows it to be very flexible and adaptive to each image. This is crucial for getting great results, since different images may need very different enhancements. By linking the language prompts to the learned lookup table, the process becomes more interpretable - you can understand how the text guidance is being applied to modify the image.
Technical Explanation
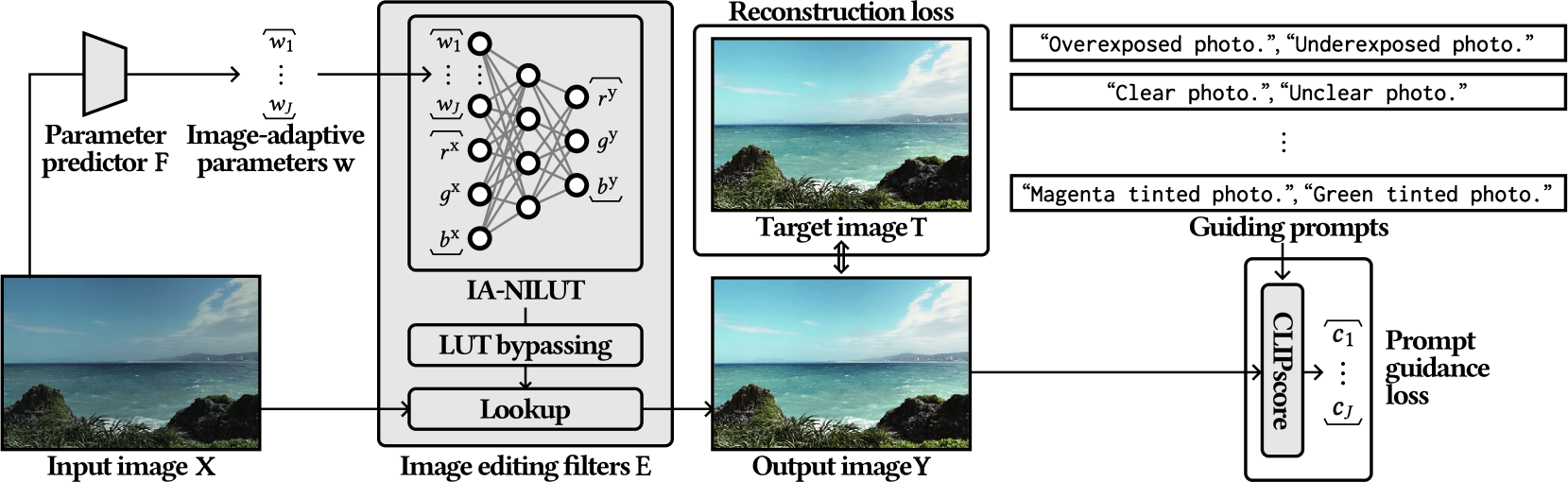
The paper introduces a [object Object] technique for interpretable image enhancement. The key innovation is the use of language-based prompts to guide the learning of a custom, image-specific neural implicit lookup table for each input image.
The system first encodes the input image and the text prompt using pre-trained [object Object] like CLIP. It then learns a neural implicit representation of a lookup table that maps the image features to the desired enhancement. This lookup table is trained to be sensitive to the prompt, allowing fine-grained control over the enhancement process.
During inference, the system applies the learned lookup table to the input image to produce the enhanced output. Crucially, the interpretable nature of the lookup table allows users to understand how the language guidance is being translated into specific image modifications, providing transparency and control.
The paper evaluates the approach on various image enhancement tasks, demonstrating improvements in both objective metrics and human evaluation of the results. The [object Object] of the lookup tables is shown to enable more flexible and controllable enhancement compared to existing techniques.
Critical Analysis
The paper presents a novel and promising approach to interpretable image enhancement. The key strengths are the ability to learn customized lookup tables for each image, guided by language prompts, and the inherent interpretability of the lookup table mechanism.
However, the paper does not fully address potential limitations and avenues for future research. For example, the computational efficiency of the lookup table learning process is not thoroughly explored, which could be a concern for real-world applications. Additionally, the paper does not discuss the robustness of the approach to diverse or challenging image enhancement scenarios, such as handling complex lighting conditions or artifacts.
[object Object] could explore techniques to make the lookup table learning more efficient, investigate the generalization capabilities of the approach, and consider ways to incorporate additional forms of guidance (e.g., user interactions) to enhance the interpretability and control of the image enhancement process.
Conclusion
The proposed [object Object] technique represents an innovative approach to interpretable image enhancement. By leveraging language-based prompts to guide the learning of custom, image-specific lookup tables, the method provides a flexible and controllable way to enhance images while maintaining transparency and understanding of the enhancement process.
The paper demonstrates promising results and opens up avenues for further research in the intersection of vision, language, and interpretable machine learning. As AI-powered image enhancement becomes more prevalent, approaches like this that prioritize user control and understanding will be increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt-Guided Image-Adaptive Neural Implicit Lookup Tables for Interpretable Image Enhancement
Satoshi Kosugi
In this paper, we delve into the concept of interpretable image enhancement, a technique that enhances image quality by adjusting filter parameters with easily understandable names such as Exposure and Contrast. Unlike using predefined image editing filters, our framework utilizes learnable filters that acquire interpretable names through training. Our contribution is two-fold. Firstly, we introduce a novel filter architecture called an image-adaptive neural implicit lookup table, which uses a multilayer perceptron to implicitly define the transformation from input feature space to output color space. By incorporating image-adaptive parameters directly into the input features, we achieve highly expressive filters. Secondly, we introduce a prompt guidance loss to assign interpretable names to each filter. We evaluate visual impressions of enhancement results, such as exposure and contrast, using a vision and language model along with guiding prompts. We define a constraint to ensure that each filter affects only the targeted visual impression without influencing other attributes, which allows us to obtain the desired filter effects. Experimental results show that our method outperforms existing predefined filter-based methods, thanks to the filters optimized to predict target results. Our source code is available at https://github.com/satoshi-kosugi/PG-IA-NILUT.
Read more8/21/2024
🧠
0
Neural Additive Image Model: Interpretation through Interpolation
Arik Reuter, Anton Thielmann, Benjamin Saefken
Understanding how images influence the world, interpreting which effects their semantics have on various quantities and exploring the reasons behind changes in image-based predictions are highly difficult yet extremely interesting problems. By adopting a holistic modeling approach utilizing Neural Additive Models in combination with Diffusion Autoencoders, we can effectively identify the latent hidden semantics of image effects and achieve full intelligibility of additional tabular effects. Our approach offers a high degree of flexibility, empowering us to comprehensively explore the impact of various image characteristics. We demonstrate that the proposed method can precisely identify complex image effects in an ablation study. To further showcase the practical applicability of our proposed model, we conduct a case study in which we investigate how the distinctive features and attributes captured within host images exert influence on the pricing of Airbnb rentals.
Read more5/7/2024
🌿
0
Adversarial Prompt Tuning for Vision-Language Models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, Jitao Sang
With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities. However, these models remain vulnerable to adversarial attacks, particularly in the image modality, presenting considerable security risks. This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs. AdvPT innovatively leverages learnable text prompts and aligns them with adversarial image embeddings, to address the vulnerabilities inherent in VLMs without the need for extensive parameter training or modification of the model architecture. We demonstrate that AdvPT improves resistance against white-box and black-box adversarial attacks and exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting defensive capabilities. Comprehensive experimental analyses provide insights into adversarial prompt tuning, a novel paradigm devoted to improving resistance to adversarial images through textual input modifications, paving the way for future robust multimodal learning research. These findings open up new possibilities for enhancing the security of VLMs. Our code is available at https://github.com/jiamingzhang94/Adversarial-Prompt-Tuning.
Read more8/20/2024

0
IntCoOp: Interpretability-Aware Vision-Language Prompt Tuning
Soumya Suvra Ghosal, Samyadeep Basu, Soheil Feizi, Dinesh Manocha
Image-text contrastive models such as CLIP learn transferable and robust representations for zero-shot transfer to a variety of downstream tasks. However, to obtain strong downstream performances, prompts need to be carefully curated, which can be a tedious engineering task. To address the issue of manual prompt engineering, prompt-tuning is used where a set of contextual vectors are learned by leveraging information from the training data. Despite their effectiveness, existing prompt-tuning frameworks often lack interpretability, thus limiting their ability to understand the compositional nature of images. In this work, we first identify that incorporating compositional attributes (e.g., a green tree frog) in the design of manual prompts can significantly enhance image-text alignment scores. Building upon this observation, we propose a novel and interpretable prompt-tuning method named IntCoOp, which learns to jointly align attribute-level inductive biases and class embeddings during prompt-tuning. To assess the effectiveness of our approach, we evaluate IntCoOp across two representative tasks in a few-shot learning setup: generalization to novel classes, and unseen domain shifts. Through extensive experiments across 10 downstream datasets on CLIP, we find that introducing attribute-level inductive biases leads to superior performance against state-of-the-art prompt tuning frameworks. Notably, in a 16-shot setup, IntCoOp improves CoOp by 7.35% in average performance across 10 diverse datasets.
Read more6/21/2024