Counterfactual Explanations for Linear Optimization
2405.15431
0
0

Abstract
The concept of counterfactual explanations (CE) has emerged as one of the important concepts to understand the inner workings of complex AI systems. In this paper, we translate the idea of CEs to linear optimization and propose, motivate, and analyze three different types of CEs: strong, weak, and relative. While deriving strong and weak CEs appears to be computationally intractable, we show that calculating relative CEs can be done efficiently. By detecting and exploiting the hidden convex structure of the optimization problem that arises in the latter case, we show that obtaining relative CEs can be done in the same magnitude of time as solving the original linear optimization problem. This is confirmed by an extensive numerical experiment study on the NETLIB library.
Create account to get full access
Overview
- This paper explores the problem of generating counterfactual explanations for linear optimization problems.
- Counterfactual explanations describe how an input could be changed to produce a different output, helping users understand AI model decisions.
- The authors propose a method for producing provably optimal, unique counterfactual explanations for linear optimization problems, which have many real-world applications.
Plain English Explanation
Imagine you're applying for a loan and an AI system denies your application. You want to know what you could have done differently to get approved. This is where counterfactual explanations come in. These explanations show you how you could change certain factors, like your income or credit score, to get a different outcome - in this case, a loan approval.
The researchers in this paper looked at ways to create these types of counterfactual explanations for a specific type of AI model called a linear optimizer. Linear optimizers are used in many real-world situations, like resource allocation, portfolio management, and traffic routing.
The key innovation in this work is that the counterfactual explanations they generate are provably optimal and unique. This means the explanations they provide are the best possible changes you could make to get a different outcome, and there's only one way to make those changes. This is important because it gives users confidence that the explanation they're getting is the most helpful one.
Technical Explanation
The authors formulate the problem of generating counterfactual explanations for linear optimization problems as an optimization task. Given a linear optimization problem and a specific output, they aim to find the input that is nearest to the original input but results in a different optimal output.
To solve this problem, the researchers propose an algorithm that leverages the special structure of linear optimization. By exploiting properties like linear separability and the existence of a unique optimal solution, they are able to derive a closed-form solution for the optimal counterfactual explanation. This solution is provably unique and optimal - there is only one way to minimally change the input to get a different optimal output.
The authors demonstrate the effectiveness of their approach through experiments on synthetic and real-world datasets, showing that their method can efficiently generate high-quality counterfactual explanations for a variety of linear optimization problems. They also discuss the connections between their work and other recent advances in the field of interpretable AI.
Critical Analysis
One key strength of this work is the provable optimality and uniqueness of the counterfactual explanations it produces. This is an important property that gives users confidence in the explanations and ensures they are getting the most helpful information possible. However, the authors acknowledge that their approach is limited to linear optimization problems, and it would be interesting to see if similar guarantees could be extended to more complex models.
Additionally, while the experiments demonstrate the effectiveness of the proposed method, the paper does not delve deeply into the real-world implications and use cases of this technology. It would be helpful to see more discussion of how these counterfactual explanations could be applied and the potential benefits they could bring to users and decision-makers.
Another potential area for further research is the interpretability and understandability of the counterfactual explanations themselves. The paper focuses on the technical properties of the explanations, but it may be valuable to also consider how they can be presented in a way that is intuitive and easy for non-technical users to understand.
Conclusion
This paper presents a novel approach for generating provably optimal and unique counterfactual explanations for linear optimization problems. By leveraging the special structure of linear models, the researchers are able to derive a closed-form solution that guarantees the best possible explanation for a given output.
While the scope of this work is currently limited to linear optimization, the insights and techniques developed here could have broader applications in the field of interpretable AI. As AI systems become more prevalent in high-stakes decision-making processes, tools like these counterfactual explanations will be increasingly important for helping users understand and trust the decisions being made.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Provably Robust and Plausible Counterfactual Explanations for Neural Networks via Robust Optimisation
Junqi Jiang, Jianglin Lan, Francesco Leofante, Antonio Rago, Francesca Toni
0
0
Counterfactual Explanations (CEs) have received increasing interest as a major methodology for explaining neural network classifiers. Usually, CEs for an input-output pair are defined as data points with minimum distance to the input that are classified with a different label than the output. To tackle the established problem that CEs are easily invalidated when model parameters are updated (e.g. retrained), studies have proposed ways to certify the robustness of CEs under model parameter changes bounded by a norm ball. However, existing methods targeting this form of robustness are not sound or complete, and they may generate implausible CEs, i.e., outliers wrt the training dataset. In fact, no existing method simultaneously optimises for closeness and plausibility while preserving robustness guarantees. In this work, we propose Provably RObust and PLAusible Counterfactual Explanations (PROPLACE), a method leveraging on robust optimisation techniques to address the aforementioned limitations in the literature. We formulate an iterative algorithm to compute provably robust CEs and prove its convergence, soundness and completeness. Through a comparative experiment involving six baselines, five of which target robustness, we show that PROPLACE achieves state-of-the-art performances against metrics on three evaluation aspects.
4/5/2024
Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
Patryk Wielopolski, Oleksii Furman, Jerzy Stefanowski, Maciej Zik{e}ba
0
0
Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of global, and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.
5/29/2024
🔮
CF-OPT: Counterfactual Explanations for Structured Prediction
Germain Vivier-Ardisson, Alexandre Forel, Axel Parmentier, Thibaut Vidal
0
0
Optimization layers in deep neural networks have enjoyed a growing popularity in structured learning, improving the state of the art on a variety of applications. Yet, these pipelines lack interpretability since they are made of two opaque layers: a highly non-linear prediction model, such as a deep neural network, and an optimization layer, which is typically a complex black-box solver. Our goal is to improve the transparency of such methods by providing counterfactual explanations. We build upon variational autoencoders a principled way of obtaining counterfactuals: working in the latent space leads to a natural notion of plausibility of explanations. We finally introduce a variant of the classic loss for VAE training that improves their performance in our specific structured context. These provide the foundations of CF-OPT, a first-order optimization algorithm that can find counterfactual explanations for a broad class of structured learning architectures. Our numerical results show that both close and plausible explanations can be obtained for problems from the recent literature.
6/4/2024
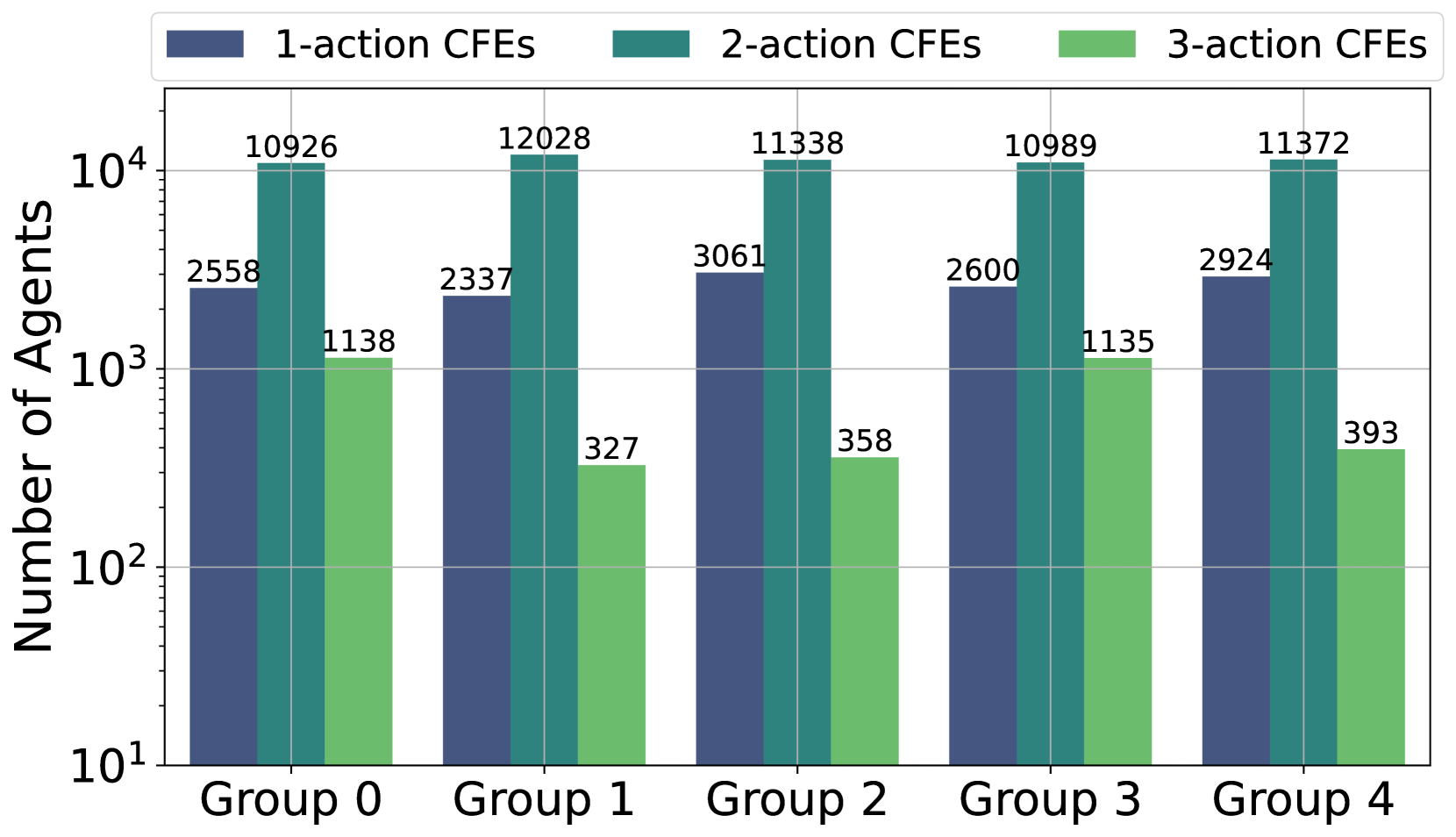
Learning Actionable Counterfactual Explanations in Large State Spaces
Keziah Naggita, Matthew R. Walter, Avrim Blum
0
0
Counterfactual explanations (CFEs) are sets of actions that an agent with a negative classification could take to achieve a (desired) positive classification, for consequential decisions such as loan applications, hiring, admissions, etc. In this work, we consider settings where optimal CFEs correspond to solutions of weighted set cover problems. In particular, there is a collection of actions that agents can perform that each have their own cost and each provide the agent with different sets of capabilities. The agent wants to perform the cheapest subset of actions that together provide all the needed capabilities to achieve a positive classification. Since this is an NP-hard optimization problem, we are interested in the question: can we, from training data (instances of agents and their optimal CFEs) learn a CFE generator that will quickly provide optimal sets of actions for new agents? In this work, we provide a deep-network learning procedure that we show experimentally is able to achieve strong performance at this task. We consider several problem formulations, including formulations in which the underlying capabilities and effects of actions are not explicitly provided, and so there is an informational challenge in addition to the computational challenge. Our problem can also be viewed as one of learning an optimal policy in a family of large but deterministic Markov Decision Processes (MDPs).
4/29/2024