ProtoArgNet: Interpretable Image Classification with Super-Prototypes and Argumentation [Technical Report]

0
🖼️
Sign in to get full access
Overview
- ProtoArgNet is a novel deep neural architecture for image classification
- It builds on the prototypical-part-learning approach of ProtoPNet
- Instead of multiple prototypes per class, ProtoArgNet uses "super-prototypes" that combine prototypical parts
- This allows it to learn spatial relationships between prototypes
- ProtoArgNet can provide both supporting ("this looks like that") and attacking ("this differs from that") explanations for its classifications
Plain English Explanation
ProtoArgNet is a new type of deep learning model for classifying images. It's designed to be more interpretable than standard black-box models.
The key idea is that the model learns "prototypical parts" that represent important visual features for each class. For example, if classifying dogs, the model might learn prototypes for ears, paws, etc. Earlier approaches used multiple prototypes per class, but ProtoArgNet combines these into a single "super-prototype" for each class.
This super-prototype represents how the different prototypical parts fit together spatially. The model can then use these super-prototypes to not only classify images, but also explain its reasoning. It can say "this image looks like a dog because I see prototypical dog ears, paws, etc. arranged in the right way." It can also point out ways the image differs from the prototype, providing a more nuanced explanation.
Technical Explanation
ProtoArgNet builds on the prototypical-part-learning approach of ProtoPNet. However, instead of associating each class with multiple prototypical parts, ProtoArgNet uses "super-prototypes" that combine these parts into a unified class representation.
This is achieved by passing the local activations of the prototypes through an MLP-like module that learns the spatial relationships between them. This allows ProtoArgNet to not only localize the prototypes within an image, but also understand how they relate to each other.
ProtoArgNet can then leverage this understanding to provide both supporting ("this looks like that") and attacking ("this differs from that") explanations for its classifications. This "argumentation" component is customizable, allowing the model to generate more compact explanations by selectively removing less relevant information.
Critical Analysis
The authors demonstrate that ProtoArgNet outperforms state-of-the-art prototypical-part-learning approaches on several datasets. However, the paper does not address potential limitations or areas for further research.
One concern is the scalability of the model as the number of classes and prototypical parts grows. The complexity of the spatial reasoning required for the super-prototypes may become unwieldy. Additionally, the customizable "argumentation" component could introduce additional hyperparameters that require careful tuning.
Further research could explore ways to make the model more efficient, both in terms of computational resources and the size of the explanations generated. Applying ProtoArgNet to more diverse datasets and real-world applications would also help validate its practical utility.
Conclusion
ProtoArgNet is a promising step towards more interpretable and explainable deep learning models for image classification. By learning super-prototypes that capture the spatial relationships between prototypical parts, the model can provide nuanced explanations for its decisions.
If further developed and refined, this approach could lead to AI systems that are more transparent and trustworthy, particularly in high-stakes domains. However, more research is needed to address potential scalability and efficiency concerns. As always, it's important to consider the broader implications and potential pitfalls of such technologies as they advance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
ProtoArgNet: Interpretable Image Classification with Super-Prototypes and Argumentation [Technical Report]
Hamed Ayoobi, Nico Potyka, Francesca Toni
We propose ProtoArgNet, a novel interpretable deep neural architecture for image classification in the spirit of prototypical-part-learning as found, e.g., in ProtoPNet. While earlier approaches associate every class with multiple prototypical-parts, ProtoArgNet uses super-prototypes that combine prototypical-parts into a unified class representation. This is done by combining local activations of prototypes in an MLP-like manner, enabling the localization of prototypes and learning (non-linear) spatial relationships among them. By leveraging a form of argumentation, ProtoArgNet is capable of providing both supporting (i.e. `this looks like that') and attacking (i.e. `this differs from that') explanations. We demonstrate on several datasets that ProtoArgNet outperforms state-of-the-art prototypical-part-learning approaches. Moreover, the argumentation component in ProtoArgNet is customisable to the user's cognitive requirements by a process of sparsification, which leads to more compact explanations compared to state-of-the-art approaches.
Read more8/23/2024
🖼️
0
Deformable ProtoPNet: An Interpretable Image Classifier Using Deformable Prototypes
Jon Donnelly, Alina Jade Barnett, Chaofan Chen
We present a deformable prototypical part network (Deformable ProtoPNet), an interpretable image classifier that integrates the power of deep learning and the interpretability of case-based reasoning. This model classifies input images by comparing them with prototypes learned during training, yielding explanations in the form of this looks like that. However, while previous methods use spatially rigid prototypes, we address this shortcoming by proposing spatially flexible prototypes. Each prototype is made up of several prototypical parts that adaptively change their relative spatial positions depending on the input image. Consequently, a Deformable ProtoPNet can explicitly capture pose variations and context, improving both model accuracy and the richness of explanations provided. Compared to other case-based interpretable models using prototypes, our approach achieves state-of-the-art accuracy and gives an explanation with greater context. The code is available at https://github.com/jdonnelly36/Deformable-ProtoPNet.
Read more5/6/2024

0
This Looks Better than That: Better Interpretable Models with ProtoPNeXt
Frank Willard, Luke Moffett, Emmanuel Mokel, Jon Donnelly, Stark Guo, Julia Yang, Giyoung Kim, Alina Jade Barnett, Cynthia Rudin
Prototypical-part models are a popular interpretable alternative to black-box deep learning models for computer vision. However, they are difficult to train, with high sensitivity to hyperparameter tuning, inhibiting their application to new datasets and our understanding of which methods truly improve their performance. To facilitate the careful study of prototypical-part networks (ProtoPNets), we create a new framework for integrating components of prototypical-part models -- ProtoPNeXt. Using ProtoPNeXt, we show that applying Bayesian hyperparameter tuning and an angular prototype similarity metric to the original ProtoPNet is sufficient to produce new state-of-the-art accuracy for prototypical-part models on CUB-200 across multiple backbones. We further deploy this framework to jointly optimize for accuracy and prototype interpretability as measured by metrics included in ProtoPNeXt. Using the same resources, this produces models with substantially superior semantics and changes in accuracy between +1.3% and -1.5%. The code and trained models will be made publicly available upon publication.
Read more6/24/2024
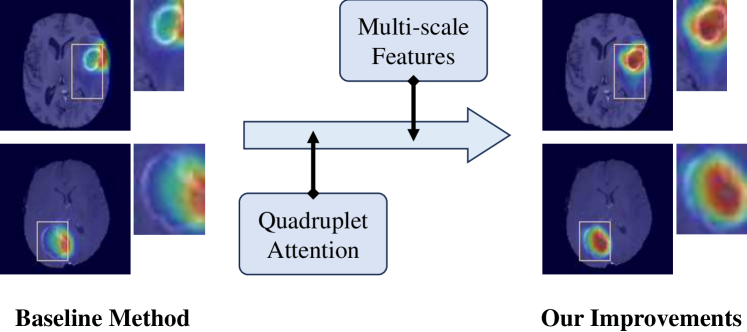
0
MAProtoNet: A Multi-scale Attentive Interpretable Prototypical Part Network for 3D Magnetic Resonance Imaging Brain Tumor Classification
Binghua Li, Jie Mao, Zhe Sun, Chao Li, Qibin Zhao, Toshihisa Tanaka
Automated diagnosis with artificial intelligence has emerged as a promising area in the realm of medical imaging, while the interpretability of the introduced deep neural networks still remains an urgent concern. Although contemporary works, such as XProtoNet and MProtoNet, has sought to design interpretable prediction models for the issue, the localization precision of their resulting attribution maps can be further improved. To this end, we propose a Multi-scale Attentive Prototypical part Network, termed MAProtoNet, to provide more precise maps for attribution. Specifically, we introduce a concise multi-scale module to merge attentive features from quadruplet attention layers, and produces attribution maps. The proposed quadruplet attention layers can enhance the existing online class activation mapping loss via capturing interactions between the spatial and channel dimension, while the multi-scale module then fuses both fine-grained and coarse-grained information for precise maps generation. We also apply a novel multi-scale mapping loss for supervision on the proposed multi-scale module. Compared to existing interpretable prototypical part networks in medical imaging, MAProtoNet can achieve state-of-the-art performance in localization on brain tumor segmentation (BraTS) datasets, resulting in approximately 4% overall improvement on activation precision score (with a best score of 85.8%), without using additional annotated labels of segmentation. Our code will be released in https://github.com/TUAT-Novice/maprotonet.
Read more4/16/2024