Provably Robust and Plausible Counterfactual Explanations for Neural Networks via Robust Optimisation
2309.12545
0
0
🧠
Abstract
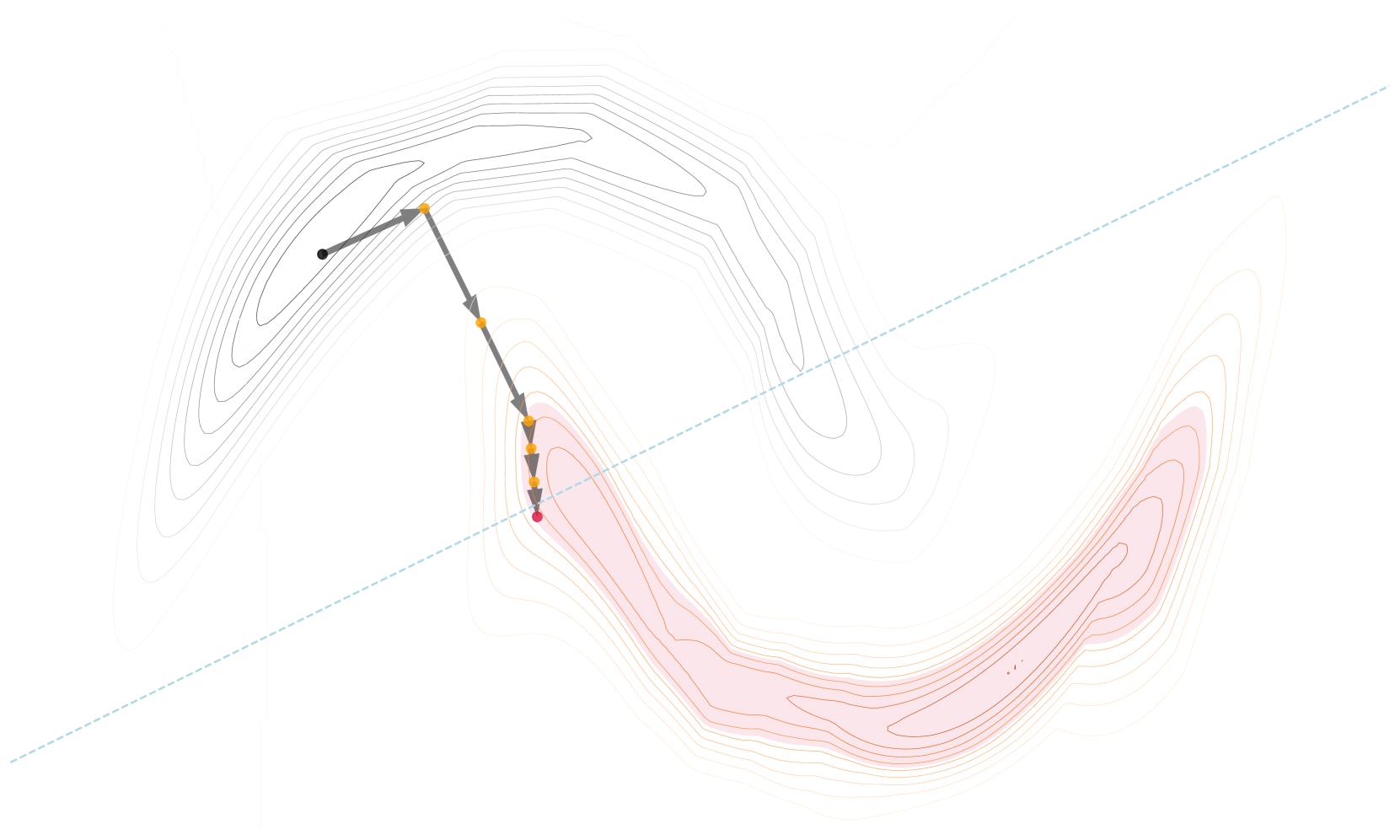
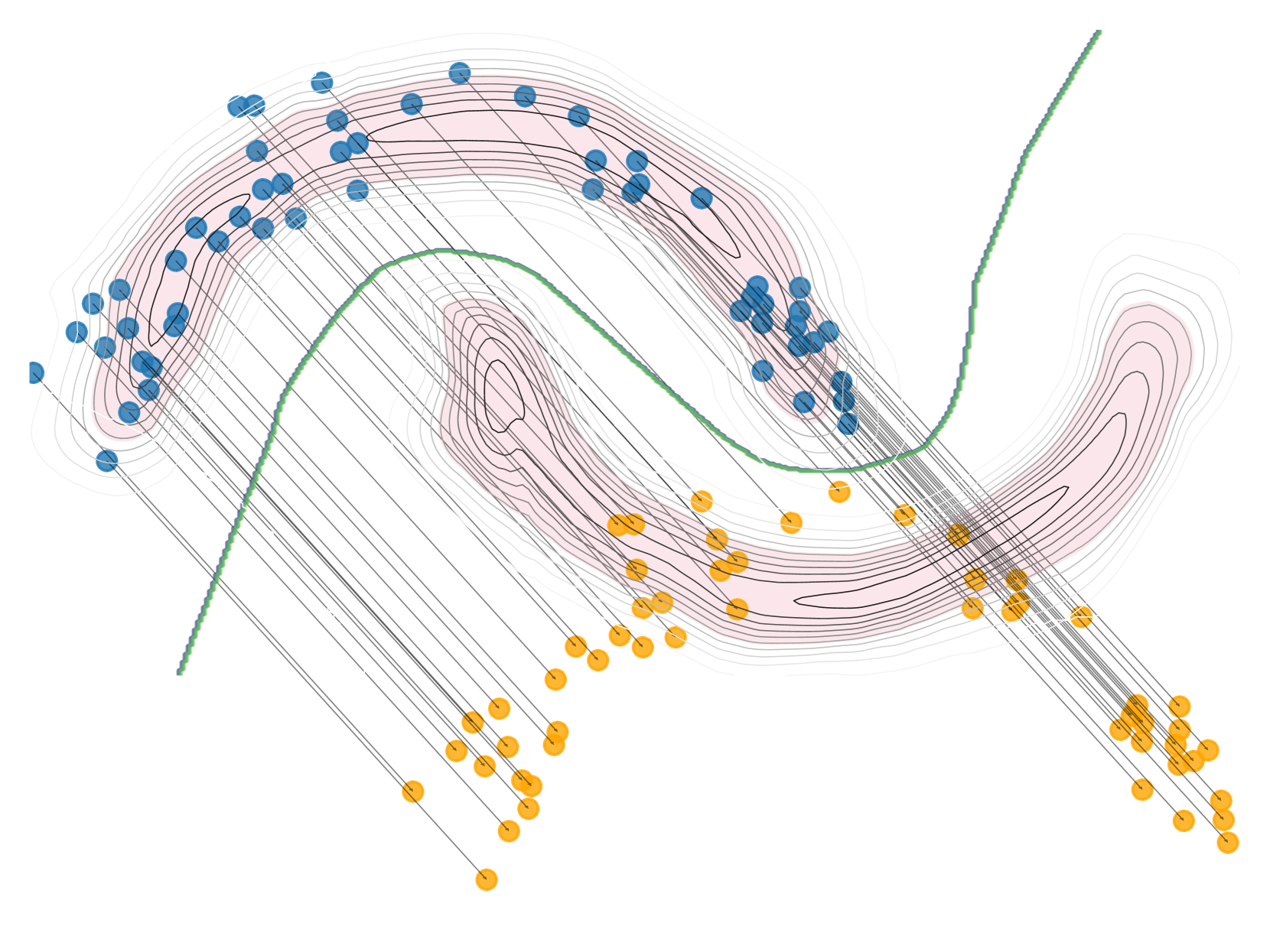
Counterfactual Explanations (CEs) have received increasing interest as a major methodology for explaining neural network classifiers. Usually, CEs for an input-output pair are defined as data points with minimum distance to the input that are classified with a different label than the output. To tackle the established problem that CEs are easily invalidated when model parameters are updated (e.g. retrained), studies have proposed ways to certify the robustness of CEs under model parameter changes bounded by a norm ball. However, existing methods targeting this form of robustness are not sound or complete, and they may generate implausible CEs, i.e., outliers wrt the training dataset. In fact, no existing method simultaneously optimises for closeness and plausibility while preserving robustness guarantees. In this work, we propose Provably RObust and PLAusible Counterfactual Explanations (PROPLACE), a method leveraging on robust optimisation techniques to address the aforementioned limitations in the literature. We formulate an iterative algorithm to compute provably robust CEs and prove its convergence, soundness and completeness. Through a comparative experiment involving six baselines, five of which target robustness, we show that PROPLACE achieves state-of-the-art performances against metrics on three evaluation aspects.
Create account to get full access
Overview
- This paper introduces a new method called PROPLACE (Provably RObust and PLAusible Counterfactual Explanations) for generating counterfactual explanations that are both close to the input and plausible with respect to the training data.
- Counterfactual explanations (CEs) are a way to explain the decisions of neural network classifiers by finding similar data points that are classified differently.
- However, existing methods for generating robust CEs that are resistant to changes in the model parameters have limitations in terms of producing implausible or outlier CEs.
- PROPLACE aims to address these limitations by leveraging robust optimization techniques to generate CEs that are both close to the input and plausible.
Plain English Explanation
Imagine you have a neural network that can classify images, like whether an image shows a cat or a dog. Counterfactual explanations (CEs) are a way to explain why the network made a particular classification. A CE would be an image that is very similar to the original, but is classified differently - for example, an image that the network thinks is a dog, but with small changes that make the network classify it as a cat.
The challenge is that as the neural network is updated or retrained, these CEs can become invalid - the network might no longer classify the CE the same way. Researchers have tried to solve this by generating CEs that are "robust" to changes in the model, but the CEs they produce can be very different from the original input and not plausible.
This paper introduces a new method called PROPLACE that can generate CEs that are both close to the original input and plausible (i.e., similar to the training data), while also being robust to changes in the model. The key idea is to use a technique called robust optimization to find these CEs. Through experiments, the researchers show that PROPLACE outperforms existing methods on several metrics for evaluating the quality of the CEs.
Technical Explanation
The paper proposes a new method called PROPLACE (Provably RObust and PLAusible Counterfactual Explanations) to generate counterfactual explanations (CEs) for neural network classifiers. CEs are defined as data points that are close to the input but classified differently by the model.
To address the problem of CEs becoming invalid when the model is updated, the authors formulate an optimization problem to find CEs that are both close to the input and plausible with respect to the training data, while also being provably robust to bounded changes in the model parameters. They leverage robust optimization techniques to solve this problem and prove the convergence, soundness, and completeness of their iterative algorithm.
Through comparative experiments involving six baselines, five of which target robustness, the authors demonstrate that PROPLACE achieves state-of-the-art performance on three evaluation metrics: closeness to the input, plausibility with respect to the training data, and robustness to parameter changes.
Critical Analysis
The authors acknowledge that while PROPLACE addresses the limitations of existing methods for generating robust and plausible CEs, there are still some potential caveats and areas for further research:
- The authors note that their method relies on the availability of a suitable distance metric and a reference model (e.g., the training data distribution) to assess plausibility. In practice, these may be difficult to obtain or define.
- The paper focuses on the binary classification setting, and it's unclear how well the method would generalize to multi-class problems or more complex model architectures.
- The computational cost of the iterative optimization algorithm used in PROPLACE may be a limitation, especially for large-scale applications.
Additionally, one could question whether the notion of "plausibility" used in this work is sufficient to ensure the generated CEs are truly meaningful and interpretable to human users. The paper does not address how the plausibility of CEs is perceived by end-users or domain experts.
Overall, the PROPLACE method represents a meaningful step forward in the quest for generating robust and plausible counterfactual explanations for neural network classifiers. However, further research is needed to address the practical challenges and expand the applicability of this approach.
Conclusion
This paper introduces a new method called PROPLACE that can generate counterfactual explanations (CEs) for neural network classifiers that are both close to the input and plausible with respect to the training data, while also being provably robust to changes in the model parameters.
The key innovation is the use of robust optimization techniques to solve an optimization problem that captures these desirable properties of CEs. Through experiments, the authors show that PROPLACE outperforms existing methods on several metrics for evaluating the quality of CEs.
While the paper addresses important limitations of prior work, there are still some practical challenges and open questions that require further research. Nonetheless, PROPLACE represents a significant advancement in the field of explainable AI, with the potential to make neural network decisions more interpretable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Interval Abstractions for Robust Counterfactual Explanations
Junqi Jiang, Francesco Leofante, Antonio Rago, Francesca Toni
0
0
Counterfactual Explanations (CEs) have emerged as a major paradigm in explainable AI research, providing recourse recommendations for users affected by the decisions of machine learning models. However, when slight changes occur in the parameters of the underlying model, CEs found by existing methods often become invalid for the updated models. The literature lacks a way to certify deterministic robustness guarantees for CEs under model changes, in that existing methods to improve CEs' robustness are heuristic, and the robustness performances are evaluated empirically using only a limited number of retrained models. To bridge this gap, we propose a novel interval abstraction technique for parametric machine learning models, which allows us to obtain provable robustness guarantees of CEs under the possibly infinite set of plausible model changes $Delta$. We formalise our robustness notion as the $Delta$-robustness for CEs, in both binary and multi-class classification settings. We formulate procedures to verify $Delta$-robustness based on Mixed Integer Linear Programming, using which we further propose two algorithms to generate CEs that are $Delta$-robust. In an extensive empirical study, we demonstrate how our approach can be used in practice by discussing two strategies for determining the appropriate hyperparameter in our method, and we quantitatively benchmark the CEs generated by eleven methods, highlighting the effectiveness of our algorithms in finding robust CEs.
4/23/2024
Probabilistically Plausible Counterfactual Explanations with Normalizing Flows
Patryk Wielopolski, Oleksii Furman, Jerzy Stefanowski, Maciej Zik{e}ba
0
0
We present PPCEF, a novel method for generating probabilistically plausible counterfactual explanations (CFs). PPCEF advances beyond existing methods by combining a probabilistic formulation that leverages the data distribution with the optimization of plausibility within a unified framework. Compared to reference approaches, our method enforces plausibility by directly optimizing the explicit density function without assuming a particular family of parametrized distributions. This ensures CFs are not only valid (i.e., achieve class change) but also align with the underlying data's probability density. For that purpose, our approach leverages normalizing flows as powerful density estimators to capture the complex high-dimensional data distribution. Furthermore, we introduce a novel loss that balances the trade-off between achieving class change and maintaining closeness to the original instance while also incorporating a probabilistic plausibility term. PPCEF's unconstrained formulation allows for efficient gradient-based optimization with batch processing, leading to orders of magnitude faster computation compared to prior methods. Moreover, the unconstrained formulation of PPCEF allows for the seamless integration of future constraints tailored to specific counterfactual properties. Finally, extensive evaluations demonstrate PPCEF's superiority in generating high-quality, probabilistically plausible counterfactual explanations in high-dimensional tabular settings. This makes PPCEF a powerful tool for not only interpreting complex machine learning models but also for improving fairness, accountability, and trust in AI systems.
5/29/2024
Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
Patryk Wielopolski, Oleksii Furman, Jerzy Stefanowski, Maciej Zik{e}ba
0
0
Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of global, and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.
5/29/2024

Counterfactual Explanations for Linear Optimization
Jannis Kurtz, c{S}. .Ilker Birbil, Dick den Hertog
0
0
The concept of counterfactual explanations (CE) has emerged as one of the important concepts to understand the inner workings of complex AI systems. In this paper, we translate the idea of CEs to linear optimization and propose, motivate, and analyze three different types of CEs: strong, weak, and relative. While deriving strong and weak CEs appears to be computationally intractable, we show that calculating relative CEs can be done efficiently. By detecting and exploiting the hidden convex structure of the optimization problem that arises in the latter case, we show that obtaining relative CEs can be done in the same magnitude of time as solving the original linear optimization problem. This is confirmed by an extensive numerical experiment study on the NETLIB library.
5/27/2024