ProTrain: Efficient LLM Training via Memory-Aware Techniques
2406.08334
0
0

Abstract
It is extremely memory-hungry to train Large Language Models (LLM). To solve this problem, existing work exploits the combination of CPU and GPU for the training process, such as ZeRO-Offload. Such a technique largely democratizes billion-scale model training, making it possible to train with few consumer graphics cards. However, based on our observation, existing frameworks often provide coarse-grained memory management and require experienced experts in configuration tuning, leading to suboptimal hardware utilization and performance. This paper proposes ProTrain, a novel training system that intelligently balances memory usage and performance by coordinating memory, computation, and IO. ProTrain achieves adaptive memory management through Chunk-Based Model State Management and Block-Wise Activation Management, guided by a Memory-Aware Runtime Profiler without user intervention. ProTrain does not change the training algorithm and thus does not compromise accuracy. Experiments show that ProTrain improves training throughput by 1.43$times$ to 2.71$times$ compared to the SOTA training systems.
Create account to get full access
Overview
• This paper introduces ProTrain, a novel memory management technique that can significantly improve the training efficiency of large language models (LLMs).
• ProTrain adaptively manages the memory usage during the training process, allowing for more efficient utilization of available resources and enabling the training of larger and more capable models.
• The proposed approach builds on previous memory-efficient training techniques like VELORA and GALORE, while introducing novel strategies to further optimize memory consumption.
Plain English Explanation
Training large language models (LLMs) is a computationally intensive process that requires a lot of memory. ProTrain is a new technique that can help make this training more efficient by adaptively managing the memory used during the training process.
The key idea behind ProTrain is to dynamically adjust the memory usage as the training progresses, rather than allocating a fixed amount of memory upfront. This allows the training to make more efficient use of the available resources, enabling the creation of larger and more capable models.
ProTrain builds on previous memory-efficient training techniques, such as VELORA and GALORE, but introduces additional strategies to further optimize memory consumption. By dynamically managing the memory, ProTrain can help train LLMs that would otherwise be too large to fit in the available memory.
Technical Explanation
The key components of ProTrain's memory management approach include:
-
Adaptive Memory Allocation: ProTrain dynamically allocates and deallocates memory during the training process, based on the current memory requirements. This allows the model to utilize memory more efficiently, compared to a fixed memory allocation strategy.
-
Selective Gradient Caching: ProTrain selectively caches gradients, only storing those that are necessary for the current training step. This reduces the overall memory footprint of the training process.
-
Activation Recomputation: ProTrain recomputes activations during the backward pass, rather than storing them during the forward pass. This trading of computation for memory usage can further optimize the memory consumption.
-
Gradient Checkpointing: ProTrain leverages gradient checkpointing techniques, similar to those used in HLAT, to reduce the memory required for storing intermediate activations during the training process.
The combination of these techniques allows ProTrain to train larger and more complex LLMs than would be possible with traditional memory management strategies, while still maintaining a high level of training efficiency.
Critical Analysis
The paper acknowledges that while ProTrain can significantly improve the memory efficiency of LLM training, there are still some limitations and areas for further research:
-
Computational Overhead: The dynamic memory management and selective gradient caching techniques introduced by ProTrain may incur additional computational overhead, which could impact the overall training speed. The authors note that this trade-off between memory efficiency and training time should be carefully evaluated.
-
Applicability to Different Model Architectures: The paper focuses on evaluating ProTrain with Transformer-based LLMs, but it is unclear how well the proposed techniques would perform with other model architectures, such as those explored in Energy Efficiency Limits of Training AI Systems Using DRAM.
-
Hardware Constraints: The benefits of ProTrain may be limited by the underlying hardware capabilities, particularly in scenarios with strict memory constraints, as discussed in the Device Training Under 256KB Memory paper.
Conclusion
The ProTrain framework represents a significant advancement in memory-efficient training of large language models. By dynamically managing memory usage and applying selective caching and recomputation techniques, ProTrain can enable the training of larger and more capable models than would be possible with traditional memory management strategies.
While the proposed techniques introduce some computational overhead, the overall improvements in memory efficiency can lead to significant gains in the scale and complexity of LLMs that can be trained. As the demand for more powerful language models continues to grow, techniques like ProTrain will play an increasingly important role in pushing the boundaries of what is possible in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LoongTrain: Efficient Training of Long-Sequence LLMs with Head-Context Parallelism
Diandian Gu, Peng Sun, Qinghao Hu, Ting Huang, Xun Chen, Yingtong Xiong, Guoteng Wang, Qiaoling Chen, Shangchun Zhao, Jiarui Fang, Yonggang Wen, Tianwei Zhang, Xin Jin, Xuanzhe Liu
0
0
Efficiently training LLMs with long sequences is important yet challenged by the massive computation and memory requirements. Sequence parallelism has been proposed to tackle these problems, but existing methods suffer from scalability or efficiency issues. We propose LoongTrain, a novel system to efficiently train LLMs with long sequences at scale. The core of LoongTrain is the 2D-Attention mechanism, which combines both head-parallel and context-parallel techniques to break the scalability constraints while maintaining efficiency. We introduce Double-Ring-Attention and analyze the performance of device placement strategies to further speed up training. We implement LoongTrain with the hybrid ZeRO and Selective Checkpoint++ techniques. Experiment results show that LoongTrain outperforms state-of-the-art baselines, i.e., DeepSpeed-Ulysses and Megatron Context Parallelism, in both end-to-end training speed and scalability, and improves Model FLOPs Utilization (MFU) by up to 2.88x.
6/27/2024
VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections
Roy Miles, Pradyumna Reddy, Ismail Elezi, Jiankang Deng
0
0
Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive. In this paper, we identify and characterise the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance. This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark. Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
5/29/2024

GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, Yuandong Tian
0
0
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
6/4/2024
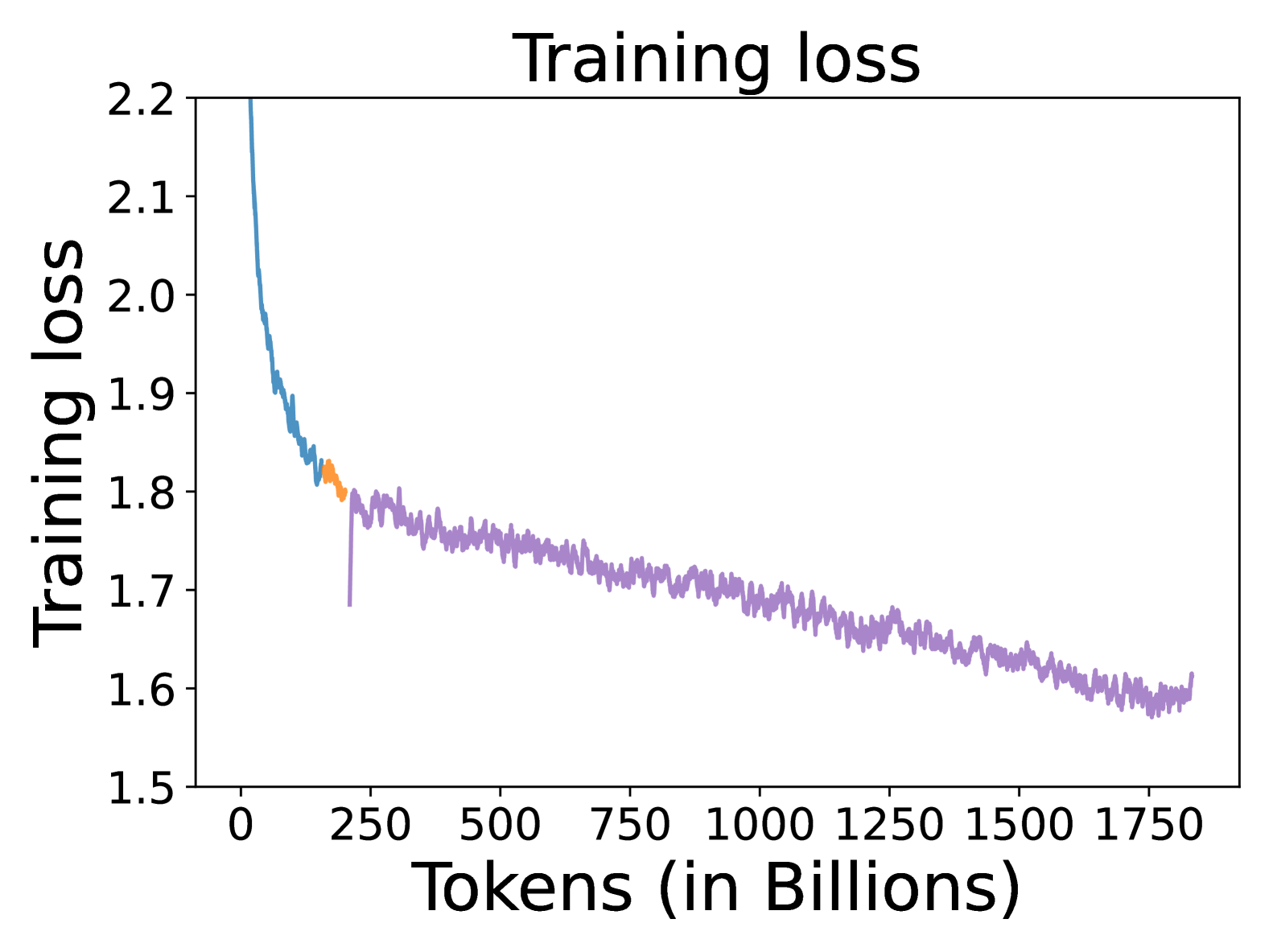
HLAT: High-quality Large Language Model Pre-trained on AWS Trainium
Haozheng Fan, Hao Zhou, Guangtai Huang, Parameswaran Raman, Xinwei Fu, Gaurav Gupta, Dhananjay Ram, Yida Wang, Jun Huan
0
0
Getting large language models (LLMs) to perform well on the downstream tasks requires pre-training over trillions of tokens. This typically demands a large number of powerful computational devices in addition to a stable distributed training framework to accelerate the training. The growing number of applications leveraging AI/ML had led to a scarcity of the expensive conventional accelerators (such as GPUs), which begs the need for the alternative specialized-accelerators that are scalable and cost-efficient. AWS Trainium is the second-generation machine learning accelerator that has been purposely built for training large deep learning models. Its corresponding instance, Amazon EC2 trn1, is an alternative to GPU instances for LLM training. However, training LLMs with billions of parameters on trn1 is challenging due to its relatively nascent software ecosystem. In this paper, we showcase HLAT: a 7 billion parameter decoder-only LLM pre-trained using trn1 instances over 1.8 trillion tokens. The performance of HLAT is benchmarked against popular open source baseline models including LLaMA and OpenLLaMA, which have been trained on NVIDIA GPUs and Google TPUs, respectively. On various evaluation tasks, we show that HLAT achieves model quality on par with the baselines. We also share the best practice of using the Neuron Distributed Training Library (NDTL), a customized distributed training library for AWS Trainium to achieve efficient training. Our work demonstrates that AWS Trainium powered by the NDTL is able to successfully pre-train state-of-the-art LLM models with high performance and cost-effectiveness.
4/17/2024