ProtoSAM - One Shot Medical Image Segmentation With Foundational Models

0

Sign in to get full access
Overview
- This paper introduces ProtoSAM, a one-shot medical image segmentation model that leverages foundational models.
- ProtoSAM uses a Prototypical Network architecture to enable few-shot segmentation of medical images.
- The model is trained on a large corpus of medical images and can be quickly fine-tuned to segment new medical images with just a single annotated example.
Plain English Explanation
ProtoSAM is a new deep learning model for medical image segmentation that can work with just a single labeled example. This is known as "one-shot" or "few-shot" learning, and it's useful because it can save a lot of time and effort compared to training a model from scratch.
The key idea behind ProtoSAM is to first train it on a large dataset of medical images using a technique called "self-supervised learning." This helps the model learn general visual features that are useful for medical image analysis, without needing extensive human labeling. Then, when you want to segment a new type of medical image, you can quickly fine-tune the model using just a single labeled example of that image type.
ProtoSAM uses a neural network architecture called a Prototypical Network to enable this one-shot learning capability. The model learns to represent each class of medical object (e.g., a brain tumor) as a "prototype" vector. Then, when you show it a new image, it can quickly compare that image to the prototypes and segment the relevant objects.
This one-shot segmentation approach is particularly useful for medical imaging, where obtaining large annotated datasets can be very challenging and expensive. By leveraging foundational models and few-shot learning, ProtoSAM makes medical image analysis more accessible and efficient.
Technical Explanation
ProtoSAM is built upon recent advancements in foundational models and few-shot learning for medical image analysis. The model uses a Prototypical Network architecture, which learns a representation of each class of medical object as a "prototype" vector.
To train ProtoSAM, the authors first pre-train the model on a large corpus of unannotated medical images using self-supervised learning. This allows the model to learn general visual features that are useful for medical image analysis. They then fine-tune the model on a few annotated examples of each target medical object class, enabling the model to learn the prototypes for those classes.
When presented with a new medical image, ProtoSAM can quickly segment the relevant objects by comparing the image features to the learned prototypes. This one-shot learning approach is facilitated by the Prototypical Network architecture, which is designed to enable efficient few-shot adaptation.
The authors evaluate ProtoSAM on several medical image segmentation benchmarks, demonstrating its ability to achieve strong performance using just a single annotated example per class. They also compare ProtoSAM to other few-shot learning approaches, showing that its prototypical learning approach is particularly well-suited for medical image segmentation tasks.
Critical Analysis
The authors provide a thorough evaluation of ProtoSAM, including comparisons to other few-shot learning methods for medical image segmentation. However, the paper could benefit from a more detailed discussion of the limitations and potential drawbacks of the approach.
For example, the authors do not address how ProtoSAM might perform on medical images with significant variations in imaging modality, resolution, or anatomical characteristics. Additionally, the paper does not explore the scalability of the approach as the number of target object classes increases.
Furthermore, the authors do not discuss potential ethical considerations, such as the implications of deploying a one-shot segmentation model in clinical settings where accurate and reliable segmentation is critical. Addressing these types of concerns would help readers better understand the real-world applicability and limitations of the ProtoSAM approach.
Overall, the paper presents a promising new technique for medical image segmentation, but a more critical analysis of the method's strengths, weaknesses, and potential risks would strengthen the contribution.
Conclusion
ProtoSAM is a novel one-shot medical image segmentation model that leverages foundational models and Prototypical Networks to enable efficient few-shot learning. By pre-training on large unannotated datasets and fine-tuning on just a single labeled example per class, ProtoSAM can quickly adapt to segment new medical images with high accuracy.
This approach has the potential to significantly reduce the time and effort required to develop medical image analysis tools, which is particularly important in healthcare settings where annotated data can be scarce. While the paper presents a thorough evaluation of ProtoSAM, a more critical analysis of the method's limitations and potential risks would help readers better understand its real-world applicability and implications.
Overall, ProtoSAM represents an exciting step forward in the field of medical image analysis, demonstrating the power of foundational models and few-shot learning to make medical imaging more accessible and efficient.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ProtoSAM - One Shot Medical Image Segmentation With Foundational Models
Lev Ayzenberg, Raja Giryes, Hayit Greenspan
This work introduces a new framework, ProtoSAM, for one-shot medical image segmentation. It combines the use of prototypical networks, known for few-shot segmentation, with SAM - a natural image foundation model. The method proposed creates an initial coarse segmentation mask using the ALPnet prototypical network, augmented with a DINOv2 encoder. Following the extraction of an initial mask, prompts are extracted, such as points and bounding boxes, which are then input into the Segment Anything Model (SAM). State-of-the-art results are shown on several medical image datasets and demonstrate automated segmentation capabilities using a single image example (one shot) with no need for fine-tuning of the foundation model. Our code is available at: https://github.com/levayz/ProtoSAM
Read more7/19/2024

0
Pathological Primitive Segmentation Based on Visual Foundation Model with Zero-Shot Mask Generation
Abu Bakor Hayat Arnob, Xiangxue Wang, Yiping Jiao, Xiao Gan, Wenlong Ming, Jun Xu
Medical image processing usually requires a model trained with carefully crafted datasets due to unique image characteristics and domain-specific challenges, especially in pathology. Primitive detection and segmentation in digitized tissue samples are essential for objective and automated diagnosis and prognosis of cancer. SAM (Segment Anything Model) has recently been developed to segment general objects from natural images with high accuracy, but it requires human prompts to generate masks. In this work, we present a novel approach that adapts pre-trained natural image encoders of SAM for detection-based region proposals. Regions proposed by a pre-trained encoder are sent to cascaded feature propagation layers for projection. Then, local semantic and global context is aggregated from multi-scale for bounding box localization and classification. Finally, the SAM decoder uses the identified bounding boxes as essential prompts to generate a comprehensive primitive segmentation map. The entire base framework, SAM, requires no additional training or fine-tuning but could produce an end-to-end result for two fundamental segmentation tasks in pathology. Our method compares with state-of-the-art models in F1 score for nuclei detection and binary/multiclass panoptic(bPQ/mPQ) and mask quality(dice) for segmentation quality on the PanNuke dataset while offering end-to-end efficiency. Our model also achieves remarkable Average Precision (+4.5%) on the secondary dataset (HuBMAP Kidney) compared to Faster RCNN. The code is publicly available at https://github.com/learner-codec/autoprom_sam.
Read more4/15/2024

0
SAM-UNet:Enhancing Zero-Shot Segmentation of SAM for Universal Medical Images
Sihan Yang, Haixia Bi, Hai Zhang, Jian Sun
Segment Anything Model (SAM) has demonstrated impressive performance on a wide range of natural image segmentation tasks. However, its performance significantly deteriorates when directly applied to medical domain, due to the remarkable differences between natural images and medical images. Some researchers have attempted to train SAM on large scale medical datasets. However, poor zero-shot performance is observed from the experimental results. In this context, inspired by the superior performance of U-Net-like models in medical image segmentation, we propose SAMUNet, a new foundation model which incorporates U-Net to the original SAM, to fully leverage the powerful contextual modeling ability of convolutions. To be specific, we parallel a convolutional branch in the image encoder, which is trained independently with the vision Transformer branch frozen. Additionally, we employ multi-scale fusion in the mask decoder, to facilitate accurate segmentation of objects with different scales. We train SAM-UNet on SA-Med2D-16M, the largest 2-dimensional medical image segmentation dataset to date, yielding a universal pretrained model for medical images. Extensive experiments are conducted to evaluate the performance of the model, and state-of-the-art result is achieved, with a dice similarity coefficient score of 0.883 on SA-Med2D-16M dataset. Specifically, in zero-shot segmentation experiments, our model not only significantly outperforms previous large medical SAM models across all modalities, but also substantially mitigates the performance degradation seen on unseen modalities. It should be highlighted that SAM-UNet is an efficient and extensible foundation model, which can be further fine-tuned for other downstream tasks in medical community. The code is available at https://github.com/Hhankyangg/sam-unet.
Read more8/20/2024
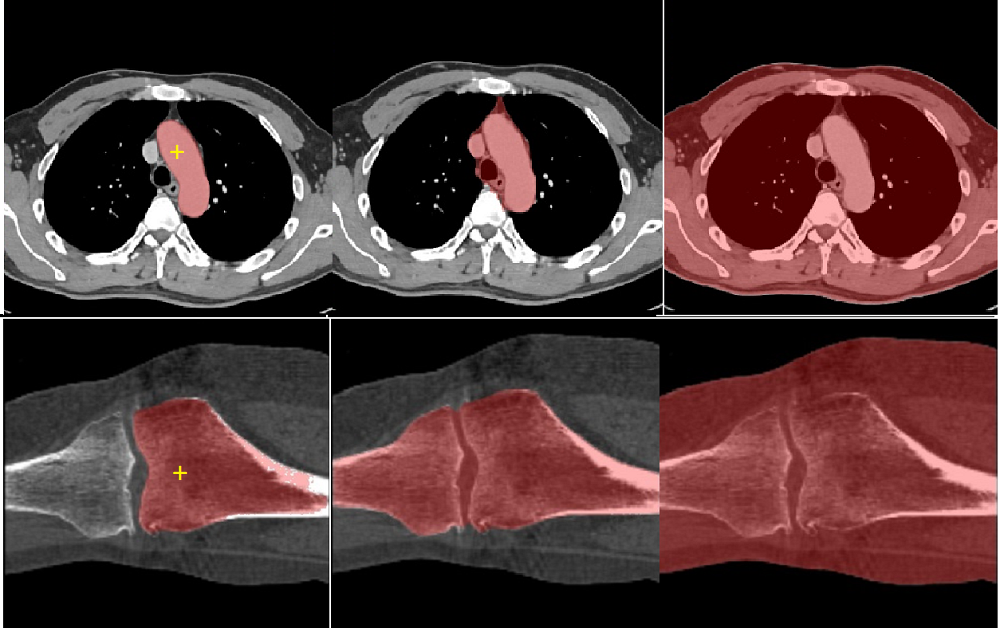
0
SAM Fewshot Finetuning for Anatomical Segmentation in Medical Images
Weiyi Xie, Nathalie Willems, Shubham Patil, Yang Li, Mayank Kumar
We propose a straightforward yet highly effective few-shot fine-tuning strategy for adapting the Segment Anything (SAM) to anatomical segmentation tasks in medical images. Our novel approach revolves around reformulating the mask decoder within SAM, leveraging few-shot embeddings derived from a limited set of labeled images (few-shot collection) as prompts for querying anatomical objects captured in image embeddings. This innovative reformulation greatly reduces the need for time-consuming online user interactions for labeling volumetric images, such as exhaustively marking points and bounding boxes to provide prompts slice by slice. With our method, users can manually segment a few 2D slices offline, and the embeddings of these annotated image regions serve as effective prompts for online segmentation tasks. Our method prioritizes the efficiency of the fine-tuning process by exclusively training the mask decoder through caching mechanisms while keeping the image encoder frozen. Importantly, this approach is not limited to volumetric medical images, but can generically be applied to any 2D/3D segmentation task. To thoroughly evaluate our method, we conducted extensive validation on four datasets, covering six anatomical segmentation tasks across two modalities. Furthermore, we conducted a comparative analysis of different prompting options within SAM and the fully-supervised nnU-Net. The results demonstrate the superior performance of our method compared to SAM employing only point prompts (approximately 50% improvement in IoU) and performs on-par with fully supervised methods whilst reducing the requirement of labeled data by at least an order of magnitude.
Read more7/8/2024