VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections
2405.17991
0
0
Abstract
Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive. In this paper, we identify and characterise the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance. This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark. Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
Create account to get full access
Overview
- Introduces VeLoRA, a memory-efficient training method using rank-1 sub-token projections
- Aims to reduce the memory footprint of large language models during fine-tuning
- Proposes a new parameter-efficient fine-tuning technique that can be applied to a wide range of models
Plain English Explanation
VeLoRA is a new technique that allows large language models to be fine-tuned more efficiently, using less memory. When training these models on a specific task, they often require a lot of computer memory, which can be a limitation. VeLoRA introduces a new way to fine-tune the models that reduces this memory requirement, making the process more practical and accessible.
The key idea behind VeLoRA is to use a special type of matrix projection called "rank-1 sub-token projections." This allows the model to learn the necessary changes for the new task using far fewer parameters than traditional fine-tuning methods. By reducing the memory footprint, VeLoRA makes it possible to fine-tune large language models on a wider range of hardware, opening up new applications and research possibilities.
Technical Explanation
VeLoRA is a novel parameter-efficient fine-tuning technique that uses rank-1 sub-token projections to reduce the memory requirements of large language model fine-tuning. Rather than updating all the model's parameters during fine-tuning, VeLoRA introduces a small number of additional parameters that can be learned efficiently.
The core of VeLoRA is the use of a rank-1 matrix to project the input token embeddings into a lower-dimensional space before feeding them into the model. This allows the model to learn task-specific adaptations without modifying the original model parameters. The rank-1 constraint ensures the additional parameters are memory-efficient, while still allowing the model to capture important task-specific information.
VeLoRA is evaluated on a range of language modeling benchmarks, demonstrating significant memory savings compared to standard fine-tuning approaches. The authors show that VeLoRA can achieve comparable performance to full fine-tuning while using less than 1% of the additional parameters.
Critical Analysis
The VeLoRA technique presents an interesting and promising approach to memory-efficient fine-tuning of large language models. By leveraging rank-1 sub-token projections, the method is able to significantly reduce the memory footprint of the fine-tuning process, which is a key limitation of traditional fine-tuning techniques.
However, the paper does not explore the potential limitations or failure modes of the VeLoRA approach. For example, it is unclear how the rank-1 constraint might impact the model's ability to capture complex task-specific adaptations, or how the method might scale to very large models or diverse task domains.
Additionally, while the authors demonstrate strong empirical results, the theoretical underpinnings of why rank-1 projections work well for this problem are not fully explored. A deeper analysis of the mathematical properties and inductive biases of this approach could provide additional insights.
Further research is needed to better understand the broader applicability and limitations of VeLoRA, as well as to explore potential extensions or alternative parameter-efficient fine-tuning techniques. Nonetheless, this work represents an important step forward in making large language models more accessible and practical for a wider range of applications.
Conclusion
VeLoRA introduces a novel memory-efficient fine-tuning technique for large language models, using rank-1 sub-token projections to significantly reduce the memory requirements of the fine-tuning process. By decreasing the number of additional parameters needed, VeLoRA makes it possible to fine-tune these powerful models on a wider range of hardware, opening up new research and application possibilities.
While further research is needed to fully understand the method's strengths and limitations, VeLoRA represents an important advancement in the field of parameter-efficient fine-tuning. This work has the potential to have a meaningful impact on the accessibility and practical deployment of large language models in a variety of real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, Yuandong Tian
0
0
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
6/4/2024
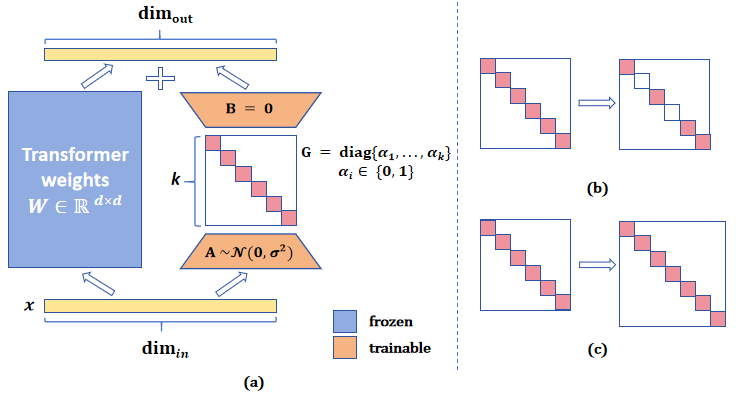
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
0
0
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
4/16/2024
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024

OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models
Kerim Buyukakyuz
0
0
The advent of large language models (LLMs) has revolutionized natural language processing, enabling unprecedented capabilities in understanding and generating human-like text. However, the computational cost and convergence times associated with fine-tuning these models remain significant challenges. Low-Rank Adaptation (LoRA) has emerged as a promising method to mitigate these issues by introducing efficient fine-tuning techniques with a reduced number of trainable parameters. In this paper, we present OLoRA, an enhancement to the LoRA method that leverages orthonormal matrix initialization through QR decomposition. OLoRA significantly accelerates the convergence of LLM training while preserving the efficiency benefits of LoRA, such as the number of trainable parameters and GPU memory footprint. Our empirical evaluations demonstrate that OLoRA not only converges faster but also exhibits improved performance compared to standard LoRA across a variety of language modeling tasks. This advancement opens new avenues for more efficient and accessible fine-tuning of LLMs, potentially enabling broader adoption and innovation in natural language applications.
6/5/2024