Prompt Obfuscation for Large Language Models

0
💬
Sign in to get full access
Overview
- Prompt obfuscation aims to protect the intellectual property (IP) of prompts used to elicit desired outputs from large language models (LLMs).
- This approach can help preserve the value of prompts as a key innovation in the field of AI.
- The paper explores techniques for obfuscating prompts to prevent unauthorized use or extraction.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text. Developers often create specific "prompts" - carefully crafted input text - to elicit certain types of responses from these models. These prompts can be valuable intellectual property (IP), representing innovative work by the prompt's creator.
Prompt obfuscation is a technique to protect this IP by making the prompts difficult to reverse-engineer or replicate. The researchers explore ways to obscure the prompts, such as adding irrelevant text, using ambiguous language, or splitting the prompt across multiple inputs. This can prevent others from easily extracting and reusing the prompt's core innovative elements.
By obfuscating prompts, the creators can maintain control over their valuable IP and avoid having their hard work exploited by others. This helps preserve the incentive to invest in developing high-quality prompts, which are a key part of the AI innovation ecosystem.
Technical Explanation
The paper proposes several prompt obfuscation techniques to protect the intellectual property (IP) of prompts used with large language models (LLMs):
-
Prompt Padding: Adding irrelevant text to the beginning and/or end of the prompt to obscure its core components.
-
Prompt Splitting: Dividing the prompt across multiple input sequences, making it harder to extract the complete prompt.
-
Prompt Ambiguation: Using ambiguous or vague language in the prompt to reduce the likelihood of it being replicated exactly.
The researchers evaluate these techniques through a series of experiments, testing their effectiveness at preventing prompt extraction and the impact on model performance. They find that obfuscation can significantly impede the ability to reverse-engineer prompts while maintaining reasonable model outputs.
Critical Analysis
The paper provides a valuable exploration of prompt obfuscation techniques to protect the intellectual property of prompt creators. By making prompts more difficult to extract and replicate, this approach can help preserve the incentive to invest in innovative prompt development.
However, the researchers acknowledge that these techniques may come with some tradeoffs, such as reduced model performance or increased computational costs. Further research is needed to optimize the balance between protection and performance.
Additionally, the paper does not address the broader ethical implications of prompt obfuscation. While protecting IP is important, there are concerns about the opaqueness of LLM systems and the potential for abuse. Careful consideration of the societal impacts is crucial as these technologies continue to advance.
Conclusion
This paper presents prompt obfuscation as a promising approach to safeguard the intellectual property of prompts used with large language models. By obscuring the core elements of prompts, creators can maintain control over their valuable innovations and continue to drive progress in the field of AI. However, further research is needed to address the potential tradeoffs and broader ethical considerations surrounding the use of these techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Prompt Obfuscation for Large Language Models
David Pape, Thorsten Eisenhofer, Lea Schonherr
System prompts that include detailed instructions to describe the task performed by the underlying large language model (LLM) can easily transform foundation models into tools and services with minimal overhead. Because of their crucial impact on the utility, they are often considered intellectual property, similar to the code of a software product. However, extracting system prompts is easily possible by using prompt injection. As of today, there is no effective countermeasure to prevent the stealing of system prompts and all safeguarding efforts could be evaded with carefully crafted prompt injections that bypass all protection mechanisms. In this work, we propose an alternative to conventional system prompts. We introduce prompt obfuscation to prevent the extraction of the system prompt while maintaining the utility of the system itself with only little overhead. The core idea is to find a representation of the original system prompt that leads to the same functionality, while the obfuscated system prompt does not contain any information that allows conclusions to be drawn about the original system prompt. We implement an optimization-based method to find an obfuscated prompt representation while maintaining the functionality. To evaluate our approach, we investigate eight different metrics to compare the performance of a system using the original and the obfuscated system prompts, and we show that the obfuscated version is constantly on par with the original one. We further perform three different deobfuscation attacks and show that with access to the obfuscated prompt and the LLM itself, we are not able to consistently extract meaningful information. Overall, we showed that prompt obfuscation can be an effective method to protect intellectual property while maintaining the same utility as the original system prompt.
Read more9/23/2024

0
Knowledge Return Oriented Prompting (KROP)
Jason Martin, Kenneth Yeung
Many Large Language Models (LLMs) and LLM-powered apps deployed today use some form of prompt filter or alignment to protect their integrity. However, these measures aren't foolproof. This paper introduces KROP, a prompt injection technique capable of obfuscating prompt injection attacks, rendering them virtually undetectable to most of these security measures.
Read more6/19/2024
0
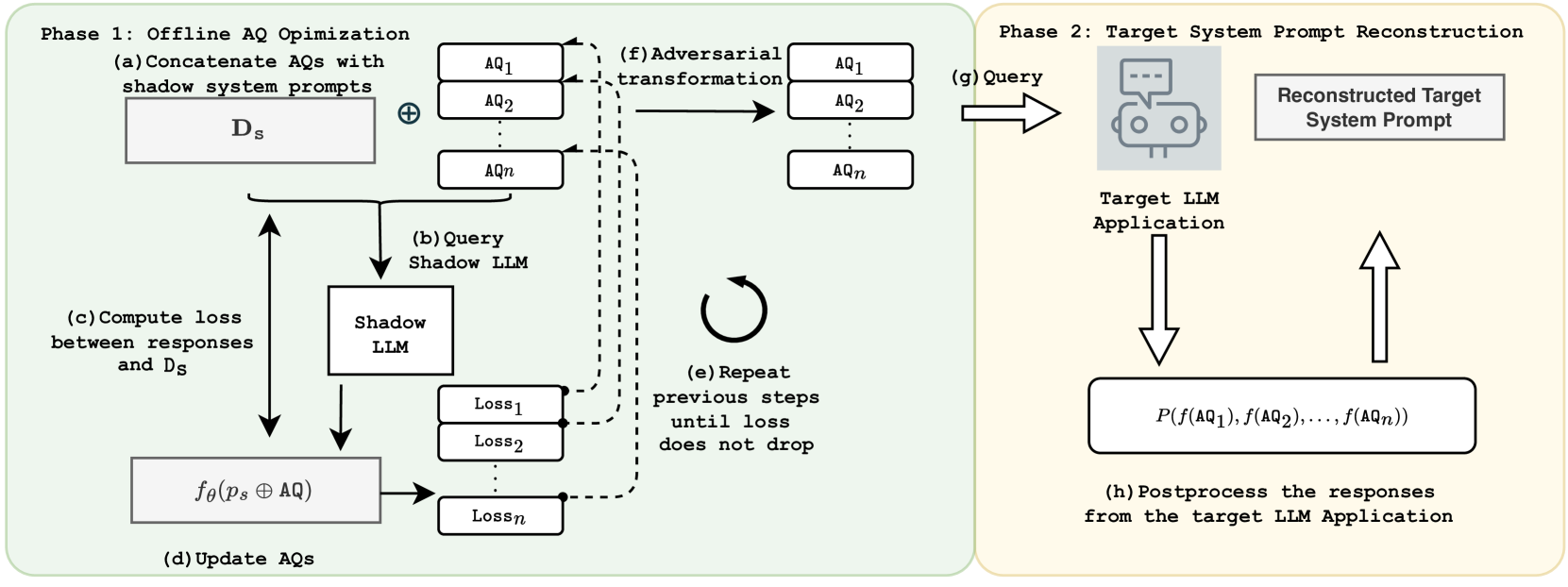
PLeak: Prompt Leaking Attacks against Large Language Model Applications
Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, Yinzhi Cao
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.
Read more5/15/2024

0
ObscurePrompt: Jailbreaking Large Language Models via Obscure Input
Yue Huang, Jingyu Tang, Dongping Chen, Bingda Tang, Yao Wan, Lichao Sun, Xiangliang Zhang
Recently, Large Language Models (LLMs) have garnered significant attention for their exceptional natural language processing capabilities. However, concerns about their trustworthiness remain unresolved, particularly in addressing jailbreaking attacks on aligned LLMs. Previous research predominantly relies on scenarios with white-box LLMs or specific and fixed prompt templates, which are often impractical and lack broad applicability. In this paper, we introduce a straightforward and novel method, named ObscurePrompt, for jailbreaking LLMs, inspired by the observed fragile alignments in Out-of-Distribution (OOD) data. Specifically, we first formulate the decision boundary in the jailbreaking process and then explore how obscure text affects LLM's ethical decision boundary. ObscurePrompt starts with constructing a base prompt that integrates well-known jailbreaking techniques. Powerful LLMs are then utilized to obscure the original prompt through iterative transformations, aiming to bolster the attack's robustness. Comprehensive experiments show that our approach substantially improves upon previous methods in terms of attack effectiveness, maintaining efficacy against two prevalent defense mechanisms. We believe that our work can offer fresh insights for future research on enhancing LLM alignment.
Read more6/21/2024